五分鐘帶你搞懂從零打造一個ChatGPT
前言
歐陽上一次寫文章還是4個月前,之所以斷更有兩個原因:換工作和業余時間ALL IN AI了。不管你是否承認,AI時代已經來了,依然埋頭研究前端的那一畝三分地和源碼在未來可能就是蒸汽時代被淘汰的紡織女工。
今年大家多多少少都有接觸到AI相關的項目了,從前端的角度來看以前是調用后端的接口,現在改成了調用大模型提供的接口,本質依然沒變。
但是按照大家卷的程度來看,在未來的不久不管你是前端還是后端,大模型底層原理將會是和源碼一樣成為面試中的熱門話題。所以歐陽打算寫一個關于大模型底層原理系列的文章,包括熱門的Transformer、自注意力機制、深度思考等內容(先挖一個大坑)。
什么是生成式大模型
大家平時接觸的AI基本都是生成式大模型,比如我們熟知的ChatGPT、DeepSeek等。在ChatGPT還沒火之前,判別式模型是最熱門的,也就是國內的科技公司花了大精力去研究的領域,從現在的上帝視角來看只有OpenAI走了正確的路。
判別式模型的作用主要是分類,在我們的生活中到處都是判別式模型的影子,比如:
- 垃圾郵件分類器: 判斷一封郵件是"垃圾郵件"還是"正常郵件"。
- 情感分析: 分析一個商品評價是"積極"、"消極"還是"中性"。
- 人臉識別: 判斷一張臉屬于數據庫中的哪個人。
- 圖像識別: 識別一張圖片中的物體是什么。
判別式模型做的事情只能是一個輔助工具,不能執行一些創造性的任務,比如寫文章、寫代碼等。
但是生成式大模型就能突破判別式模型的天花板,不僅可以做判別式模型能夠做到的所有事情,還能執行一些大家熟知的創造性的任務,比如寫文章、寫代碼等。
生成式大模型的主要特點就是大,這里的大指的是模型的規模。主要體現在兩個方面:參數數量和訓練數據量。
現在的那些大模型基本都是以B為單位,比如DeepSeek R1最小的是2B,最大的是685B。這里的B是指Billion,也就是10億。2B的意思是20億個參數,685B的意思是6850億個參數。
 DeepSeek
DeepSeek
為什么這些大模型的參數數量會這么大呢?
答案是ChatGPT發現當模型的參數數量達到一個臨界點后,模型突然就開悟了一樣,能夠理解人類語言的含義,并且能夠生成符合人類語言習慣的回答,這就是大家常說的模型的涌現能力。量變引起質變,大力出奇跡(手動狗頭)。
在接下來的文章中我們講的大模型都是指生成式大模型,因為判別式模型和生成式大模型比起來完全就是弟弟,人們的注意力現在基本都放在了生成式大模型上。
文字接龍
大模型所做的事情本質就是文字接龍,所以在講如何訓練出一個ChatGPT之前我們來聊聊文字接龍。
 jielong
jielong
人類在做文字接龍的時候會結合自己掌握的知識去思考下一個字應該接什么。
比如,輸入是人工智時,大部分人都會接成能,組合成人工智能這個詞,他的概率是80%(我瞎說的)。當然有人會覺得下一個字應該是障,組合成人工智障這個詞,他的概率是10%。還有一些情況下會接一,組合成人工智能一,這種就是非常少見的情況,所以他的概率是0.01。
如果我們將文字接龍抽象化成一個函數,那么這個函數就是:
function textJieLong(input) {
let arg1, arg2, arg3, arg4, arg5, arg6, arg7, arg8, arg9, arg10,...
if (路人A) {
return'能'
} elseif (路人B) {
return'障'
} elseif (路人C) {
return'一'
} else {
return'...'
}
}
// 輸出:能 概率:80%
// 輸出:障 概率:10%
// 輸出:一 概率:0.01%
// 輸出:.. 概率:...
textJieLong('人工智')這個textJieLong函數就可以被看作是一個大模型,函數的輸出結果就是大模型的輸出結果。
函數中的一系列arg1、arg2等參數就是大模型的參數,我們常說的8B就是說明有80億個參數,也就是有80億個arg參數。
那么模型訓練的作用是干嘛呢?
模型訓練就是我們給textJieLong函數一堆輸入和輸出的數據,然后根據這些輸入和輸出的數據去反推arg1、arg2等參數。
輸入:人工智
輸出:能
輸入:中國的首都是
輸出:北京
輸入:今天天氣適合在家
輸出:打游戲
很多組輸入和輸出...有沒有覺得這個和小學的方程式很像,一堆輸入,一堆輸出,然后求解方程式里面的未知數,這些未知數就是模型的參數。
其實訓練模型的過程就是計算求解這些參數的過程!! 每一次的訓練都會去不斷的更新這些參數,直到模型吐出的結果滿足我們的預期。
訓練模型會經歷哪些階段
訓練一個模型會經歷三個階段,對應下面的這張圖的三個階段:
 three
three
第一張圖為:自我學習,累計實力(預訓練 Pre-training)
第二張圖為:名師指點,發揮潛力(監督微調 SFT)
第三張圖為:參與實戰,打磨技巧(強化學習 RLHF)
這三個階段都是大模型在學習如何進行文字接龍,只是訓練的資料不同。
第一階段:自我學習,累計實力(預訓練 Pre-training)
在講預訓練之前,我們先來聊聊在進行預訓練之前的模型是什么樣的?
一個大模型的結構大概是下面這樣的:
 structure
structure
主要就是很多個transformer堆疊在一起,并且像ChatGPT這種生成式大模型他是僅解碼器模型,沒有編碼器模塊(這段話看不懂就算了,后面單獨有文章講transformer)。
用戶的輸入,也就是transformer模塊的輸入,然后每個transformer模塊會輸出一個結果,然后將上一個transformer模塊的輸出作為下一個transformer模塊的輸入,最后輸出一個結果,這個結果就是大模型的輸出結果。
任何文字資料都可以作為這一階段上面的訓練資料,所以這一階段會大量爬取網絡上面的文本用于模型的訓練。
所以在這一階段會進行大量的數據進行訓練(99%的訓練數據都是在這一階段完成的),當訓練數據的量達到某個臨界點后,模型就能夠理解人類語言的含義(至于為什么模型能夠理解人類語言的含義,目前沒有人能夠說清楚)。
這一階段的訓練肯定能夠訓練出一個大模型嗎?
答案是:不一定。除了訓練模型找出來的參數之外還有一些人工設置的參數,這些參數我們稱之為超參數。這些超參數都是通過人工設置的,在模型訓練過程中也不會改變,比如:
- 模型的層數
- 模型的維度
- 模型的頭數
當在訓練模型時失敗了(沒有找到參數符合訓練資料),就需要手動調整超參數。
在進行預訓練之前,模型的輸出是隨機的。比如你輸入:中國的首都是,模型會輸出:你好吖。明顯輸入和輸出是沒有任何關聯的。
經過預訓練后的模型是基礎模型,這種模型的名字包含一個Base字段。
 base
base
經過預訓練后,模型突然像開竅了一樣能夠理解人類語言的含義。這個時候的模型只會成語接龍,沒有接受人類的調教,所以他不能回答你的問題,他只會拋出更多的問題給你。如圖:
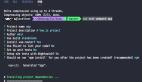
我在colab上面跑的一個千問3的4B Base模型,輸入是:中國的首都是什么?
 base-ask
base-ask
從圖中可以看到此時模型的輸出奇奇怪怪的,他沒有回答我的問題,反而拋出更多的問題。
我又跑了一個千問3的4B模型,同樣輸入是:中國的首都是什么?
 qa
qa
從圖中可以看到同樣都是4B的千問3模型,經過微調后不僅擁有了思考能力(think標簽就是模型思考的過程),并且還能回答我們的問題了。
第二階段:名師指點,發揮潛力(監督微調 SFT)
經過上個階段預訓練pre-training海量的數據訓練后,模型突然就涌現了“智慧”,能夠理解人類語言的含義,但是模型只會成語接龍,不會回答你的問題。
所以在這個階段我們需要訓練模型,讓他能夠學會如何回答你的問題。
在這個階段,我們只需要收集少量但高質量的數據集。這里的少量是和第一階段海量的數據集相比是少量,其實也會覆蓋各種任務的數據集。
在這一階段的目標是把模型打造成一個通才,讓他能夠回答各種問題。
模型微調的數據集主要有兩種格式:Alpaca和ShareGPT
其中Alpaca數據集是下面這樣的:
[
{
"instruction": "人類指令(必填)",
"input": "人類輸入(選填)",
"output": "模型回答(必填)",
"system": "系統提示詞(選填)",
"history": [
["第一輪指令(選填)", "第一輪回答(選填)"],
["第二輪指令(選填)", "第二輪回答(選填)"]
]
}
]ShareGPT數據集是下面這樣的:
{
"conversations": [
{
"from": "human",
"value": "你好,我出生于1990年5月15日。你能告訴我我今天幾歲了嗎?"
},
{
"from": "function_call",
"value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"
},
{
"from": "observation",
"value": "{\"age\": 31}"
},
{
"from": "gpt",
"value": "根據我的計算,你今天31歲了。"
}
],
"tools": "[{\"name\": \"calculate_age\", \"description\": \"根據出生日期計算年齡\", \"parameters\": {\"type\": \"object\", \"properties\": {\"birthdate\": {\"type\": \"string\", \"description\": \"出生日期以YYYY-MM-DD格式表示\"}}, \"required\": [\"birthdate\"]}}]"
}從上面可以看到不管是Alpaca還是ShareGPT本質都是通過問答的形式來訓練模型,在數據集中拋出問題,并且給出問題的答案,告訴模型遇見這樣的問題就應該這樣去回答。
當訓練的數據量達到某個臨界點時,模型突然就開竅了,不光能夠回答我們預設的問題,并且類似的問題也能夠回答,有點像舉一反三的感覺。
前面我們講過這一階段想要將模型訓練成一個通才,那么就需要人工標注的高質量一問一答的數據集。
雖然我們前面說過這一階段所需的數據集比較“少”,但是這里的“少”是和第一階段預訓練相比起來比較少。畢竟第一階段訓練的數據集基本是網絡上面能夠爬取到的所有資料,比起來當然就少了。
并且在這一階段的數據還需要是人工標注的高質量數據集,涉及到人工的東西成本都不低。
OpenAI的做法是將其丟給外包公司來人工標注,這個方法需要鈔能力的。沒有錢怎么辦呢?
答案是:可以對ChatGPT做逆向工程,由ChatGPT來幫我們生成微調數據集的問題和答案。
人為的先給一些「訓練數據樣例」讓 ChatGPT 看,
緊接著利用 ChatGPT 的續寫功能,讓其不斷地舉一反三出新的訓練數據集:
你被要求提供10個多樣化的任務指令。這些任務指令將被提供給GPT模型,我們將評估GPT模型完成指令的能力。
以下是你提供指令需要滿足的要求:
1.盡量不要在每個指令中重復動詞,要最大化指令的多樣性。
2.使用指令的語氣也應該多樣化。例如,將問題與祈使句結合起來。
3.指令類型應該是多樣化的,包括各種類型的任務,類別種類例如:brainstorming,open QA,closed QA,rewrite,extract,generation,classification,chat,summarization。
4.GPT語言模型應該能夠完成這些指令。例如,不要要求助手創建任何視覺或音頻輸出。例如,不要要求助手在下午5點叫醒你或設置提醒,因為它無法執行任何操作。例如,指令不應該和音頻、視頻、圖片、鏈接相關,因為GPT模型無法執行這個操作。
5.指令用中文書寫,指令應該是1到2個句子,允許使用祈使句或問句。
6.你應該給指令生成適當的輸入,輸入字段應包含為指令提供的具體示例,它應該涉及現實數據,不應包含簡單的占位符。輸入應提供充實的內容,使指令具有挑戰性。
7.并非所有指令都需要輸入。例如,當指令詢問一些常識信息,比如“世界上最高的山峰是什么”,不需要提供具體的上下文。在這種情況下,我們只需在輸入字段中放置“<無輸入>”。當輸入需要提供一些文本素材(例如文章,文章鏈接)時,就在輸入部分直接提供一些樣例。當輸入需要提供音頻、圖片、視頻或者鏈接時,則不是滿足要求的指令。
8.輸出應該是針對指令和輸入的恰當回答。
下面是10個任務指令的列表:
###
1. 指令: 在面試中如何回答這個問題?
1. 輸入:當你在車里獨處時,你會想些什么?
1. 輸出:如果是在晚上,我通常會考慮我今天所取得的進步,如果是在早上,我會思考如何做到最好。我也會嘗試練習感恩和活在當下的狀態,以避免分心駕駛。
###
2. 指令: 按人口對這些國家進行排名。
2. 輸入:巴西,中國,美國,日本,加拿大,澳大利亞
2. 輸出:中國,美國,巴西,日本,加拿大,澳大利亞
###
3. 指令:下面是ChatGPT的回答:
 chat-gpt
chat-gpt
從圖中可以看到ChatGPT已經幫我們生成了一系列的問題和答案。
并且可以結合字節seed團隊發布的《Reformulation for Pretraining Data Augmentation》論文生成更多的數據集,論文地址:https://arxiv.org/abs/2502.04235v2
這篇論文的觀點是,我們可以通過同一個問題,不同類型的受眾就可以有不同的答案。
比如一個問題:什么是大模型,根據不同類型的受眾就應該是不同的答案。
這個問題可以映射為:“學術論文-科研人員”、“對話體-老年人”、“教科書-中學生”這三種類型,每種類型都有不同的答案。這樣就可以讓我們的數據集的規模輕松增加3倍。
除此之外還有一些公開的數據集:
- HuggingFace(??):大模型時代的GitHub,上面除了開源模型之外還有很多開源數據集地址:https://huggingface.co/datasets
- Kaggle(??):Kaggle 是一個數據科學平臺,不僅提供大量的公開數據集,還舉辦各種數據科學競賽。其數據集涵蓋了計算機視覺、自然語言處理、數據可視化等多個領域。地址:https://www.kaggle.com/datasets
- Google DataSet Search(??):一個專門用于搜索數據集的搜索引擎,能夠幫助用戶找到互聯網上公開的數據集。地址:https://datasetsearch.research.google.com
- awesome-public-datasets:GitHub 上的 awesome-public-datasets 是一個開源項目,匯集了各種主題的高質量公共數據集(不過已經有段時間沒更新了)。這些數據集按照主題分類,如農業、生物、氣候、計算機網絡、教育、金融等。地址:https://github.com/awesomedata/awesome-public-datasets
- openDataLab:一個專注于中文數據集的平臺,也是中國本土最大的開源數據集平臺,提供了豐富的中文數據集資源。地址:https://opendatalab.com
- ModelScope:ModelScope 是阿里巴巴推出的 AI 模型與數據集中心,除了提供預訓練模型外,還包含與模型相關的數據集。其實有點類似于中國版的 HuggingFace。地址:https://modelscope.cn/datasets
第二階段監督微調 SFT其實就是畫龍點睛。
第三階段:參與實戰,打磨技巧(強化學習 RLHF)
經過第二階段監督微調 SFT后,模型已經能夠回答各種問題了,可以當做一個問答助手使用了。
但是還可以進一步提升其回答質量,這是通過強化學習(RLHF)來實現的。這個過程分為兩個步驟。
- 獎勵模型(Reward Model 簡稱 RM)
- 強化學習(Reinforcement Learning 簡稱 RL)
為什么需要RLHF?
回想第二階段有監督微調SFT,我們只告訴模型什么是好的數據,但是沒有告訴他什么是不好的數據。
我們通過有監督微調SFT引導模型將在第一階段預訓練pre-training學習到的海量知識在合適的問題下面輸出出來。但是因為第二階段的數據集是人工標注而來的,數據很有限,導致我們對模型的引導能力也有限。
這將導致預訓練模型中原先「錯誤」或「有害」的知識沒能在 SFT 數據中被糾正,
從而出現「有害性」或「幻覺」的問題。
所以才需要第三階段強化學習RLHF來解決這些問題,告訴模型什么是好的數據,什么是不好的數據。
我們先來看看什么是獎勵模型RM?
獎勵模型RM是一個單獨訓練的一個模型,這個模型用于給第二階段SFT訓練出來的模型的輸出打分。
注意,這里的打分不是真的打分,本質上排列一個好壞的先后順序。
就像是給作文打分一樣,不同的人打的分都不相同。
但是如果改成根據內容的好壞進行排序就很容易了,比如作文1、作文2、作文3,不同的人排序大概率都相同。
獎勵模型RM本質依然還是給不同的輸出進行好壞的排序,然后根據這些排序利用【分差變化】計算出每一個輸出的得分。
根據第二階段SFT訓練出來的模型根據不同的temperature值生成多個輸出,然后使用獎勵模型RM對這些輸出進行打分。
接著就是強化學習RL,其實就是利用每個輸出的打分反過來影響模型的參數。通過調整參數讓打分較高的輸出出現的概率更大,打分更低的輸出出現的概率更小。
為什么需要獎勵模型RM?
并不是所有人在使用ChatGPT時會對輸出進行“好”或者“壞”的評價,所以需要一個獎勵模型RM來模擬人類的反饋,人類覺得不錯的輸出獎勵模型就會給出高的得分,反之則給出低的得分。
總結
這篇文章我們講了訓練出一個ChatGPT需要經歷三個階段:
- 第一階段:自我學習,累計實力(預訓練 Pre-training)
- 第二階段:名師指點,發揮潛力(監督微調 SFT)
- 第三階段:參與實戰,打磨技巧(強化學習 RLHF)
在第一階段預訓練Pre-training階段,大模型通過網絡上面大量的數據資料進行自我學習(那些參數很大的模型基本都將網絡上面的資料全部學完了),最終在某個臨界點時突然就開竅了理解了人類語言的含義。但是此時模型只會文字接龍,不會回答你的問題。
這一步我理解為量變引起質變,大力出奇跡。
在第二階段需要一個老師來指導大模型應該如何利用第一階段學習的知識回答問題,所以需要一些人工標注的高質量數據集來對大模型進行監督微調SFT,通過這些高質量數據集模型學會了如何回答問題。
這一步我理解為畫龍點睛。
在前面的階段我們只告訴模型什么是好的數據,但是沒有告訴他什么是壞的數據。所以在第三階段我們需要去訓練一個獎勵模型RM來對模型的輸出進行打分,通過打分來影響模型的輸出,讓得分高的輸出出現的概率更大,得分低的輸出出現的概率更小。