剛剛!UCLA楊林團隊證明:僅憑提示詞,Gemini 2.5 Pro就可以拿到IMO2025金牌
最近,大家應該都被OpenAI和谷歌的內部模型獲得IMO2025金牌的消息刷屏了,但是正式參賽的公開的模型03high,Gemini 2.5 pro等表現很差,連銅牌都沒拿到,不過現在又有了一個新情況。
剛剛發布在arXiv上的研究論文《Gemini 2.5 Pro Capable of Winning Gold at IMO 2025*》證明Gemini 2.5 Pro本體通過適當提示就可以獲得IMO 2025金牌。
論文地址:https://arxiv.org/pdf/2507.15855
該論文由加州大學洛杉磯分校的楊林(UCLA 電子與計算機工程系副教授)和黃溢辰撰寫,詳細闡述了他們如何利用谷歌最新的Gemini 2.5 Pro模型,成功解決了6道2025年國際數學奧林匹克(IMO)競賽題目中的5道,達到了IMO金牌得主水平。
核心方法
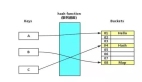
該研究的真正創新之處,在于設計了一套由兩個核心角色解題者和驗證者構成的自我驗證流水線。這兩個角色均由Gemini 2.5 Pro扮演,但通過截然不同且高度特化的提示詞(Prompt)來引導,使其各司其職,形成了高效的協作與迭代機制。
流水線流程如下圖所示:

初始解題:模型首先嘗試對問題進行解答。作者發現,由于IMO問題的復雜性,模型的首次嘗試往往不完美,甚至存在錯誤。
自我改進:模型被提示審視并改進自己的初步解答,相當于進行第一輪反思。
嚴格驗證:引入一個驗證器角色(同樣由Gemini 2.5 Pro扮演)。驗證器會逐行審查解答,生成一份詳細的錯誤報告,將問題分為關鍵錯誤(如邏輯謬誤)和論證缺陷如步驟跳躍、缺乏足夠論證)。
修正與迭代:解題模型根據驗證器提供的錯誤報告來修正自己的證明。修正后的版本會再次提交給驗證器進行審核。
接受或拒絕:這個驗證-修正的循環會持續進行。一個解答只有在連續5次通過驗證器且未發現任何問題后,才會被最終接受。如果一個方案在10輪迭代后仍存在重大問題,則被拒絕。
提示詞設計
解題者提示詞:強調嚴謹與誠實
解題者的目標是生成初步的數學證明。研究者為其設計的提示詞,旨在根除大型語言模型常見的幻覺和走捷徑的弊病。核心指令包括:
嚴謹性至上:提示詞明確要求:你的首要目標是產出完整且嚴格論證的解法。解題的每一步都必須邏輯上無懈可擊且解釋清晰。一個從有缺陷或不完整的推理中得出的正確答案,將被視為失敗。 這條指令將模型的重心從得出答案轉移到了構建嚴謹的證明過程。
對完整性的誠實:這是對抗模型編造內容的關鍵。提示詞指示:如果你找不到完整的解法,你絕不能猜測或創造一個看似正確但包含隱藏缺陷或論證空白的解法。相反,你應該只呈現你能夠嚴格證明的重要部分成果。這使得模型在遇到困難時,會選擇回退到可靠的、已證明的子結論,而不是強行完成整個證明。
結構化輸出:要求模型必須按照摘要和詳細解法的格式輸出。摘要部分又必須包含對解題結果的定論(例如我成功解決了問題或我未能找到完整解法,但我嚴格證明了……),以及一個方法草圖。這種格式強迫模型在輸出最終答案前,進行一次自我評估和梳理。
驗證者提示詞:精細化的錯誤診斷
當解題者完成一次嘗試后,驗證者登場。它的任務不是解題,而是像一位經驗豐富的競賽評委一樣,對證明進行逐行審查。其提示詞設計得更為精妙:
角色定位:你是一位IMO級別的專家數學家和一絲不茍的評分人。你的唯一任務是嚴格驗證所提供的數學解法。
非建設性審查:明確指示你必須扮演驗證者,而非解題者。不要嘗試修正你發現的錯誤或填補空白。這確保了驗證過程的客觀性。
創新的錯誤分類系統:這是整個方法論的點睛之筆。驗證者被要求將發現的問題分為兩類,并按不同規則處理:
a.關鍵錯誤 : 指的是邏輯謬誤或計算錯誤,這類錯誤會直接破壞證明鏈條。一旦發現,驗證者會指出錯誤,并停止對該條推理后續步驟的檢查,但會繼續檢查證明中其他獨立的部分(例如,證明題設的另一種情況)。
b.論證缺陷 :指的是結論可能正確,但論證過程過于簡略、想當然或缺乏足夠嚴謹性。處理這類問題時,驗證者會指出論證的不足,然后假設這一步的結論是正確的,并繼續檢查后續的證明是否在邏輯上成立。這種方法極具價值,因為它能評估即使在某個局部存在瑕疵的情況下,整個證明的宏觀結構是否依然穩固。
我把論文里的提示詞整理了一下,完整提示詞如下:

生成-驗證-修正”閉環
通過這套雙提示詞系統,研究建立了一個迭代循環:
- 解題者根據強調嚴謹和誠實的提示詞生成證明
- 驗證者根據精細化的診斷提示詞,對證明進行審查,并輸出一份結構化的錯誤報告
- 解題者接收這份報告,并針對性地修正自己的證明
- 修正后的版本再次進入驗證環節,如此循環往復,直至證明連續多次通過驗證,沒有任何瑕疵
數據污染?
評估大型語言模型能力時,一個核心挑戰是數據污染——即測試數據可能已存在于模型的訓練集中,導致評估結果虛高。
為了規避這一問題,研究團隊專門使用了剛剛發布的2025年IMO競賽題目進行測試。由于這些題目是在評估前幾天才公布的,可以確保模型此前從未見過它們,從而提供了一個純凈的測試環境,真實地反映了Gemini 2.5 Pro的泛化和原創性解題能力。
另外論文作者的回應,也沒有開啟網絡搜索功能。
結果是否可驗證?
通過上述方法,作者宣稱Gemini 2.5 Pro成功地為IMO 2025的前5道題提供了完整且嚴謹的證明。
問題1(組合數學)和問題2(幾何): 研究人員在使用模型解題時,額外加入了一句提示,分別建議嘗試歸納法和解析幾何。他們認為,這兩種方法是解決此類問題的通用策略,一個先進的多智能體系統本就會分配智能體去探索這些路徑,因此這并不算提供捷徑,而更像是節約計算資源。模型在處理幾何問題時尤其得心應手,被認為是6道題中最簡單的一道。
問題3(數論): 團隊通過20次采樣和迭代改進,成功獲得嚴謹解。這展示了其迭代方法相比于純粹暴力采樣的更高效率。
問題4和問題5 也被成功解決。
問題6: 模型未能解決,只給出了一個平凡的上界。
綜合來看,解決6道題中的5道,結果請看論文,文章中有詳細過程。
解題過程和結果正確性得到了手動驗證。

但是目前這個結果只是他們自我報道,還沒有的到IMO組委會的認可。