自研 DSL 神器:萬字拆解 ANTLR 4 核心原理與高級應用
DSL(領域特定語言) 是一種為解決特定領域的問題而專門設計的計算機語言,它不同于通用編程語言(如 Python、Java)。它通常具有高度定制化的語法和結構,聚焦于某個特定任務或領域(如數據庫查詢、硬件配置、報表生成),通過提供更簡潔、直觀且貼近領域術語的表達方式,大幅提升該領域人員的工作效率和生產力,降低復雜性。
通俗來說,DSL 就像是為某個專業領域量身定做的“行話”工具。
說到構建自定義 DSL,高效且靈活的語法解析至關重要,ANTLR 正是解決這一核心挑戰的利器。
簡介
- 官方地址:https://www.antlr.org/
- GitHub:https://github.com/antlr/antlr4
- 在線調試:http://lab.antlr.org/
- IDEA插件:ANTLR V4
ANTLR 4(ANother Tool for Language Recognition,版本4)是一個開源的解析器生成器工具,用于構建語言識別程序。它能夠根據用戶定義的語法規則,自動生成詞法分析器(Lexer)和語法分析器(Parser),從而實現對結構化文本(如編程語言、配置文件、數據格式等)的解析、轉換或翻譯。
ANTLR 4 最大的核心價值就是降低語言處理的門檻。在ANTRL 4沒有出現之前,語言處理主要依賴正則表達式、手工編寫解析器以及早期的解析器生成工具(如Lex/Yacc)。

ANTLR 4 的使用很簡單,因為其存在的本身的意義就是為了加快語言類應用程序的編寫速度,就是為了非專業人員對語言類應用程序快速開發而生的。
首先我們要進行ANTLR 4元語言的編寫,也就是需要我們根據我們自己的需要來編寫一份語法文件,一份后綴為 .g4 的文件,這份文件是我們構建ANTLR 4語言類應用程序的基礎,目前ANTLR 4已經支持了數十種編程語言的生成,可以滿足不同語言的開發需求。
官方也提供了相關的文件,GitHub:https://github.com/antlr/grammars-v4。
有了這些 Java 文件,語言類應用程序的開發人員就不需要再去思考如何手動編寫解析語法樹的程序,因為ANTLR 4已經幫我們把這些事情都做了,ANTLR 4自帶的jar 包和自動生成的這些語法分析器以及之后所提到的監聽器 Listener 和訪問器 Visitor 都能夠完美的幫我們來處理任何語言類應用程序的自定義需求,從而真正達到即使你沒學過編譯原理也能自己開發應用程序的效果。
ANTLR 是用 Java 編寫的,因此你需要首先安裝 Java,哪怕你的目標是使用 ANTLR 來生成其他語言(如C#和C++)的解析器。
下圖是我使用 IDEA 中的 ANTLR 4 插件,以及我自己編寫的語法,自動生成的語法解析樹,這一切都是ANTLR 4幫我們自動完成的。

簡而言之,ANTLR 工具將語法文件轉換成可以識別該語法文件所描述的語言的程序。例如,給定一個識別 JSON 的語法,ANTLR工具將會根據該語法生成一個程序,此程序可以通過 ANTLR 運行庫來識別輸入的 JSON。
基礎概念
文件聲明
以下是一個包含完整頭部聲明的 ANTLR 4 語法文件示例,涵蓋所有關鍵字的解釋:
// =========== ANTLR4 語法文件頭部聲明示例 ===========
grammar MathParser; // [1] 主聲明
// [2] 導入聲明(組合語法)
import TrigParser, VectorParser; // 導入其他語法模塊
// [3] 選項配置
options {
language = Java; // 目標生成語言
tokenVocab = CoreTokens; // 從外部語法導入詞法符號
superClass = MathBase; // 自定義基類
contextSuperClass = MyCtx; // 自定義上下文基類
}
// [4] 輔助符號聲明
tokens {
// 顯式定義新token
PI = 'π'; // 帶字面量的token
FUNCTION_CALL, // 無字面量的抽象token
VECTOR_DOT_PRODUCT // 用于語法樹節點的標簽
}
// [5] 頭部注入 (生成文件頂部的代碼)
@header {
package com.company.math;
importstatic com.company.math.TrigUtil.*;
}
// [6] 成員注入 (向解析器類添加代碼)
@members {
privateboolean debug = true;
privateint errorCount = 0;
@Override
publicvoidreportError(RecognitionException e){
errorCount++;
super.reportError(e);
}
publicintgetErrorCount(){
return errorCount;
}
}
// [7] 規則定義區
expression: /* 規則內容 */;
// ========================================- grammar:定義語法名稱(必須匹配文件名),聲明完整/詞法/解析語法類型。
- import:導入外部語法文件實現規則復用,支持模塊化開發。語法導入允許你將語法分解成可復用的邏輯單元。ANTLR 處理被導入的語法的方式和面向對象語言中的父類非常相似。一個語法會從其導入的語法中繼承所有的規則、詞法符號聲明和具名的動作。位于“主語法”中的規則將會覆蓋其導入的語法中的規則,以此來實現繼承機制。ANTLR將被導入的規則放置在主語法的詞法規則列表末尾。這意味著,主語法中的詞法規則具有比被導入語法中的規則更高的優先級。
- options:配置代碼生成選項(目標語言/基類/符號表等)。
- tokens:聲明輔助符號(抽象Token/別名/語法樹標簽)。tokens 區域存在的意義在于,它定義了一份語法所需,但卻未在本語法中列出對應規則的詞法符號。大多數情況下,tokens 區域用于定義本語法中動作所需的詞法符號類型。
- @header:向生成文件頂部注入代碼(包聲明/導入語句)。用于將代碼注入生成的識別類中的類聲明之前。用于將代碼注入為識別類的字段和方法。
- @members:向解析器類添加自定義成員(字段/方法/狀態管理)。
關于 @header 和 @members,其中 @header 用于當 ANTLR 4 工具生成詞法分析器和語法分析器時,將 @header 中的內容原封不動的復制到生成的 Java 文件的頂部,而 @members 用于將代碼插入到生成的 Java 類當中,其中可以包含字段聲明,自定義方法等內容。

從圖中我們可以看到我們預先在語法文件中進行了 @header 和 @members 的定義和編寫,然后利用 ANTLR 4 工具自動生成我們所需要的詞法解析器和語法分析器等相關的 Java 文件,后續生成的這些 Java 文件中的相關位置包含了我們在 @header 和 @members 中所定義的相關內容。
不帶前綴的語法聲明是混合語法,可以同時包含詞法規則和語法規則。欲創建一份只允許語法規則出現的文件,使用如下聲明:
parser grammar Name;同理,純詞法的文件如下所示:
lexer grammar Name;詞法規則
詞法文件的規則以大寫字母開頭。
將字符聚集為單詞或者符號(詞法符號,token)的過程稱為詞法分析(lexicalanalysis)或者詞法符號化(tokenizing)。我們把可以將輸入文本轉換為詞法符號的程序稱為詞法分析器(lexer)。詞法分析器可以將相關的詞法符號歸類,例如INT(整數)、ID(標識符)、FLOAT(浮點數)等。當語法分析器不關心單個符號,而僅關心符號的類型時,詞法分析器就需要將詞匯符號歸類。詞法符號包含至少兩部分信息:詞法符號的類型(從而能夠通過類型來識別詞法結構)和該詞法符號對應的文本。

Java 詞法規則示例:

接下來介紹一下詞法規則是如何編寫的。

如上圖所示詞法規則以大寫的字母開頭,或者以冒號開頭后跟大寫字母,這樣做是為了與之后所要介紹的語法規則做區分。例如上圖中我們就給出了一些示例的規則,定義了INT,ID,STRING類型的詞法單元,冒號后面是對這些詞法單元的描述。
這種詞法規則的類型被稱之為標準詞法符號類型,這一類詞法規則必須用大寫字母開頭,經過ANTLR 4工具處理會生成可直接在解析器中引用的符號,其規則匹配的優先級由在語法文件中聲明詞法規則的順序和詞法規則的長度來決定。
其中有很多符號,比如“+”代表著 INTEGER 這一詞法規則使用出現至少一次的自然數組成的,而 IDENTIFIER 這一規則中的“*”則代表著 IDENTIFIER 這一詞法規則是由大小寫字母或下劃線加上至少出現0次的單詞字符組成的。而 STRING 詞法規則中單引號中間的內容則代表著中間的內容直接匹配,是固定的。

第二類詞法規則被稱之為片段規則,通過關鍵字 fragment 來定義。
片段規則具有以下特點:首先片段規則是不能獨立匹配的,fragment 規則不能直接用于匹配輸入文本。它們只能被其他非片段的詞法規則所引用。
將一條規則聲明為 fragment 可以告訴 ANTLR,該規則本身不是一個詞法符號,它只會被其他的詞法規則使用。這意味著我們不能在文法規則中引用 HEX_DIGIT。
通常使用片段規則是為了提高可讀性和重用性,通過將常用的字符模式提取為片段規則,可以使詞法規則更加簡潔和易于維護。例如,可以將字母或數字的模式定義為片段規則,然后在多個詞法規則中引用它們。

第三類詞法規則被稱之為指令規則。
- 第一種被稱之為跳過指令,ANTLR 4在詞法分析過程中會忽略這些匹配的空白字符,不會將它們作為(token)傳遞給語法分析器;
- 第二種被稱之為通道指令,使用 -> channel(HIDDEN) 指令,ANTLR 將這些注釋標記發送到一個隱藏通道,使得它們不會被默認的語法分析器處理,但仍然可以在需要時訪問;
- 第三種被稱之為模式指令,使用 -> pushMode(XML_MODE) 指令,ANTLR 會切換到 XML_MODE 模式,這允許在不同的上下文中使用不同的詞法規則集;
- 最后一種被稱之為類型指令,使用 -> type(DOLLAR_SIGN) 指令,ANTLR 會將匹配的標記類型動態設置為 DOLLAR_SIGN,這可以用于在語法分析中對不同類型的標記進行區分和處理。
語法規則
語法文件的規則以小寫字母開頭。
首先我們來介紹語法規則的規則組成元素。

以上名為 assignment 的語法規則中所包含的大寫字母序列 IDENTIFIER 被稱之終結符,它來自詞法分析器,我們在詞法規則中會對其進行定義。

與此相對的是非終結符,比如以上 expression 語法規則中的 term,這些非終結符,由小寫字母命名,并且由其他規則所定義。

除了之前介紹的終結符和非終結符兩種元素之外,還有帶參數的規則和帶返回值的規則。因此,參數和返回值也是語法規則的重要元素。
[String className],表示這個規則接受一個參數 className,類型為 String。在解析過程中,可以將外部傳入的類名用于匹配。[Object value],表示這個規則在匹配成功后會返回一個 Object 類型的值,存儲在 value 中。
ANTLR 4的語法規則的核心語法構造分為四種模式,分別是序列模式、選擇模式、分組模式、循環模式。
序列模式
sqlSelect : SELECT column FROM table WHERE condition;元素必須嚴格按順序出現(如 SQL 語句結構)。
選擇模式
dataType : INT | STRING | BOOL;多選一匹配(如數據類型只能為三者之一)。
分組模式
functionCall : ID '(' (arg (',' arg)*)? ')';括號強制組合子規則(如函數參數列表的逗號分隔結構)。
循環模式
emailList : address (',' address)+;
后綴運算符控制重復次數(如至少一個郵箱地址的逗號分隔列表)。
規則標簽
在 ANTLR 4 中,規則標簽(Rule Labels)是提升語法可讀性、精確控制解析樹生成的關鍵機制,我們可以使用 # 給最外層的備選分支添加標簽,以獲得更加精確的語法分析器監聽器事件。一條規則中的備選分支要么全部帶上標簽,要么全部不帶標簽。標簽主要有兩種應用形式:
分支備選標簽(Alternative Labels)
在規則的選擇分支(|)中標注備選項:
expression
: left=expr '+' right=expr # AddExpr // # 定義標簽
| left=expr '*' right=expr # MulExpr
| NUMBER # NumLiteral
;作用:
為每個分支生成獨立的上下文類(如
AddExprContext),在監聽器/訪問器中提供類型精確的訪問方法
生成代碼優勢:
// 自動生成精確的進入/退出方法
@Override
public void enterAddExpr(MyParser.AddExprContext ctx) {
// 直接訪問帶標簽的元素
ExprContext left = ctx.left; // 無需遍歷子節點
ExprContext right = ctx.right;
}元素標簽(Element Labels)
在規則中標記特定子元素:
funcCall : func=ID '(' args+=expr (',' args+=expr)* ')';三種標記方式:
標簽語法 | 適用對象 | 返回值類型 | 訪問示例 |
| 詞法符號 |
|
|
| 規則引用 |
子類 |
|
| 重復元素 |
|
|
實戰應用場景
- 場景1:四則運算精確解析
expr
: left=expr op=('*'|'/') right=expr # MulDiv
| left=expr op=('+'|'-') right=expr # AddSub
| NUM # Number
| '(' expr ')' # Parens
;生成的監聽器接口:
voidenterMulDiv(ExprParser.MulDivContext ctx);
voidenterAddSub(ExprParser.AddSubContext ctx);
voidexitMulDiv(ExprParser.MulDivContext ctx);
// ...- 場景2:函數調用語義分析
functionCall
: func=ID '('
(firstArg=expr (',' otherArgs+=expr)*)?
')' # FuncCall
;在訪問器中直接獲取元素:
public Object visitFuncCall(FuncCallContext ctx){
String funcName = ctx.func.getText();
List<ExprContext> args = new ArrayList<>();
if(ctx.firstArg != null) {
args.add(ctx.firstArg);
args.addAll(ctx.otherArgs);
}
// ...處理函數調用
}TokenStream
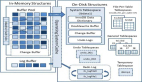
詞法分析器處理字符序列并將生成的詞法符號提供給語法分析器,語法分析器隨即根據這些信息來檢查語法的正確性并建造出一棵語法分析樹。這個過程對應的ANTLR 類是 CharStream、Lexer、Token、Parser,以及 ParseTree。連接詞法分析器和語法分析器的“管道”就是 TokenStream。下圖展示了這些類型的對象在內存中的交互方式。

ParseTree 的子類 RuleNode 和 TerminalNode ,二者分別是子樹的根節點和葉子節點。RuleNode 有一些令人熟悉的方法,例如 getChild() 和 getParent() ,但是,對于一個特定的語法,RuleNode 并不是確定不變的。為了更好地支持對特定節點的元素的訪問,ANTLR 會為每條規則生成一個 RuleNode 的子類。如下圖所示,在我們的賦值語句的例子中,子樹根節點的類型實際上是:StatContext、AssignContext 以及 ExprContext。

因為這些根節點包含了使用規則識別詞組過程中的全部信息,它們被稱為上下文(context)對象。每個上下文對象都知道自己識別出的詞組中,開始和結束位置處的詞法符號,同時提供訪問該詞組全部元素的途徑。例如,AssignContext 類提供了方法 ID() 和方法 expr() 來訪問標識符節點和代表表達式的子樹。
監聽器和訪問器
ANTLR 的運行庫提供了兩種遍歷樹的機制。默認情況下,ANTLR 使用內建的遍歷器訪問生成的語法分析樹,并為每個遍歷時可能觸發的事件生成一個語法分析樹監聽器接口(parse-tree listener interface)。監聽器非常類似于 XML 解析器生成的 SAX 文檔對象。SAX 監聽器接收類似 startDocument() 和 endDocument() 的事件通知。一個監聽器的方法實際上就是回調函數,正如我們在圖形界面程序中響應復選框點擊事件一樣。除了監聽器的方式,我們還將介紹另外一種遍歷語法分析樹的方式:訪問者模式(vistor pattern)。
監聽器
為了將遍歷樹時觸發的事件轉化為監聽器的調用,ANTLR 運行庫提供了 ParseTreeWalker 類。我們可以自行實現 ParseTreeListener 接口,在其中填充自己的邏輯代碼(通常是調用程序的其他部分),從而構建出我們自己的語言類應用程序。ANTLR 為每個語法文件生成一個 ParseTreeListener 的子類,在該類中,語法中的每條規則都有對應的 enter 方法和 exit 方法。例如,當遍歷器訪問到 assign 規則對應的節點時,它就會調用 enterAssign() 方法,然后將對應的語法分析樹節點——AssignContext 的實例——當作參數傳遞給它。在遍歷器訪問了 assign 節點的全部子節點之后,它會調用 exitAssign() 。下圖用粗虛線標識了 ParseTreeWalker對語法分析樹進行深度優先遍歷的過程。

下圖顯示了在我們的賦值語句生成的語法分析樹中,ParseTreeWalker 對監聽器方法的完整的調用順序。

監聽器機制的優秀之處在于,這一切都是自動進行的。我們不需要編寫對語法分析樹的遍歷代碼,也不需要讓我們的監聽器顯式地訪問子節點。
訪問器
有時候,我們希望控制遍歷語法分析樹的過程,通過顯式的方法調用來訪問子節點。下圖是是使用常見的訪問者模式對我們的語法分析樹進行操作的過程。

其中,粗虛線顯示了對語法分析樹進行深度優先遍歷的過程。細虛線標示出訪問器方法的調用順序。我們可以在自己的程序代碼中實現這個訪問器接口,然后調用visit() 方法來開始對語法分析樹的一次遍歷。
ParseTree tree=...; // tree是語法分析得到的結果
MyVisitor v = new MyVisitor();
v.visit(tree);ANTLR 內部為訪問者模式提供的支持代碼會在根節點處調用 visitStat() 方法。接下來,visitStat() 方法的實現將會調用 visit() 方法,并將所有子節點當作參數傳遞給它,從而繼續遍歷的過程。或者,visitMethod() 方法可以顯式調用 visitAssign() 方法等。ANTLR會提供訪問器接口和一個默認實現類,免去我們一切都要自行實現的麻煩。這樣,我們就可以專注于那些我們感興趣的方法,而無須覆蓋接口中的方法。
同時訪問者機制支持泛型返回值,可以實現數據聚合。

訪問器機制和監聽器機制的最大的區別在于,監聽器的方法會被 ANTLR 提供的遍歷器對象自動調用,而在訪問器的方法中,必須顯式調用 visit 方法來訪問子節點。忘記調用visit() 的后果就是對應的子樹將不會被訪問。
語義判定
語義判定(Semantic Predicates)允許在語法規則中嵌入布爾表達式,從而在運行時動態控制解析過程。這使得 ANTLR4 能夠處理上下文相關的語法結構。
基本語法:
ruleName
: {布爾表達式}? 規則元素 // 驗證型判定
| {布爾表達式}?=> 規則元素 // 門控型判定
;判定類型
驗證型判定
- 語法:
{布爾表達式}? - 行為:
嘗試匹配規則元素
如果匹配成功,評估布爾表達式
如果表達式為 false,放棄當前分支并嘗試其他備選分支
expr
: {isType("int")}? ID // 只有當 isType("int") 為 true 時才匹配
| INT
;門控型判定
- 語法:
{布爾表達式}?=> - 行為:
在嘗試匹配規則元素前評估布爾表達式
如果表達式為 false,立即放棄整個分支
不會嘗試匹配規則元素
statement
: {inLoop()}?=> 'break'';' // 只有在循環中才允許 break
| 'continue'';'
;實現機制
在語法文件中聲明:
grammar ContextSensitive;
@parser::members {
private SymbolTable symbolTable = new SymbolTable();
privatebooleanisType(String id){
return symbolTable.isType(id);
}
}
expr
: {isType($ID.text)}? ID // 使用語義判定
| INT
;ANTLR 會將語義判定轉換為解析器代碼:
publicclassContextSensitiveParserextendsParser{
// ...
publicfinal ExprContext expr(){
// 嘗試第一個備選分支
if (isType(input.LT(1).getText())) {
// 創建上下文對象
// 匹配 ID
}
// 否則嘗試第二個分支
else {
// 匹配 INT
}
}
}Channel
在 ANTLR 4 中,通道(channels)是一種強大的機制,用于將詞法標記(tokens)分類處理。ANTLR 4 有兩個預定義通道:
- 默認通道 (Token.DEFAULT_CHANNEL),通道號: 0,包含所有需要被解析器處理的標記。
- 隱藏通道 (Token.HIDDEN_CHANNEL),通道號: 1,包含所有不需要被解析器直接處理的標記。
通道與 skip 的區別

自定義通道
// ===== 1. 聲明通道 =====
channels {
ERROR_CHANNEL, // 自定義錯誤信息通道
HIDDEN_COMMENTS // 隱藏注釋通道
}
// ===== 2. 將詞法規則定向到通道 =====
ERROR_TOKEN : '<!' .*? '!>' -> channel(ERROR_CHANNEL); // 捕獲錯誤標記
LINE_COMMENT : '//' ~[\r\n]* -> channel(HIDDEN_COMMENTS); // 隱藏注釋
BLOCK_COMMENT : '/*' .*? '*/' -> channel(HIDDEN_COMMENTS);
// ===== 3. 保留傳統空白符處理 =====
WS : [ \t\r\n]+ -> skip; // 完全跳過空白符ANTLR 4 通過 channels{} 聲明自定義通道,并用 -> channel(NAME) 將詞法規則輸出定向到指定通道,保留但隔離特殊內容。
嵌入動作
ANTLR 的嵌入動作(Embedded Actions)是在語法規則中直接插入目標語言代碼的機制,它允許開發者在解析過程的關鍵節點執行自定義邏輯。
語法規則 { 代碼塊 }ANTLR 在解析時會在對應位置實時執行這些代碼
執行時機
- 元素匹配前:
{代碼} 規則元素 - 元素匹配后:
規則元素 {代碼} - 規則匹配完成:
規則元素 @after {代碼}
動作類型與代碼示例
- 簡單打印動作(調試追蹤)
expression
: left=expression '+' { System.out.println("檢測到加號"); }
right=expression
{ System.out.println("完成加法: "+$left.value+"+"+$right.value); }
;輸出示例:
檢測到加號
完成加法: 5+3- 條件攔截動作(語義檢查)
vectorOperation
: ID '=' (vec1=vector '×' vec2=vector
{
if($vec1.dimension != $vec2.dimension)
throw new RuntimeException("維度不匹配");
})
{ System.out.println("叉積運算完成"); }
;- 動態計算動作(屬性傳遞)
number returns [int value]
: digits=INT { $value = Integer.parseInt($digits.text); }
| hex='0x' hexDigits=HEX
{ $value = Integer.parseInt($hexDigits.text,16); }
;- 集合構造動作(數據聚合)
jsonArray returns [List<Object> list = new ArrayList<>()]
: '['
(first=jsonValue { $list.add(first); }
(',' next=jsonValue { $list.add(next); })*
)? ']'
;- 符號表管理動作(語義分析)
variableDecl
: type ID
{
Symbol sym = new Symbol($ID.text, $type.text);
currentScope.addSymbol(sym);
}
'=' expr ';'
;- 自動代碼生成(DSL編譯)
sqlSelect
: 'SELECT' columns+=column (',' columns+=column)*
{ out.write("SELECT " + $columns.get(0).text);
for(int i=1; i<$columns.size(); i++) {
out.write("," + $columns.get(i).text);
}
}
'FROM' table=ID
{ out.write(" FROM " + $table.text); }
;注意:動作會使語法與目標語言耦合,優先使用監聽器/訪問器模式,避免過度使用。
處理優先級、左遞歸和結合性
在自頂向下的語法和手工編寫的遞歸下降語法分析器中,處理表達式都是一件相當棘手的事情,這首先是因為大多數語法都存在歧義,其次是因為大多數語言的規范使用了一種特殊的遞歸方式,稱為左遞歸(left recursion)。
自頂向下的語法和語法分析器的經典形式無法處理左遞歸。為了闡明這個問題,假設有一種簡單的算術表達式語言,它包含乘法和加法運算符,以及整數因子。表達式是自相似的,所以,很自然地,我們說,一個乘法表達式是由*連接的兩個子表達式,一個加法表達式是由+連接的兩個子表達式。另外單個整數也可以作為簡單的表達式。這樣寫出的就是下列看上去非常合理的規則:

問題在于,對于某些輸入文本而言,上面的規則存在歧義。換句話說,這條規則可以用不止一種方式匹配某種輸入的字符流,這個語法在簡單的整數表達式和單運算符表達式上工作得很好——例如1+2和1*2——是因為只存在一種方式去匹配它們。對于1+2,上述語法只能用第二個備選分支去匹配,如下圖左側的語法分析樹所示。

但是對于 1+2*3 這樣的輸入而言,上述規則能夠用兩種方式解釋它,如上圖中間和右側的語法分析樹所示。它們的差異在于,中間的語法分析樹表示將1加到2和3相乘的結果上去,而右側的語法分析樹表示將1和2相加的結果與3相乘。這就是運算符優先級帶來的問題,傳統的語法無法指定優先級。大多數語法工具,例如Bison,使用額外的標記來指定運算符優先級。
與之不同的是,ANTLR 通過優先選擇位置靠前的備選分支來解決歧義問題,這隱式地允許我們指定運算符優先級。例如,expr 規則中,乘法規則在加法規則之前,所以ANTLR在解決歧義問題時會優先處理乘法。默認情況下,ANTLR按照我們通常對*和+的理解,將運算符從左向右地進行結合。盡管如此,一些運算符——例指數運算符——是從右向左結合的,所以我們需要在這樣的運算符上使用 assoc 選項手工指定結合性。這樣,輸入的 2^3^4 就能夠被正確解釋為2^(3^4):

注:在ANTLR 4.2之后,<assoc=right> 需要被放到備選分支的最左側,否則會收到警告。在本例中,正確寫法是:

如下圖所示的語法分析樹展示了^符號的左結合版本和右結合版本在處理相同輸入時的差異。通常人們采用右側語法分析樹所代表的解釋方式,不過,語言設計者可以自由地決定使用哪一種結合性。

若要將上述三種運算符組合成為同一條規則,我們就必須把^放在最前面,因為它的優先級比*和+都要高(1+2^3的結果是9)。

ANTLR 4的一項重大改進就是,它已經可以處理直接左遞歸了。左遞歸規則是這樣的一種規則:在某個備選分支的最左側以直接或者間接方式調用了自身。上面的例子中的expr規則是直接左遞歸的,因為除INT之外的所有備選分支都以expr規則本身開頭(它同時也是右遞歸(rightrecursive)的,因為它的某些備選分支在最右側引用了expr)。雖然ANTLR 4已經能夠處理直接左遞歸,但是它還無法處理間接左遞歸。這意味著我們無法將expr規則分解為下列規則,盡管它們在語義上等價:

非貪婪匹配
在 ANTLR 中,非貪婪匹配(Non-Greedy Matching) 是處理文本模式的特殊策略,它會盡可能少地匹配字符(即采用"最小匹配"原則)。這與默認的貪婪匹配(盡可能多匹配)形成對比,是解決詞法歧義的關鍵技術。
貪婪匹配(默認行為)
STRING : '"' .* '"'; // 匹配從第一個"到最后一個"非貪婪匹配
STRING_LAZY : '"' .*? '"'; // ? 啟用非貪婪通配符模式說明:
模式 | 符號 | 匹配策略 |
貪婪 |
| 最長可能匹配 |
非貪婪 |
| 最短可能匹配 |
實戰應用場景
- 場景1:注釋匹配
// 錯誤:貪婪匹配會吃光所有內容
DOC_COMMENT : '/*' .* '*/';
// 正確:非貪婪只匹配最近的一對
DOC_COMMENT_LAZY : '/*' .*? '*/';- 場景2:模板字符串
TEMPLATE : '`' ('\\`' | .)*? '`';正確處理帶轉義符的模板:
- 場景3:XML標簽內聯
TAG_CONTENT : '<' .*? '>';輔助類
ParseTreeProperty
ParseTreeProperty 是 ANTLR 4 中一個強大的輔助類,用于將自定義數據與解析樹(Parse Tree)中的節點關聯起來。它是實現屬性文法(Attribute Grammar)的核心工具,特別適用于需要在語法分析過程中計算和傳遞屬性的場景。
ParseTreeProperty 主要用于解決以下問題:
- 存儲節點相關數據:為每個解析樹節點關聯自定義屬性
- 實現屬性傳遞:在樹遍歷過程中收集和傳遞上下文信息
- 實現代碼生成:保存每個節點的代碼生成結果
- 類型檢查:記錄表達式的類型信息
- 符號表關聯:將作用域和符號表與語法結構關聯
/ 1. 創建數據容器
ParseTreeProperty<DataType> dataMap = new ParseTreeProperty<>();
// 2. 向節點注入數據(通常在監聽器/訪問器中)
@Override
publicvoidexitAddExpr(CalcParser.AddExprContext ctx){
int left = dataMap.get(ctx.left); // 取左子樹數據
int right = dataMap.get(ctx.right);
int result = left + right;
dataMap.put(ctx, result); // 當前節點存儲計算結果
}
// 3. 從根節點獲取最終結果
publicintgetResult(ParseTree tree){
return dataMap.get(tree); // 返回根節點存儲的計算結果
}TokenStreamRewriter
TokenStreamRewriter 是 ANTLR4 中一個強大的工具類,用于在不修改原始令牌流的情況下,對令牌流進行非破壞性編輯。它特別適用于源代碼轉換、重構和代碼生成等場景。
其中的關鍵之處在于,TokenStreamRewriter 對象實際上修改的是詞法符號流的“視圖”而非詞法符號流本身。它認為所有對修改方法的調用都只是一個“指令”,然后將這些修改放入一個隊列;在未來詞法符號流被重新渲染為文本時,這些修改才會被執行。在每次我們調用 getText() 的時候,rewriter 對象都會執行上述隊列中的指令。
簡單使用示例:在方法調用前插入日志
publicclassRewriterExample{
publicstaticvoidmain(String[] args){
// 1. 創建輸入流
String input = "public class Test {\n" +
" public void method() {\n" +
" System.out.println(\"Hello\");\n" +
" }\n" +
"}";
CharStream charStream = CharStreams.fromString(input);
// 2. 創建詞法分析器和令牌流
JavaLexer lexer = new JavaLexer(charStream);
CommonTokenStream tokens = new CommonTokenStream(lexer);
// 3. 創建重寫器
TokenStreamRewriter rewriter = new TokenStreamRewriter(tokens);
// 4. 創建解析器
JavaParser parser = new JavaParser(tokens);
ParseTree tree = parser.compilationUnit();
// 5. 遍歷解析樹并修改
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new InsertLogListener(rewriter), tree);
// 6. 獲取修改后的文本
System.out.println(rewriter.getText());
}
staticclassInsertLogListenerextendsJavaBaseListener{
privatefinal TokenStreamRewriter rewriter;
publicInsertLogListener(TokenStreamRewriter rewriter){
this.rewriter = rewriter;
}
@Override
publicvoidenterMethodCall(JavaParser.MethodCallContext ctx){
// 獲取方法名令牌
Token methodNameToken = ctx.Identifier().getSymbol();
// 在方法調用前插入日志語句
String logStmt = "\n System.out.println(\"Calling method: " +
methodNameToken.getText() + "\");";
rewriter.insertBefore(methodNameToken.getTokenIndex(), logStmt);
}
}
}輸出結果:
publicclassTest{
publicvoidmethod(){
System.out.println("Calling method: println");
System.out.println("Hello");
}
}錯誤報告與恢復
ANTLR 的錯誤報告與恢復機制是其生成健壯解析器的核心,它通過智能的錯誤檢測、精確報告及自動恢復策略,確保即使面對非法輸入也能進行結構化處理而非直接崩潰。
對于詞法錯誤和語法錯誤,ANTLR 4 會定位錯誤的起始位置,向后刪除字符直到發現合法的 token 邊界,然后就會接著解析后續輸入。
// 自動生成詳細的錯誤診斷
line 5:8 missing '}' at '{'
line 10:22 mismatched input ';' expecting ','- 信息結構:
位置: 行號:列號
類型: [missing|mismatched|extraneous]
詳情: 期望內容/實際內容自定義錯誤處理器
重寫 BaseErrorListener:
publicclassVerboseListenerextendsBaseErrorListener{
@Override
publicvoidsyntaxError(Recognizer<?,?> recognizer,
Object offendingSymbol,
int line, int charPos,
String msg, RecognitionException e){
// 生成更友好的錯誤提示
String error = String.format("[CUSTOM] Line %d:%d - %s", line, charPos, msg);
System.err.println(error);
}
}
// 注冊自定義監聽器
parser.removeErrorListeners();
parser.addErrorListener(new VerboseListener());性能優化
提高語法分析器的速度
ANTLR 4 的自適應語法分析策略功能比 ANTLR 3 更加強大,不過這是以少量的性能損失為代價的。如果你需要盡可能快的速度和盡可能少的內存占用,你可以使用兩步語法分析策略。第一步使用功能稍弱的語法分析策略——SLL——在大多數情況下它已經足夠了(它和ANTLR 3的策略相似,只是不需要回溯)。如果第一步的語法分析失敗,那么就必須使用全功能的 LL 語法分析。這是因為,在第一步失敗后,我們無法知道原因究竟是真正的語法錯誤,還是 SLL 的功能不夠強大
由于能夠通過 SLL 的輸入一定能夠通過全功能的 LL,所以一旦第一步成功,就無須使用更昂貴的策略。
try {
parser.compilationUnit();
//如果抵達此處,證明沒有語法錯誤,SLL(*)就夠了
//無需使用全功能的LL(*)
} catch (RuntimeException ex) {
if (ex.getClass() == RuntimeException.class &&
ex.getCause() instanceofRecognitionException) {
//BailErrorStrategy會將RecognitionExceptions封裝在
// RuntimeException中,所以這里需要檢查是不是
//一個真正的RecognitionException
tokenStream.reset();//回滾輸入流
//重新使用標準的錯誤監聽器和錯誤處理器
parser.addErrorListener(ConsoleErrorListener.INSTANCE);
parser.setErrorHandler(new DefaultErrorStrategy());
parser.getInterpreter().setPredictionMode(PredictionMode.SLL);
parser.compilationUnit();
parser.addErrorListener(new SyntaxErrorListener());
ParseTree tree = parser.compilationUnit();
// 使用訪問器轉換DSL
Map<String, Object> externalVarMaps = new HashMap<>();
externalVarMaps.put("features", Sets.newHashSet("test_tz_string_auto_test", "test_feature_999", "sys_attr5"));
ParentVisitor visitor = new ParentVisitor(123L, tokenStream, parser, externalVarMaps);
String dsl = visitor.visit(tree);
log.info("Generated DSL:\n{}", dsl);
}
}如果第二步失敗,那就意味著一個真正的語法錯誤。
無緩沖的字符流和詞法符號流
因為 ANTLR 的識別器在默認情況下會將輸入的完整字符流和全部詞法符號放入緩沖區,所以它無法處理大小超過內存的文件,也無法處理類似套接字(socket)連接之類的無限輸入流。為解決此問題,你可以使用字符流和詞法符號流的無緩沖版本:UnbufferedCharStream 和 UnbufferedTokenStream,它們使用一個滑動窗口來處理流。
為展示二者的實際應用,下圖是一個 CSV語法,它計算一個文件中兩列浮點數的和:

如果你需要的只是每一列的和,你就應該在內存中只保留一個或兩個詞法符號用于記錄結果。欲關閉 ANTLR 的緩沖功能,需要完成三件事情。首先,使用無緩沖的流代替常見的 ANTLFileStream 和 CommonTokenStream。其次,傳給詞法分析器一個詞法符號工廠,將輸入流中的字符拷貝到生成的詞法符號中去。否則,詞法符號的 getTex() 方法就會嘗試訪問可能已經不再可用的字符流。最后,阻止語法分析器建立語法分析樹。如下圖標記的關鍵代碼:

當效率是首要目標時,無緩沖流是非常有用的。使用它們的缺點是你需要手工處理與緩沖區相關的事情。例如,你不能在規則的內嵌動作中使用 $text,因為它們是從輸入流中獲取文本的。
結尾
這篇關于 ANTLR 的技術指南到此告一段落。作為領域特定語言(DSL)構建的利器,ANTLR 通過其強大的語法解析能力、靈活的監聽器/訪問器機制,以及高效的錯誤恢復策略,徹底革新了語言處理技術的開發范式。
無論是設計數據庫查詢語言、配置文件解析器,還是實現復雜的領域專用邏輯,ANTLR 都提供了從詞法分析到語法樹遍歷的全套解決方案。其自動生成的解析器代碼和直觀的規則定義方式,讓開發者能專注于業務邏輯而非底層細節,真正實現了"用語法驅動開發"的高效實踐。通過掌握 ANTLR,你已擁有了一把打開自定義語言世界的鑰匙。