Kubernetes 在 AI Native 時代的挑戰與轉型
背景
隨著 AI 技術的爆發式發展,基礎設施被提出了前所未有的高要求。Kubernetes 作為 Cloud Native(云原生)時代的事實標準,在 AI Native 時代正面臨全新的挑戰:更高級的算力調度、異構資源管理、數據安全與合規,以及更加自動化和智能化的運維等。傳統的云原生實踐已無法完全滿足 AI 工作負載的需求,Kubernetes 若想保持自身的相關性,就必須與時俱進地演化。這對于已經走過近十年發展的 Kubernetes 來說是一個重要命題——筆者自 2015 年 Kubernetes 開源伊始就開始關注并在社區布道 Kubernetes,轉眼間它已經成為基礎設施領域的“常青樹”,如今在 AI 浪潮下是時候重新審視它的角色與前景了。
Kubernetes 在 AI Native 時代的角色正在發生轉變。從前它是微服務時代的明星,被譽為“云端的操作系統”,負責在多樣環境中可靠地編排容器化工作負載。但 AI 原生的工作負載(尤其是生成式 AI 時代之后)有著本質的不同,可能讓 Kubernetes 退居幕后成為“隱形的基礎設施”——重要但不再是顯性創新發生的舞臺。具體而言,大型 AI 模型的訓練和托管常常發生在超大規模云廠商(Hyperscaler)的專有基礎設施上,很少離開那些深度集成的環境;模型推理服務則越來越多地通過 API 形式對外提供,而不是作為傳統應用容器部署。此外,訓練任務的調度對 GPU 感知、高吞吐的需求遠超以往,往往需要借助 Kubernetes 之外的專門框架來實現。因此,AI Native 軟件棧的分層方式也與云原生時代有所不同:在新的架構中,最上層是 AI Agent 和 AI 應用,其下是上下文數據管道和向量數據庫等數據層,再下層是模型及其推理 API 接口,底層則是加速計算基礎設施。在這樣分層的體系中,如果不做出改變,Kubernetes 可能淪為背后的“底層支撐”——依然重要,但不再是創新的前臺舞臺。
Kubernetes 在 AI Native 時代的挑戰
Run:ai 是 NVIDIA 提供的一款 Kubernetes 原生 GPU 編排與優化平臺,專為 AI 工作負載設計。它通過智能調度、動態分配與“GPU 分片”(fractional GPU)功能,極大提升 GPU 利用率;支持跨本地、云端與混合場景的統一管理,并可通過 API、CLI、UI 與 Kubeflow、Ray、ML-tools 等主流 AI 工具鏈無縫集成。詳見 NVIDIA 網站。
即使在 AI 時代,Kubernetes 仍不可或缺,尤其在混合部署(本地數據中心 + 云)、統一運維以及 AI 與傳統應用混合工作負載等場景下,Kubernetes 依然是理想的控制平面。然而,要避免退居幕后,Kubernetes 必須正視并解決 AI 工作負載帶來的特殊挑戰,包括:
1. 高級 GPU 調度:提供對 GPU 等加速硬件的感知調度能力,匹配或集成諸如 Run:ai 之類框架的功能。AI 模型訓練常涉及大量 GPU 任務調度,Kubernetes 需要更智能地分配這些昂貴資源,以提高利用率。
2. 深度 AI 框架集成:與分布式 AI 計算框架深度融合,確保在 Kubernetes 上無縫編排像 Ray、PyTorch 等分布式訓練/推理作業。這意味著 Kubernetes 應該為這些框架提供原生支持或接口,使其可以借助 Kubernetes 的調度和編排能力,同時滿足高速通信和跨節點協同的需求。
3. 優化數據管道處理:支持低延遲、高吞吐的數據管道,方便 AI 工作負載高效地訪問海量數據集。模型訓練和推理對數據依賴極強,Kubernetes 需要在存儲編排、數據本地性、緩存機制等方面提供優化,以減少數據瓶頸。
4. 推理服務彈性擴縮:將模型推理 API 視為一等公民,實現對推理服務的自動擴縮和編排管理。隨著越來越多的 AI 模型以服務形式對外提供接口,Kubernetes 需要能夠根據流量自動伸縮這些模型推理服務,并處理版本更新、流量灰度發布等需求。
上述這些正是 Kubernetes 在 AI 原生時代必須直面的課題。如果不能在這些方面有所突破,Kubernetes 的地位可能會從戰略核心變為背景中的基礎設施管道——有用但不再舉足輕重。
Cloud Native 與 AI Native 技術棧的不同
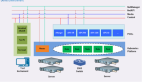
云原生技術棧主要圍繞微服務架構、容器化部署和持續交付來構建,核心包括容器、Kubernetes 編排、服務網格、CI/CD 流水線等,重視應用的快速迭代部署、彈性伸縮和可觀測性。而 AI 原生技術棧在此基礎上向更深層次擴展,側重于異構算力調度、分布式訓練以及高效推理優化等方面。換言之,在云原生的基礎設施之上,AI 原生場景引入了許多專門針對 AI 工作負載的組件:包括分布式訓練框架(如 PyTorch DDP、TensorFlow MultiWorker)、模型服務化框架(如 KServe、Seldon)、高速數據管道和消息系統(如 Kafka、Pulsar)、新的數據庫類型如向量數據庫(Milvus、Chroma 等)以及用于追蹤模型性能的觀測工具等。CNCF 于 2024 年發布的云原生 AI 白皮書中給出了一張技術景觀圖,清晰地展示了 AI Native 如何擴展了 Cloud Native 的邊界,在原有技術棧上疊加了諸多 AI 特定的工具和框架。
 圖片
圖片
云原生 AI 景觀圖(根據 CNCF 云原生 AI 白皮書繪制)
下面我們按照領域列舉云原生/Kubernetes 生態中與 AI 密切相關的一些典型開源項目,來體現 Cloud Native 與 AI Native 技術棧的異同。
通用調度與編排(General Orchestration)
Kubernetes 本身依然是底座,但為更好地支持 AI 任務,出現了諸多在 Kubernetes 之上增強調度能力的項目。例如,Volcano 提供面向批處理和機器學習作業的調度優化,支持任務依賴和公平調度;KubeRay 則通過 Kubernetes 原生控制器來部署和管理 Ray 集群,使大規模分布式計算框架 Ray 可以在 Kubernetes 上彈性伸縮。這些工具強化了 Kubernetes 對 AI 工作負載(尤其是需要占用大量 GPU 的任務)的調度治理能力。
分布式訓練(Distributed Training)
針對大規模模型的分布式訓練,社區也提供了成熟的解決方案。Kubeflow 的 Training Operator 就是典型代表,它為 Kubernetes 提供自定義資源來定義訓練作業(如 TensorFlow Job、PyTorch Job),自動創建相應的 Master/Worker 容器以在集群中并行訓練模型。此外,像 Horovod、DeepSpeed、Megatron 等分布式訓練框架也能在 Kubernetes 環境下運行,通過 Kubernetes 來管理跨節點的訓練進程和資源配置,以實現線性擴展的模型訓練能力。
模型服務化(ML Serving)
在模型訓練完成后,如何將模型部署為在線服務也是 AI Native 技術棧的重要組成部分。在 Kubernetes 生態中,KServe(前身為 KFServing)和 Seldon Core 是兩大常用的模型服務框架,提供了將訓練后的模型打包成容器并部署為可自動擴縮的服務的能力。它們支持流量路由、滾動升級和多模型管理,方便地在 Kubernetes 上實現 AB 測試和 Canary 發布等。近年興起的 vLLM 則是專注于大語言模型(LLM)高性能推理的開源引擎,采用高效的鍵值緩存架構以提升吞吐,并支持在 Kubernetes 集群上橫向擴展部署。例如,vLLM 項目已經從單機版發展出面向集群的“vLLM production-stack”方案,可以在多 GPU 節點上無縫運行,通過共享緩存和智能路由實現比傳統推理服務高數量級的性能提升。
機器學習管道與 CI/CD
在模型從開發到部署的生命周期中,涉及數據準備、特征工程、模型訓練、模型評估到上線部署的一系列步驟。Kubeflow Pipelines 等工具在 Kubernetes 上提供了端到端的機器學習工作流編排機制,允許將上述步驟定義為流水線并運行在容器之中,實現一鍵式的訓練到部署流程。同時,諸如 MLflow 等工具與這些流水線集成,用于追蹤實驗指標、管理模型版本和注冊模型,結合 BentoML 等模型打包工具,可以方便地將模型以一致的方式打包部署到 Kubernetes 集群。
數據科學交互環境(Data Science Environments)
數據科學家常用的 Jupyter Notebook 等交互式開發環境也可以通過 Kubernetes 來提供。像 Kubeflow Notebooks 或 JupyterHub on Kubernetes 讓每位用戶在集群中獲得獨立的容器化開發環境,既方便調用大規模數據集和 GPU 資源,又保證不同用戶/團隊的隔離。這實質上將云原生的多租戶能力應用到數據科學場景,使 AI 研發能夠在共享的基礎設施上進行而不彼此干擾。
工作負載可觀測性(Workload Observability)
在 AI 場景下,系統監控和性能追蹤同樣不可或缺。云原生領域成熟的監控工具如 Prometheus 和 Grafana 仍然大顯身手,可以收集 GPU 利用率、模型響應延遲等指標,為 AI 工作負載提供監控報警。同時,OpenTelemetry 等開放標準為分布式跟蹤提供了基礎,使跨服務的調用鏈路分析也適用于模型推理請求的診斷。另外,Weights & Biases(W&B)等機器學習實驗跟蹤平臺在模型訓練階段廣泛應用,用于記錄模型指標、超參數和評估結果。而面對大語言模型的新挑戰,一些新興工具(如 Langfuse、OpenLLMetry 等)開始專注于模型層面的觀測,提供對生成內容質量、模型行為的監控手段。這些工具與 Kubernetes 的集成,使運維團隊能夠像監控傳統微服務那樣監控 AI 模型的表現。
自動機器學習(AutoML)
為提高模型開發效率,許多團隊會使用超參數調優和自動機器學習工具來自動搜索模型的最佳配置。Kubeflow Katib 是一個 Kubernetes 原生的 AutoML 工具,它通過在集群中并行運行大量實驗(每個實驗跑一個模型訓練作業)來試驗不同的超參數組合,最終找到最優解。Katib 將每個實驗封裝為 Kubernetes Pod 并由 Kubernetes 調度,從而充分利用集群空閑資源。類似的還有微軟的 NNI (Neural Network Intelligence) 等,也支持在 Kubernetes 上運行實驗以進行自動調參和模型結構搜索。
數據架構與向量數據庫(Data Architecture & Vector Databases)
AI 應用對數據的需求促使傳統的大數據技術與云原生結合得更加緊密。一方面,像 Apache Spark、Flink 這類批處理和流處理引擎已經可以在 Kubernetes 上運行,通過 Kubernetes 來管理它們的分布式執行和資源分配。同時,Kafka 和 Pulsar 等消息隊列、HDFS、Alluxio 等分布式存儲也都可以以 Operator 形式部署在 Kubernetes 集群中,為 AI 工作負載提供彈性的數據管道和存儲服務。另一方面,新興的向量數據庫(如 Milvus、Chroma、Weaviate 等)成為 AI 技術棧中特有的組件,用于存儲和檢索向量化的特征表示,在實現相似度搜索、語義檢索等功能時不可或缺。這些向量數據庫同樣能夠部署在 Kubernetes 上運行,有些還提供 Operator 來簡化部署管理。通過 Kubernetes 來托管這些數據基礎設施,團隊可以在同一套集群上同時管理計算(模型推理/訓練)和數據服務,實現計算與數據的一體化調度。
Service Mesh 與 AI Gateway
在 AI Native 場景中,服務網格不僅僅是傳統的東西南北流量治理工具,還逐漸演化為 AI 流量網關。例如:
? Istio / Envoy:通過 Filter 擴展機制支持 AI 流量治理,Envoy 甚至出現了 AI Gateway 原型(Envoy AI Gateway),能夠為推理流量提供統一入口、流量路由和安全策略。
? 擴展 Service Mesh 和網關生態:在 Envoy 和 Kubernetes Gateway API 之上,以 Solo.io 為首的公司推出了一系列開源項目,專門面向 AI 應用:
? kgateway:基于 Envoy proxy 的網關,支持 Prompt Guard 提示詞防護、推理服務編排、多模型調度與故障轉移。
? kagent:Kubernetes 原生的 Agentic AI 框架,通過 CRD 聲明式管理 AI Agent,結合 MCP 協議實現多智能體協作,用于智能診斷和自動化運維。
? agentgateway:專為 AI Agent 通信設計的新型代理(已捐贈給 Linux Foundation),支持 A2A(Agent-to-Agent)通信和 MCP 協議,具備安全治理、可觀測性、跨團隊工具共享等功能。
? kmcp:面向 MCP Server 開發與運維的工具集,提供從 init、build、deploy 到 CRD 控制的全生命周期支持,簡化 AI 工具的原生化運行和治理。
這些項目的出現表明,Service Mesh 技術正從 “微服務的流量治理” 擴展為 “AI 應用的智能流量與 Agent 協作底座”。在 AI Native 架構中,服務網關 + 網格化治理將成為連接 LLM、Agent 與傳統微服務的重要橋梁。
通過以上概覽可以看出,Cloud Native 生態正在快速擴展以擁抱 AI 場景,各類開源項目讓 Kubernetes 成為了承載 AI 工作負載的平臺底座。Kubernetes 社區和周邊生態正積極將云原生領域的成熟經驗(如可擴展的控制平面、聲明式 API 管理等)應用到 AI 領域,從而在 Cloud Native 與 AI Native 之間架起橋梁。這種融合既幫助 AI 基礎設施繼承了云原生的優良基因(彈性、可移植、標準化),也讓 Kubernetes 通過擴展和集成保持在 AI 浪潮中的生命力。
易用性與未來展望
需要注意的是,Kubernetes 本身的易用性和抽象層次也在受到新的審視。隨著 Kubernetes 成為“底座”,開發者希望與之交互的方式變得更簡單高效。社區中不乏關于“Kubernetes 2.0”的探討,有觀點認為當前繁瑣的 YAML 配置已經成為生產實踐中的痛點:據報道稱多達 79% 的 Kubernetes 生產故障可追溯到 YAML 配置錯誤(例如縮進、冒號錯漏等)。“YAML 疲勞”引發了對更高級別、更智能的操作界面的呼聲,一些人暢想未來的 Kubernetes 將弱化對手工編寫 YAML 的依賴,轉而采用更自動化、聲明意圖更簡潔的方式來部署應用。例如,有傳聞中的“Kubernetes 2.0”雛形展示了不再需要 Helm Chart 和成百上千行 YAML,僅用一條類似 k8s2 deploy --predict-traffic=5m 的指令即可完成部署的設想。盡管這些還停留在設想或早期嘗試階段,但折射出業界對 Kubernetes 易用性的期待:即在保證強大靈活的同時,盡量降低認知和操作負擔。這對于支持復雜的 AI 工作負載尤為重要,因為用戶更關心模型本身的迭代,而不希望被底層繁瑣的配置細節絆住手腳。
技術的“消失”與新機遇
最后,正如 Kubernetes 項目主席(名譽)Kelsey Hightower 所言,如果基礎設施的演進符合預期,那么 Kubernetes 終將“消失”在前臺,變成像今天的 Linux 一樣穩定而無處不在的底層支撐。這并不是說 Kubernetes 會被棄用,而是說當 Kubernetes 足夠成熟并被更高層的抽象所封裝后,開發者無需感知其中細節,但它依然默默地提供核心能力。這種“淡出視野”恰恰意味著技術的進一步進化。面對 AI 原生時代,Kubernetes 也許不會以原來的樣子出現于每個開發者面前,但它很可能以內嵌于各種 AI 平臺和工具的形式繼續發揮作用——從云到邊緣,無處不在地提供統一的資源調度與運行時支持。Kubernetes 一方面需要保持內核的穩定與通用性,另一方面也應該鼓勵在其之上構建面向特定領域的上層平臺,就如同早期云原生生態中出現的 Heroku、Cloud Foundry 那樣,在 Kubernetes 之上為不同場景提供更簡化的用戶體驗。
綜上所述,Kubernetes 在 AI Native 時代既面臨挑戰又充滿機遇。只要社區能夠順應潮流,不斷演進 Kubernetes 的能力邊界并改進易用性,我們有理由相信 Kubernetes 會成為 AI 時代混合計算基礎設施的核心支柱,繼續在新的十年里發揮不可替代的作用。
Cloud Native 開源 vs. AI Native 開源
在 Cloud Native 時代,Kubernetes 等基礎設施工具的開源不僅意味著源代碼開放,更意味著開發者可以在本地完整編譯、重構、定制和運行這些工具。社區擁有高度的可控性和創新空間,任何人都能基于開源項目進行深度二次開發,推動生態繁榮。
而在 AI Native 時代,雖然許多大模型(如 Llama、Qwen 等)以“開源”名義發布,甚至開放了模型權重和部分代碼,但實際可重構性和可復現性遠低于 Cloud Native 工具。主要原因包括:
1. 數據不可得與復現門檻高:根據 OSI(Open Source Initiative)最新定義,真正的開源 AI 模型不僅要開放權重和代碼,還需詳細描述訓練數據集。但現實中,絕大多數大模型的訓練數據無法公開,開發者難以復現原始模型。
2. 工具鏈復雜且資源門檻高:AI 模型的訓練依賴龐大的算力、復雜的數據管道和專有工具鏈,普通開發者即使獲得全部代碼和權重,也難以在本地重構或修改模型。
3. 法律與治理障礙:數據版權、隱私保護等法律問題使得開源 AI 的數據流通受限,模型的“開源”更多停留在權重和 API 層面,缺乏 Cloud Native 那樣的完整開放。
4. 生態協作模式不同:Cloud Native 項目強調社區驅動、標準化和可插拔架構,而 AI Native 開源更多依賴企業主導和“部分開放”,社區參與度和創新空間有限。
這種差異導致 AI Native 時代的“開源”更多是一種有限開放:開發者可以使用和微調模型,但很難像重構 Kubernetes 那樣深度定制和創新。真正的開源 AI 仍在探索階段,未來需要解決數據開放、工具鏈標準化和法律治理等多重挑戰,才能實現 Cloud Native 式的開放協作。
AI 領域的開源基金會現狀與挑戰
在云原生領域,CNCF(Cloud Native Computing Foundation)等基金會通過統一治理、項目孵化和社區協作,極大推動了 Kubernetes 及相關生態的繁榮。然而,AI 領域至今尚未出現類似 CNCF 的統一開源基金會來統籌 AI 基礎設施和生態發展。究其原因,主要有以下幾點:
1. 技術分散與生態碎片化:AI 技術棧高度分散,涵蓋模型、框架、數據、硬件、工具鏈等多個層面,不同領域(如深度學習、推理、數據管道、Agent 框架等)各自為政,難以像云原生那樣形成統一的標準和治理模式。
2. 商業利益與專有壁壘:主流 AI 技術(如大模型、推理 API、Agent 平臺)往往由大型科技公司主導,開源項目與商業閉源產品高度交織,企業間缺乏足夠的動力推動“中立基金會”統一治理。
3. 治理模式尚未成熟:Linux Foundation 雖然設有 LF AI & Data、PyTorch Foundation 等子基金會,但它們多聚焦于特定項目或領域,缺乏 CNCF 那樣的“技術景觀圖”和統一孵化機制。AI 領域的快速演進和多樣化需求,使得基金會難以制定通用的治理框架。
4. 行業觀點分歧:如 Linux Foundation CEO Jim Zemlin 所言,AI 領域的開源治理尚處于探索階段,基金會更傾向于支持具體項目而非打造統一大傘。部分業界人士認為,AI 的創新速度和商業化壓力遠高于云原生,基金會模式需要新的適應和演化。
目前,AI 領域的開源基金會主要以“項目孵化 + 社區支持”為主,例如 LF AI & Data 支持 ONNX、PyTorch、Milvus 等項目,但尚未形成 CNCF 式的統一技術景觀和治理體系。未來,隨著 AI 技術標準化和生態成熟,或許會出現類似 CNCF 的統一基金會,但短期內仍以分散治理和多元協作為主。
這一現狀也反映在 Kubernetes 與 AI 的融合路徑上:Kubernetes 作為云原生的底座,依賴 CNCF 的治理和生態推動,而 AI 領域則更多依靠各自項目和社區的自發協作。只有當 AI 技術棧趨于標準化、行業需求趨同,才有可能誕生類似 CNCF 的統一基金會,推動 AI 基礎設施的開放創新。
總結
Kubernetes 在 AI Native 時代正從云原生的“明星”轉型為 AI 應用背后的基礎平臺。面對異構算力、海量數據和智能運維等新需求,Kubernetes 需主動與 AI 生態深度融合,通過插件擴展和框架集成,成為統一承載傳統應用與 AI 系統的混合算力底座。無論在混合云還是企業數據中心,Kubernetes 依然是 AI 工作負載不可或缺的核心基礎設施,只要持續演進,其在 AI 時代的關鍵地位將得以鞏固。
參考資料
? Kubernetes and beyond: a year-end reflection with Kelsey Hightower - cncf.io
? Cloud Native Artificial Intelligence Whitepaper – cncf.io
? Kubernetes in an AI-Native World: Can It Stay Relevant? - clouddon.ai
? Kubernetes 2.0 Might Kill YAML — Here’s the Private Beta That Changed Everything (2025) - aws.plainenglish.io
? The Linux Foundation in the Age of AI - thenewstack.io
? What Is Open Source AI Anyway? - thenewstack.io