百萬&千萬級 Excel 導出場景怎樣實現?怎樣優化?
我見過太多網上帖子文章,上來就是各種方案,要換什么API,要加異步,要調內存等各種手段。
看到這些我都有種小時候感冒鄉村醫生上來就是一堆藥的無奈感;至今沒見過誰是從真正項目場景出發去分析因果關系。
一切手段都是為了服務場景,服務用戶。
 圖片
圖片
這題明面上問的是 Excel 導出優化,實際上是在扒你對數據鏈路全流程(查詢 - 處理 - 生成 - 傳輸)的分析感知&處理能力 —— 大部分人一上來就盯著 Excel 生成本身死磕,根本不理解對癥下藥以及優化過程。
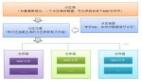
我的風格是總分,從問題場景由淺入深,先花2分鐘看下決策圖,再跟著我的思路來分析:
 圖片
圖片
這是你寫的代碼?
先別急著說你有什么牛逼的方案,我們先從原始問題出發,你最先接手原始的代碼可能是這樣:前端點導出,后端接口直接查數據庫(可能還沒加索引),把所有數據一次性撈到內存里,用 POI 同步生成 Excel 文件,最后通過 HTTP 響應直接返回。
你是不是覺得這流程特順?如果是這樣,那你問題大了,我們逐步道來。
先說查庫,百萬條訂單導出掛?
如果導出的數據只有幾百條,這方案湊活用。但如果業務方說 “我要導出近一年的訂單,大概 100 萬條,甚至更多”,你這代碼會出啥問題?
首先,查庫就卡殼了 ——100 萬條數據一次性 select *,就算有索引,MySQL 把結果集拼裝好返回給應用,這網絡傳輸和內存占用就夠你喝一壺的。
我早年做報表系統時就踩過這坑,一次導出把應用服務的 JVM 堆直接干到 GC 頻繁,最后 OOM 掛了一個節點,現在想起來都臉紅。
同步導出是 “連接池殺手”?
你真的以為把查庫優化了(比如加索引、用 limit 分頁)就沒事了?好,就算你分頁查庫,每次查 1 萬條,100 次查完。
但接下來同步生成 Excel 的過程,還是在占用著當前的 HTTP 連接 ——Tomcat 的連接池就那么大,要是同時有 10 個用戶這么導出,單機容量有限,連接池直接滿了,后面的正常請求全排隊,這服務不就等于半癱了?
說白了,同步模式下,導出任務就是個 “連接池殺手”,把請求線程全占著干 “慢活”。
一堆資源都在浪費沒有最大化利用,線上風險極高,隨時可能打爆你的服務,用戶體驗也極差。
大文件傳輸 + 重復點擊何解?
就算你扛過了查庫和線程占用,生成的 Excel 文件要是有幾十 MB,問題又來了 ——HTTP 傳輸慢不說,前端等待超時怎么辦?
用戶點了導出,等了 5 分鐘沒反應,以為沒成功,又點了好幾次,結果后端重復生成好幾個大文件,資源直接 double 浪費。
此時你開始大概意識到問題是什么了,這個場景面對的是些什么問題,把你的思考過程抬上來再談解決方案,才是合格的RD,也是面試官喜歡的候選人。
優化1:同步改異步
那咱開始優化。首先要解決的不是 Excel,是 **“同步阻塞” 這個巨坑 **。怎么解?異步化。
把 “用戶觸發導出” 和 “Excel 生成” 拆成兩回事 —— 用戶點導出時,后端不直接處理,而是生成一個 “導出任務 ID”,扔到 MQ 里,然后立刻返回給前端 “任務已受理,請用 ID 查結果”。
前端拿著 ID 輪詢(或者后端直接生成完后通過消息助手通知用戶),等 MQ 消費者把 Excel 生成完,再通知用戶下載。
 圖片
圖片
當然最好能利用mq分布式多機消費的特性,將數據量進行分批拆分,每臺機器處理一批或者一段,這樣就不會導致單機oom
這一步就把請求線程解放了,連接池再也不會被堵死。但這里要注意,異步不是一勞永逸的 —— 你得處理任務狀態(等待中 / 生成中 / 成功 / 失敗);
還得考慮失敗重試(比如生成到一半 MQ 掛了怎么辦?),甚至要做任務限流,不能讓 1000 個用戶同時扔導出任務,把 MQ 和生成服務壓垮。
優化2:分頁不夠,游標 + 數倉來湊
解決了異步,再看數據查詢。分頁查庫是基礎,但有個坑:當偏移量很大時(比如 limit 100000, 1000),MySQL 會掃描前面 10 萬條數據再跳過,這時候索引效率會驟降。
怎么辦?用 “游標分頁”—— 比如按訂單 ID 排序,每次查的時候帶上上次的最大 ID(where id > last_id limit 1000),這樣索引一直有效。
另外,要是查庫涉及多表關聯,或者計算邏輯復雜(比如統計每個用戶的訂單總額);
直接查業務庫會影響線上業務,如果實時性不是那么高,完全可以考慮離線數倉 —— 把導出需要的明細或匯總數據,提前用定時任務同步到 ClickHouse、Hive 這類 OLAP 數據庫里,導出時查數倉,不碰業務庫。
或者直接扔異步隊列里面(注意,最好不要扔線程池,單機容易oom,最好分布式多機消費處理)
大廠稍微大一點的非實時場景基本都是這樣干!
優化3:Excel 生成,拆服務、換格式?
接下來才到 Excel 生成本身。直接在應用服務里用 POI 生成,還是有問題 ——100 萬條數據生成 Excel,就算用 SXSSF(流式生成,避免 OOM),也會占用不少 CPU 和內存。
能不能把這步也拆出去?(不到萬不得已一般不拆,工作量反而增大,但是你得有這個意識)搞個專門的 “Excel 生成服務”,只負責從 MQ 接任務、從數倉查數據、生成文件。這樣業務服務和生成服務解耦,各自擴容 —— 業務服務扛并發請求,生成服務扛 CPU 密集型的文件生成。
另外,生成格式也能做文章:如果業務對 Excel 格式要求不高(比如只是看數據,不用公式、圖表),可以先生成 CSV 文件(生成速度比 Excel 快 10 倍不止),再轉成 Excel;
或者直接讓用戶下載 CSV(前端也能打開);如果必須要 Excel,除了 POI,還可以試試 Alibaba 的 EasyExcel,它對內存的優化比原生 POI 更到位,還支持注解配置,少寫不少破代碼。
優化4:大文件傳輸卡?扔去 OSS
最后是大文件傳輸的問題。生成好的 Excel 文件,要是幾十 MB 甚至上百 MB,讓應用服務直接通過 HTTP 返給用戶,還是會占用帶寬。
這時候就得用對象存儲(比如 OSS、S3)—— 剛才上面也提過,可以生成服務把 Excel 文件寫完后,直接上傳到 OSS,然后把 OSS 的下載鏈接(帶簽名、設過期時間,避免泄露)存到數據庫里。
用戶查結果時,后端直接返回這個鏈接,用戶去 OSS 下載,應用服務徹底不用扛傳輸壓力。也可以直接用消息助手通知用戶通過鏈接下載,省時省力(不過小公司可能成本略高)
這里要注意簽名的安全性,比如鏈接過期時間設 1 小時,避免用戶把鏈接分享出去,泄露數據。
優化5:重復?加緩存唄
到這你是不是覺得差不多了?別急,還有個容易被忽略的點:緩存重復請求。
比如同一個用戶,一天內重復導出 “近 7 天的訂單”,數據沒變化,沒必要重復生成。這時候可以加個緩存,key 是 “用戶 ID + 導出條件(時間范圍、字段)”,value 是 OSS 鏈接,緩存過期時間設成數據更新的周期(比如訂單數據實時更新,緩存設 1 小時)。
這樣重復請求直接命中緩存,省了查庫和生成的成本。但要注意緩存失效策略 —— 如果底層數據更新了(比如用戶改了訂單狀態),得及時清掉對應的緩存,不然用戶下載到的是舊數據。
總結
最后總結下,沒有什么 “牛逼的方案” 能解決所有導出慢的問題,核心思路是 “拆解鏈路、分治優化”:把 “查數據 - 生成文件 - 傳輸文件” 拆成三個獨立環節,每個環節用最適合的技術去扛(數倉扛查詢、異步服務扛生成、對象存儲扛傳輸)
同時用緩存減少重復勞動,通過打點監控(比如任務成功率、生成耗時)盯著鏈路中的坑。
任何脫離場景談優化都是耍流氓 —— 如果業務方導出的數據永遠不超過 1 萬條,那搞異步和對象存儲就是過度設計;
但如果是 To B 業務,用戶動不動導出百萬級數據,那上述的鏈路改造就是必須的。