OneSearch,揭開快手電商搜索「一步到位」的秘技
還有一個(gè)多月,一年一度的“雙十一”購物節(jié)就要來了!
作為消費(fèi)者,你通常會(huì)如何尋找心儀的商品呢?或許你興致勃勃地在搜索框里敲下關(guān)鍵詞,卻發(fā)現(xiàn)呈現(xiàn)出來的商品列表總是差強(qiáng)人意。那么,問題究竟出在哪里?
這一切,還要從電商平臺(tái)常用的傳統(tǒng)搜索架構(gòu)說起。目前主流系統(tǒng)采用“召回 -> 粗排 -> 精排” 的級(jí)聯(lián)式架構(gòu)。
- 召回層:比如你搜索 “紅色連衣裙”,系統(tǒng)會(huì)迅速從數(shù)億商品中篩選出上萬個(gè)包含 “紅色”“連衣裙” 關(guān)鍵詞的商品。這步追求快和全,但精度不高 —— 難免會(huì)出現(xiàn)一些標(biāo)題黨商品(比如標(biāo)題強(qiáng)行蹭熱點(diǎn),寫 “紅色連衣裙” 但其實(shí)賣的是搭配的開衫)
- 粗排層:系統(tǒng)使用輕量級(jí)模型對(duì)這上萬個(gè)商品粗略排序,去掉一些明顯不相關(guān)的商品。
- 精排層:采用更復(fù)雜、精細(xì)的模型,對(duì)幾百個(gè)剩余商品進(jìn)行最終排序。它會(huì)綜合考量點(diǎn)擊率、銷量、價(jià)格、用戶歷史偏好等多種因素,返回你最終看到的商品列表。

那么,到底是哪些環(huán)節(jié)導(dǎo)致我們總是看到不滿意的商品?原因在于:
- 商品描述混亂:賣家為增加曝光,常在標(biāo)題中堆砌大量不相關(guān)熱詞(如 “民族風(fēng)復(fù)古流蘇酒紅色吊帶連衣裙云南新疆西藏旅游度假長(zhǎng)裙”),嚴(yán)重干擾系統(tǒng)判斷。
- 相關(guān)性問題突出:用戶搜索詞往往很短(例如 “夏季闊腿褲”),但只要某一屬性不匹配(如商品實(shí)際是 “裙褲” 款式),就不再相關(guān),而系統(tǒng)難以精準(zhǔn)捕捉這類差異。
- 級(jí)聯(lián)結(jié)構(gòu)存在瓶頸:級(jí)聯(lián)式框架如同三道篩子,如果第一層召回效果差,后面再怎么排也難挽回。并且三層目標(biāo)不一致,整體協(xié)同困難。
- 冷啟動(dòng)難題:新上架商品或搜索量極低的長(zhǎng)尾詞,因缺乏歷史數(shù)據(jù),很難被系統(tǒng)正確處理,導(dǎo)致曝光機(jī)會(huì)匱乏。
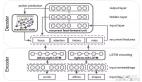
1、OneSearch:電商搜索端到端生成式框架
為解決傳統(tǒng)電商搜索系統(tǒng)面臨的諸多挑戰(zhàn),工業(yè)界通常采用級(jí)聯(lián)式架構(gòu),以實(shí)現(xiàn)較高的商業(yè)效益和系統(tǒng)穩(wěn)定性。然而,隨著大語言模型的興起,研究者開始探索如何借助其強(qiáng)大的語義理解與世界知識(shí)進(jìn)一步優(yōu)化搜索體驗(yàn)。
在此背景下,快手提出了業(yè)界首個(gè)工業(yè)級(jí)部署的電商搜索端到端生成式框架 ——OneSearch。

- 論文標(biāo)題:《OneSearch: A Preliminary Exploration of the Unified End-to-End Generative Framework for E-commerce Search》
- 論文地址:https://arxiv.org/abs/2509.03236
該框架涵蓋以下三大創(chuàng)新點(diǎn):
1. 提出關(guān)鍵詞增強(qiáng)層次量化編碼(KHQE)模塊,能夠在保持層次化語義與商品獨(dú)特屬性的同時(shí),強(qiáng)化 Query - 商品相關(guān)性約束;
2. 設(shè)計(jì)多視角用戶行為序列注入策略,構(gòu)建了行為驅(qū)動(dòng)的用戶標(biāo)識(shí)(UID),并融合顯式短期行為與隱式長(zhǎng)期序列,全面而精準(zhǔn)地建模用戶偏好;
3. 引入偏好感知獎(jiǎng)勵(lì)系統(tǒng)(PARS),結(jié)合多階段監(jiān)督微調(diào)與自適應(yīng)獎(jiǎng)勵(lì)強(qiáng)化學(xué)習(xí)機(jī)制,以捕捉細(xì)粒度用戶偏好信號(hào)。

2、OneSearch 技術(shù)方案三大創(chuàng)新
2.1 關(guān)鍵詞增強(qiáng)層次量化編碼(KHQE)模塊

商品語義涵蓋標(biāo)題、關(guān)鍵詞、詳情頁、商家、價(jià)格、圖片等多維度信息。然而,商家為提升曝光度,常在標(biāo)題中堆砌大量關(guān)鍵詞,導(dǎo)致出現(xiàn)多主體甚至屬性沖突的問題,例如:“法式掛脖連衣裙女夏寬松顯瘦絕美溫柔初戀優(yōu)雅皮靴搭配紅色淺藍(lán)色粉色”。此類混雜表述易掩蓋商品的核心特征。
為實(shí)現(xiàn)多元化搜索意圖下 query 與商品的精準(zhǔn)匹配,首先必須對(duì)商品的豐富語義進(jìn)行充分建模。快手團(tuán)隊(duì)設(shè)計(jì)了四個(gè)任務(wù)來對(duì)齊協(xié)同和語義表征:
1. Q2Q 和 I2I 對(duì)比損失:用于對(duì)齊協(xié)同相似對(duì)的表征;
2. Q2I 對(duì)比損失:增強(qiáng) Query - 商品對(duì)的語義相關(guān)性,確保表征模型理解業(yè)務(wù)特性;
3. Q2I 邊際損失:進(jìn)一步學(xué)習(xí)具有不同行為級(jí)別(如曝光、點(diǎn)擊、下單)的 < q, i > 對(duì)的協(xié)同信號(hào)偏差;
4. 基于 LLM 的難樣本糾偏:保證難樣本相關(guān)性水位。
第一步:提取核心屬性
使用 Qwen-VL/AC 自動(dòng)機(jī)分別識(shí)別出商品 /query 的關(guān)鍵屬性(如品牌、品類、顏色、材質(zhì))。例如,從前述混亂標(biāo)題中精準(zhǔn)提取 “連衣裙”、“法式”、“掛脖”、“夏季” 等核心屬性,弱化 “絕美”、“皮靴” 等無關(guān)或沖突詞匯。
第二步:生成層次化編碼(SID)
傳統(tǒng) SID 編碼方法(如 RQ-VAE、RQ-Kmeans)傾向于編碼商品間的共性特征,導(dǎo)致語義相近的商品被映射到相同編碼中,無法充分保留個(gè)性化差異,從而制約生成式檢索模型的性能。
為解決該問題,快手搜索技術(shù)團(tuán)隊(duì)提出 RQ-OPQ 編碼方案,融合 RQ(殘差量化)和 OPQ(優(yōu)化乘積量化)的優(yōu)勢(shì),從縱向與橫向兩個(gè)維度建模商品特征:
- RQ:負(fù)責(zé)處理層次化語義特征,通過多層殘差量化捕捉從粗粒度到細(xì)粒度的商品語義。
- OPQ:負(fù)責(zé)量化獨(dú)特特征,專門編碼每個(gè)商品的差異化屬性。
首先使用 RQ-Kmeans 進(jìn)行 3 層層次化編碼,構(gòu)建商品的主體語義表示。可視為從粗到細(xì)的分類標(biāo)簽體系。例如:第一層為 “服裝”,第二層為 “連衣裙”,第三層為 “法式款式”。經(jīng)過聚類后所剩余的殘差信息,包含商品最獨(dú)特、最細(xì)粒度的屬性。進(jìn)一步對(duì)殘差向量應(yīng)用 OPQ 進(jìn)行 2 層編碼,以捕獲商品的細(xì)微差異特征,如 “iPhone 17 Pro” 的 “星宇橙色”、“256GB 內(nèi)存” 等關(guān)鍵屬性。缺失此類信息將導(dǎo)致模型無法區(qū)分同類別商品的細(xì)微差別。
最終每個(gè)商品由 5 層 SID 組成:前 3 層來自 RQ 聚類中心,后 2 層來自 OPQ 量化結(jié)果。該結(jié)構(gòu)相當(dāng)于為每一個(gè)商品生成了一個(gè)具備豐富語義層次的 “智能身份證”,顯著提升了生成式檢索的區(qū)分能力和準(zhǔn)確性。
2.2 多視角用戶行為序列

傳統(tǒng)搜索系統(tǒng)往往難以有效捕捉用戶的近期偏好與長(zhǎng)期興趣。其核心原因在于傳統(tǒng)排序模型中的用戶 ID 僅為一串隨機(jī)數(shù)字(如 “12345”),缺乏語義信息。而在 OneSearch 中,依據(jù)用戶的長(zhǎng) / 短期行為序列構(gòu)建具有區(qū)分性的用戶標(biāo)識(shí)(distinctive User ID)。例如,若用戶近期頻繁瀏覽露營裝備,并長(zhǎng)期表現(xiàn)出對(duì)高性價(jià)比商品的偏好,系統(tǒng)會(huì)為其生成一個(gè)精準(zhǔn)描述這些行為的標(biāo)識(shí),而非無意義的編號(hào)。具體而言,采用有序加權(quán)方式基于用戶的長(zhǎng) / 短期行為序列計(jì)算 distinctive User ID:

2.2.1 顯式引入短行為序列
用戶最近的搜索 Query 和點(diǎn)擊商品可反映其即時(shí)意圖。例如,若用戶近期頻繁搜索 “開學(xué)必備”、“宿舍神器”,系統(tǒng)可推斷其可能為準(zhǔn)大學(xué)生,進(jìn)而在搜索結(jié)果頁中圍繞此進(jìn)行展示。為實(shí)現(xiàn)這一目標(biāo),系統(tǒng)將用戶最近的搜索 Query 序列和 SID 形式的點(diǎn)擊商品序列直接編碼至模型輸入(prompt)中,以顯式方式強(qiáng)調(diào)這些近期行為特征。同時(shí),為緩解新用戶行為稀疏性問題并模擬興趣演化,采用滑動(dòng)窗口策略進(jìn)行數(shù)據(jù)增強(qiáng)。
2.2.2 隱式引入長(zhǎng)行為序列
長(zhǎng)期行為序列旨在從用戶歷史行為(如點(diǎn)擊、購買等)中提煉穩(wěn)定的偏好特征,形成整體用戶畫像。例如,用戶長(zhǎng)期購買高端電子產(chǎn)品和小眾設(shè)計(jì)師品牌,可體現(xiàn)其消費(fèi)層次和審美傾向。
在電商場(chǎng)景中,用戶行為序列長(zhǎng)度常高達(dá)~103,無法以顯式方式完整引入。考慮到 BART 等模型的最大輸入長(zhǎng)度限制(如 1024)以及長(zhǎng)序列對(duì)線上推理延遲的影響,可通過嵌入(embedding)方式隱式融合用戶個(gè)性化信息。與 OneRec 等方法直接對(duì)海量視頻 ID 進(jìn)行建模(嵌入維度達(dá)幾十億)不同,OneSearch 提出基于 SID 維度建模,具有以下優(yōu)點(diǎn):
- embedding 維度低,僅幾千維 emb 即可表征全量商品
- SID 本身已經(jīng)包含了類目、材質(zhì)等層級(jí)化信息,無需引入額外特征
為進(jìn)一步降低線上計(jì)算復(fù)雜度,對(duì)用戶行為 SID 序列分層(L1/L2/L3)進(jìn)行均值池化,并利用 QFormer 對(duì)序列表征進(jìn)行壓縮,最終得到一組(n, 768)維向量,即 n 個(gè)用戶序列 token。消融實(shí)驗(yàn)表明,去除長(zhǎng)期行為序列會(huì)導(dǎo)致離線性能顯著下降,證明了隱式引入長(zhǎng)序列的必要性。
該方法使系統(tǒng)能夠更全面、深層地理解用戶意圖,顯著提升了個(gè)性化搜索的準(zhǔn)確性與用戶體驗(yàn)。
2.3 引入偏好感知獎(jiǎng)勵(lì)系統(tǒng)(PARS)
當(dāng)然,光能識(shí)別商品和理解用戶還不夠,最終得把所有匹配的商品排好順序。
相比于推薦系統(tǒng)中的序列一致性,搜索中 query 和 item 之間的強(qiáng)相關(guān)性約束對(duì)生成式模型提出了更大的挑戰(zhàn)。對(duì)于 GR 模型,不僅需要實(shí)現(xiàn) SID 與 query/item 之間的語義對(duì)齊,還需要根據(jù)序列信息直接生成滿足相關(guān)性約束和用戶偏好的 item。因此,OneSearch 提出了一個(gè)偏好感知獎(jiǎng)勵(lì)系統(tǒng),包括多階段監(jiān)督微調(diào)(SFT)和自適應(yīng)獎(jiǎng)勵(lì)系統(tǒng),以增強(qiáng)模型的個(gè)性化排序能力。

2.3.1 監(jiān)督微調(diào)(SFT)階段
用于搜索的生成式模型,需要同時(shí)準(zhǔn)確把握〈query, item〉對(duì)的相關(guān)性以及用戶的個(gè)性化偏好。OneSearch 創(chuàng)新性地設(shè)計(jì)了三階段 SFT 訓(xùn)練任務(wù):分別實(shí)現(xiàn)語義內(nèi)容對(duì)齊、協(xié)同信息對(duì)齊、用戶個(gè)性化建模。這就類似于 “上課” 的過程,從易到難,進(jìn)行課程學(xué)習(xí)。
- 第一節(jié)課:認(rèn)識(shí) query/item 的 SID 與類目(比如 “薄款襯衫” 對(duì)應(yīng)哪個(gè) SID、哪一類目);
- 第二節(jié)課:學(xué)習(xí) query 和 item 的共現(xiàn)關(guān)系(比如搜索了 “極簡(jiǎn)風(fēng)” 的用戶,常買哪些商品);
- 第三節(jié)課:結(jié)合用戶的興趣檔案做練習(xí)(比如給 近期看露營 + 長(zhǎng)期愛性價(jià)比 的用戶,高優(yōu)展示哪款類型帳篷)。

這一分階段的學(xué)習(xí)策略有效提升了模型對(duì)相關(guān)性約束和用戶偏好的聯(lián)合建模能力。
2.3.2 強(qiáng)化排序?qū)W習(xí)(RL4Ranking)階段
為了使生成式模型具備排序能力,一種直觀的思路是借助強(qiáng)化學(xué)習(xí),對(duì)用戶有交互和無交互行為的區(qū)別學(xué)習(xí)。OneSearch 引入了一套自適應(yīng)的獎(jiǎng)勵(lì)系統(tǒng),首先通過 reward model 實(shí)現(xiàn)與線上精排模型的分布對(duì)齊,再結(jié)合用戶真實(shí)交互行為進(jìn)行監(jiān)督訓(xùn)練,進(jìn)一步激發(fā)生成式模型的推理能力。
樣本自適應(yīng)權(quán)重構(gòu)建
電商搜索場(chǎng)景中用戶意圖多樣,既包括強(qiáng)購買意圖,也包含瀏覽、比價(jià)等弱意圖行為。與視頻推薦使用時(shí)長(zhǎng)、次留等指標(biāo)不同,電商搜索更關(guān)注 CTR、CVR、訂單量與營收等直接轉(zhuǎn)化指標(biāo)。因此,如何對(duì)不同行為樣本賦予合理的獎(jiǎng)勵(lì)權(quán)重,就顯得非常重要。OneSearch 引入規(guī)則獎(jiǎng)勵(lì)機(jī)制(reward model),將用戶行為劃分為六個(gè)等級(jí),并為每一類設(shè)置基礎(chǔ)獎(jiǎng)勵(lì)值。在此基礎(chǔ)上,進(jìn)一步引入動(dòng)態(tài)調(diào)節(jié)因子,基于商品近 7 天內(nèi)的 CTR、CVR 等實(shí)時(shí)表現(xiàn)動(dòng)態(tài)微調(diào)樣本權(quán)重,緩解新品曝光不足帶來的偏差。這種機(jī)制使得即使同為高等級(jí)樣本(如兩個(gè)成交商品),也會(huì)因歷史轉(zhuǎn)化效率的不同而在獎(jiǎng)勵(lì)權(quán)重上呈現(xiàn)細(xì)微差異,從而幫助模型捕捉更細(xì)粒度的用戶偏好。
獎(jiǎng)勵(lì)模型(Reward Model)設(shè)計(jì)
為了對(duì)齊線上精排分布,OneSearch 首先設(shè)計(jì)了一個(gè)直觀且高效的獎(jiǎng)勵(lì)模型。保持模型結(jié)構(gòu) & 損失函數(shù)與原精排一致、特征輸入與 OneSearch 對(duì)齊,即用更少的特征擬合線上精排模型的分布,這樣可以繼承原有精排模型的穩(wěn)定性。獎(jiǎng)勵(lì)模型訓(xùn)練好后,可以從線上日志中拉取用戶真實(shí)搜索過的 query 等信息,使用 SFT 后的 OneSearch 模型生成候選 item 列表,再使用獎(jiǎng)勵(lì)模型進(jìn)行進(jìn)一步的排序;可以篩選出順序發(fā)生變化的樣本,這些差異樣本反映了當(dāng)前生成模型與線上精排在對(duì)用戶偏好理解上的差距。利用這批數(shù)據(jù)進(jìn)行監(jiān)督訓(xùn)練,可有效增強(qiáng)模型的偏好學(xué)習(xí)能力。
用戶交互引導(dǎo),突破模型推理限制
在初步獲得精排排序能力后,OneSearch 進(jìn)一步引入用戶真實(shí)交互數(shù)據(jù)監(jiān)督訓(xùn)練,以激發(fā)生成模型的深層推理能力。訓(xùn)練中將以有點(diǎn)擊、成交等正向反饋的樣本作為正例,曝光未點(diǎn)擊等作為負(fù)例,通過混合排序建模的方式,使模型在提升排序性能的同時(shí),不損害生成多樣性,避免 “獎(jiǎng)勵(lì)破解”(reward hacking)問題。
總結(jié)而言,OneSearch 的強(qiáng)化學(xué)習(xí)機(jī)制分為兩步:首先通過獎(jiǎng)勵(lì)模型促使 OneSearch 擬合線上精排模型分布,學(xué)習(xí)基礎(chǔ)的排序;再通過基于 Listwise DPO 進(jìn)一步對(duì)齊用戶偏好,突破排序性能的上限。
3、效果評(píng)測(cè)
離線實(shí)驗(yàn)效果
基于線上真實(shí)用戶行為日志構(gòu)建的離線測(cè)試集表明,OneSearch 提出的 RQ-OPQ 編碼與自適應(yīng)獎(jiǎng)勵(lì)系統(tǒng)相結(jié)合的方法效果最優(yōu),相比現(xiàn)有級(jí)聯(lián)式系統(tǒng)(OnlineMCA),各項(xiàng)指標(biāo)均有顯著提升。

在線實(shí)驗(yàn)結(jié)果
為了驗(yàn)證 RQ-OPQ 編碼和用戶序列引入的有效性,OneSearch 先后進(jìn)行了兩版實(shí)驗(yàn),v1 版本僅使用 RQ 編碼,取得了和線上級(jí)聯(lián)式系統(tǒng)相近的效果;引入 RQ-OPQ 編碼和用戶序列建模后,v2 版本在 CTR 和 CVR 上有了顯著的提升;額外地,在生成式模型的基礎(chǔ)上進(jìn)一步引入獎(jiǎng)勵(lì)系統(tǒng),能獲得轉(zhuǎn)化指標(biāo)的全面提升,最終版本訂單量提升 3.22%,買家數(shù)提升 2.4%。
該實(shí)驗(yàn)驗(yàn)證了 OneSearch 模型在真實(shí)電商環(huán)境中的有效性。這是在大規(guī)模工業(yè)場(chǎng)景下,生成式模型第一次取代搜索全鏈路的可落地方案。目前該系統(tǒng)已在快手的多個(gè)電商搜索場(chǎng)景中成功部署,每日服務(wù)數(shù)百萬用戶,產(chǎn)生數(shù)千萬 PV。

人工評(píng)測(cè)與在線性能
在人工評(píng)測(cè)中,OneSearch 系列模型不僅在 CVR 和 CTR 上表現(xiàn)優(yōu)異,同時(shí)在頁面整體滿意度、商品質(zhì)量及 query-item 相關(guān)性方面均顯著優(yōu)于線上級(jí)聯(lián)式系統(tǒng)。此外,在線性能方面,機(jī)器計(jì)算效率(MFU)提升顯著,從 3.26% 提高到 24.06%,相對(duì)提升達(dá) 8 倍;線上推理成本(OPEX)降低 75.40%,資源利用效率顯著優(yōu)化。


泛化性和場(chǎng)景分析
OneSearch 在絕大多數(shù)行業(yè)類別中均帶來 CTR 的穩(wěn)定提升,展現(xiàn)出良好的泛化能力。按 Query 頻次、商品冷啟動(dòng)及用戶層級(jí)下探表明,OneSearch 在高、中、低頻 query 上均實(shí)現(xiàn)了 CTR 提升,尤其在中長(zhǎng)尾 query 上的改善更為顯著。此外,該系統(tǒng)在冷啟動(dòng)(cold-start)場(chǎng)景下表現(xiàn)尤為突出,效果顯著優(yōu)于常規(guī)(warm)場(chǎng)景,說明生成式檢索模型能夠更有效地應(yīng)對(duì)長(zhǎng)尾用戶和新上架商品的排序挑戰(zhàn)。


4、始終追蹤技術(shù)前沿
快手搜索技術(shù)部作為公司的核心算法研發(fā)部門,始終站在大數(shù)據(jù)與人工智能技術(shù)發(fā)展的前沿,致力于將大模型(LLM)技術(shù)與海量數(shù)據(jù)深度融合,打造行業(yè)領(lǐng)先的智能搜索平臺(tái),持續(xù)推動(dòng)用戶體驗(yàn)與技術(shù)能力的協(xié)同進(jìn)化。部門業(yè)務(wù)覆蓋視頻搜索、電商搜索與 AI 搜索等多個(gè)核心方向,聚焦于構(gòu)建精準(zhǔn)、高效、智能的新一代搜索系統(tǒng)。
其中,OneSearch 所屬的電商搜索團(tuán)隊(duì)以實(shí)際業(yè)務(wù)需求為驅(qū)動(dòng),堅(jiān)持 “技術(shù)?業(yè)務(wù)” 雙輪迭代機(jī)制,多項(xiàng)技術(shù)突破已發(fā)表在 RecSys、CIKM、KDD、EMNLP、AAAI、ACM MM 等國際頂級(jí)會(huì)議上,多次引起業(yè)界廣泛關(guān)注。面向未來,團(tuán)隊(duì)將持續(xù)深耕多模態(tài)理解、生成式搜索與 AI 搜索等關(guān)鍵方向,致力于實(shí)現(xiàn)更智能、更流暢、更人性化的搜索交互體驗(yàn),以技術(shù)驅(qū)動(dòng)業(yè)務(wù)創(chuàng)新,不斷攀登智能搜索的新高峰。
5、未來展望
在后續(xù)研究中,快手電商搜索團(tuán)隊(duì)將致力于探索在線實(shí)時(shí)編碼方案,縮小預(yù)定義編碼與流式訓(xùn)練之間的差異。此外,還將引入更強(qiáng)大的強(qiáng)化學(xué)習(xí)機(jī)制以更精準(zhǔn)地匹配用戶偏好,并結(jié)合圖像、視頻等多模態(tài)商品特征,進(jìn)一步提升模型的推理效果與用戶體驗(yàn)。