1.58bit不輸FP16!微軟推出全新模型蒸餾框架,作者全是華人
1.58bit量化,內存僅需1/10,但表現不輸FP16?
微軟最新推出的蒸餾框架BitNet Distillation(簡稱BitDistill),實現了幾乎無性能損失的模型量化。
該框架在4B及以下的Qwen、Gemma上已被證實有效,理論上可用于其他Transformer模型。

同等硬件性能下,使用該方法量化后的推理速度提升2.65倍,內存消耗僅1/10。

網友看了之后表示,如此一來昂貴的GPU將不再是必需品,英偉達的好日子要到頭了。

BitDistill框架設計
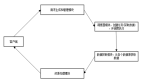
BitDistill包含三個依次銜接的階段,分別是模型結構優化(Modeling Refinement)、繼續預訓練(Continue Pre-training)和蒸餾式微調(Distillation-based Fine-tuning)。
建模結構優化的主要目標是為1.58-bit模型訓練提供結構層面的支持,緩解低精度訓練中常見的優化不穩定問題。
在傳統的全精度Transformer模型中,隱藏狀態的方差通常在預訓練時已被良好控制。然而,當模型被壓縮到極低位寬(如1.58-bit)后,激活值在經過量化前的分布可能會出現方差膨脹等問題,從而導致訓練過程震蕩甚至失敗。
為了應對這一問題,BitDistill在每一個Transformer層中引入了一個名為SubLN(Sub-layer LayerNorm)的歸一化模塊。
具體來說,SubLN的插入位置有兩個,一是在多頭自注意力模塊的輸出投影之前,二是在前饋網絡的輸出投影之前。
這樣的插入方式,不改變主干計算路徑,僅在關鍵位置對信號做規范化調整,使得量化后模型具備更好的收斂性。
這種設計使得量化前的表示能夠在進入下一計算階段前被重新歸一化,有效抑制激活尺度的發散,提升訓練穩定性。

經過第一階段的結構修改后,模型雖具備量化訓練的能力,但如果直接將其用于特定任務的微調,尤其是在模型規模較大時,仍會遭遇顯著的性能損失。
也就是說,隨著模型參數增大,1.58-bit模型與其全精度版本之間的性能差距反而進一步擴大。
為了緩解這一問題,BitDistill設計了一個輕量級的繼續預訓練階段。在此階段中,模型會在少量通用語料上進行自回歸語言建模訓練,訓練目標為最大化條件概率。
這一過程并不涉及特定任務數據,也不需精調標簽,僅是讓模型權重從全精度空間緩慢遷移到適合1.58-bit表示的分布上。
換句話說,這個階段的本質是一種預適配訓練,讓模型“學會如何被量化”,避免在微調階段才倉促適應低位寬帶來的信息丟失。

完成結構調整與繼續預訓練后,模型被正式引入到具體下游任務中進行1.58-bit量化訓練。
為了彌補量化后模型在表達能力上的損失,BitDistill采用了一種雙重蒸餾機制——Logits蒸餾與多頭注意力蒸餾。
這一階段的目的是從原始的全精度模型中提取關鍵行為模式,并引導低位寬模型在具體任務上學習這些模式,從而恢復性能。
Logits蒸餾是將全精度模型輸出的類概率分布作為“軟標簽”,引導量化模型在預測分布上向其靠攏。具體做法是使用Kullback–Leibler散度(KL散度)來最小化兩者輸出分布之間的差異。

由于Transformer模型的性能很大程度依賴其注意力機制,BitDistill進一步從結構層面對注意力關系進行蒸餾。這種蒸餾不是對注意力權重做對齊,而是對Q、K、V向量構成的關系矩陣進行分布層面的模仿。
具體而言,對于選定的某一層(通常是模型后部的一層),分別從教師模型與學生模型中提取Q、K、V三組張量,并計算它們之間的點積相關性,形成關系分布矩陣。
然后通過KL散度使兩者對齊,訓練學生模型還原出與教師模型相似的結構依賴。

FP16無損量化至1.58bit
BitDistill展示出在多個下游任務中幾乎等同于全精度模型的表現,同時顯著降低了內存開銷并提升了推理速度。作者在兩個典型任務類型上進行了全面實驗,分別是文本分類與文本摘要。
以Qwen3為基礎模型,測試中的分類任務包括MNLI、QNLI與SST-2,摘要任務則采用CNN/DailyMail數據集作為標準。
分類任務中,BitDistill的1.58-bit模型在準確率與生成質量指標上與全精度微調模型(FP16-SFT)幾乎一致,而顯著優于直接對量化模型進行微調的BitNet-SFT。

在文本摘要任務中,BitDistill同樣表現出高度保真的生成能力。
以ROUGE和BLEU等標準指標衡量,在CNN/DailyMail上,BitDistill所生成文本的BLEU為14.41,ROUGE-L為27.49,與FP16模型的13.98和27.72幾乎等同,甚至在BLEU上略有超出。
相比之下,直接量化后的模型在BLEU與ROUGE上普遍下降2至3個百分點。

為了驗證BitDistill在不同模型架構上的通用性,作者還將其應用于Gemma和Qwen2.5等其他預訓練模型,結果BitDistill都能實現對全精度性能的高度還原。
進一步的實驗表明,BitDistill在不同量化策略下也具備良好的兼容性。作者將其與常見的Block-Quant、GPTQ、AWQ等量化方法結合,在分類任務上依然能夠穩定地恢復原始性能,證明該方法可作為一個獨立于量化算法的上層蒸餾方案,適用于多種后量化優化場景。
One More Thing
BitStill的作者全部來自微軟研究院,而且均為華人。
通訊作者為微軟亞洲研究院副總裁、武漢大學校友韋福如博士。
他讀博期間就曾在MSRA實習,畢業后到IBM工作,又于2010年重回微軟,工作至今。

第一作者Xun Wu為清華計算機碩士,本科畢業于中南大學,2023年開始到微軟研究院實習,畢業后正式入職。

其他作者名單如下:

論文地址:https://arxiv.org/abs/2510.13998