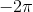一圖勝千言被實(shí)現(xiàn)了!DeepSeek-OCR用圖片壓縮文本,10倍壓縮率
DeepSeek開源了DeepSeek-OCR,用1張圖片的信息,還原10頁書的文字,10倍的壓縮率,可以做到幾乎不丟失信息。

視覺編碼器走了不少彎路
大型語言模型記性不好,或者說,能記住的東西太有限。你給它一篇長長的文章,它的計(jì)算量呈二次方往上飆。
DeepSeek-AI團(tuán)隊(duì)提出了一個(gè)腦洞大開的想法:既然文字這么占地方,我們干嘛非得用文字存呢?能不能用圖片來“壓縮”文字信息?
這個(gè)點(diǎn)子基于一個(gè)我們都懂的道理,“一圖勝千言”。一張印滿文字的圖片,在模型眼里,可能只需要很少的視覺token(vision tokens)就能表達(dá)清楚。而如果把這些文字轉(zhuǎn)換成數(shù)字文本,token數(shù)量可能多得嚇人。這就好比一個(gè)壓縮包,用視覺的方式把海量文本信息給打包了。
說干就干,他們搗鼓出了一個(gè)叫DeepSeek-OCR的模型來驗(yàn)證這個(gè)想法。
結(jié)果相當(dāng)驚人,當(dāng)壓縮比,也就是文本token數(shù)是視覺token數(shù)的10倍以內(nèi)時(shí),模型居然能把圖片里的文字幾乎完美地還原出來,準(zhǔn)確率高達(dá)97%。就算把壓縮比拉到20倍,準(zhǔn)確率也還有60%。這就等于說,用視覺當(dāng)媒介,真的可以高效地壓縮文本信息。

在DeepSeek-OCR之前,業(yè)界在怎么讓模型“看”圖這件事上,已經(jīng)摸索了很久,主流的視覺語言模型(VLMs)里,視覺編碼器大概有三種玩法,但家家有本難念的經(jīng)。

第一種是“雙塔架構(gòu)”,代表是Vary。它搞了兩個(gè)并行的編碼器,像兩個(gè)塔一樣,一個(gè)專門處理高分辨率圖像。這么做雖然參數(shù)和內(nèi)存都還算可控,但部署起來就麻煩了,等于要預(yù)處理兩次圖像,訓(xùn)練的時(shí)候想讓兩個(gè)編碼器步調(diào)一致也很困難。
第二種是“切片大法”,代表是InternVL2.0。這方法簡單粗暴,遇到大圖就切成一堆小圖塊,并行計(jì)算。激活內(nèi)存是降下來了,也能處理超高分辨率的圖。但問題是,它本身編碼器的原生分辨率太低,一切起圖來就剎不住車,一張大圖被切得七零八落,產(chǎn)生一大堆視覺token,反而得不償失。
第三種是“自適應(yīng)分辨率”,代表是Qwen2-VL。這種編碼器比較靈活,能處理各種分辨率的圖像,不用切片。聽起來很美,可一旦遇到真正的大圖,GPU內(nèi)存就瞬間爆掉。而且訓(xùn)練的時(shí)候,要把不同尺寸的圖像打包在一起,序列長度會(huì)變得特別長,訓(xùn)練效率極低。
這些模型都在各自的路上狂奔,增強(qiáng)文檔光學(xué)字符識(shí)別(OCR)的能力,但似乎都忽略了一個(gè)根本問題:一篇一千個(gè)單詞的文檔,到底最少需要多少個(gè)視覺token才能完美解碼?
DeepSeek-OCR的突破
DeepSeek-OCR的架構(gòu)設(shè)計(jì)就是沖著解決這個(gè)問題去的。它也是一個(gè)端到端的視覺語言模型,一個(gè)編碼器加一個(gè)解碼器,結(jié)構(gòu)清晰。

它的核心武器是一個(gè)叫DeepEncoder的編碼器,參數(shù)量大約3.8億。這編碼器是把兩個(gè)業(yè)界大神SAM-base(8000萬參數(shù))和CLIP-large(3億參數(shù))給串聯(lián)了起來。可以把它想象成一個(gè)兩級(jí)流水線。
第一級(jí)主要靠窗口注意力的視覺感知組件,用SAM-base改造。它負(fù)責(zé)初步提取圖像特征。
第二級(jí)具有密集全局注意力的視覺知識(shí)組件,用CLIP-large改造。它負(fù)責(zé)深度理解和壓縮這些特征。
為了讓這兩位大神能合作愉快,研究團(tuán)隊(duì)在它們中間加了一個(gè)2層的卷積模塊,作用是把視覺token進(jìn)行16倍的下采樣。
舉個(gè)例子。一張1024×1024的圖像輸進(jìn)去,編碼器先把它切成4096個(gè)小塊(補(bǔ)丁token)。第一級(jí)流水線處理這4096個(gè)token,因?yàn)閰?shù)量不大而且主要是窗口注意力,內(nèi)存還扛得住。在進(jìn)入第二級(jí)全局注意力之前,這4096個(gè)token先被壓縮模塊“擠了一下水分”,變成了256個(gè)。這樣一來,計(jì)算量最大的全局注意力部分處理的token數(shù)就大大減少,整體的激活內(nèi)存就控制住了。
為了能測(cè)試不同壓縮比下的性能,DeepSeek-OCR還支持多種分辨率模式,跟相機(jī)似的,有小、中、大、超大各種檔位。
原生分辨率模式下,有四個(gè)檔位:Tiny(512×512,64個(gè)token)、Small(640×640,100個(gè)token)、Base(1024×1024,256個(gè)token)和Large(1280×1280,400個(gè)token)。小圖就直接縮放,大圖為了保持長寬比會(huì)進(jìn)行填充,保證圖像信息不失真。

動(dòng)態(tài)分辨率模式更靈活,可以把幾種原生分辨率組合起來用。比如Gundam模式,就是把一張圖切成好幾個(gè)640×640的小塊(局部細(xì)節(jié)),再加一個(gè)1024×1024的全局視圖。這種方法特別適合處理報(bào)紙這種超高分辨率的圖像,既能看清細(xì)節(jié),又不會(huì)因?yàn)榍衅槎a(chǎn)生過多token。
有意思的是,所有這些模式都是用一個(gè)模型訓(xùn)練出來的,實(shí)現(xiàn)了“一機(jī)多能”。
編碼器負(fù)責(zé)壓縮,解碼器就負(fù)責(zé)解壓。DeepSeek-OCR的解碼器用的是自家的DeepSeekMoE,一個(gè)擁有30億參數(shù)規(guī)模、混合專家(MoE)架構(gòu)的模型。它在推理的時(shí)候,只需要激活其中一小部分專家(約5.7億參數(shù)),既有大模型的表達(dá)能力,又有小模型的推理效率,非常適合OCR這種專業(yè)性強(qiáng)的任務(wù)。它的任務(wù),就是看著編碼器給過來的那點(diǎn)兒壓縮后的視覺token,把原始的文本內(nèi)容給一字不差地“腦補(bǔ)”出來。
數(shù)據(jù)是這樣喂出來的
一個(gè)強(qiáng)大的模型背后,必然有海量且優(yōu)質(zhì)的數(shù)據(jù)。DeepSeek-OCR的“食譜”非常豐富,主要分三大類。
第一類是OCR 1.0數(shù)據(jù),占大頭。
這是最基礎(chǔ)的OCR任務(wù),包括文檔和自然場景的文字識(shí)別。團(tuán)隊(duì)從網(wǎng)上扒了大約3000萬頁P(yáng)DF文檔,覆蓋近100種語言,其中中英文占了絕大多數(shù)。
為了讓模型學(xué)得更扎實(shí),他們準(zhǔn)備了兩種“教材”:粗糙版的和精細(xì)版的。粗糙版就是直接從PDF里提取文字,教模型認(rèn)識(shí)光學(xué)文本。精細(xì)版則動(dòng)用了更高級(jí)的布局分析模型和OCR模型來做標(biāo)注,告訴模型哪里是標(biāo)題、哪里是段落,文字和檢測(cè)框怎么對(duì)應(yīng)。

對(duì)于小語種,他們還玩了一手“模型飛輪”,先用少量數(shù)據(jù)訓(xùn)練出一個(gè)小模型,再用這個(gè)小模型去標(biāo)注更多數(shù)據(jù),像滾雪球一樣把數(shù)據(jù)量滾大。
此外,他們還收集了300萬份Word文檔,這種數(shù)據(jù)格式清晰,尤其對(duì)公式和表格的識(shí)別很有幫助。自然場景的OCR數(shù)據(jù)也搞了2000萬,中英文各一半,讓模型不光能看懂“白紙黑字”,也能看懂街邊的廣告牌。
第二類是OCR 2.0數(shù)據(jù),這是進(jìn)階任務(wù)。
主要包括圖表、化學(xué)公式、平面幾何圖形的解析。圖表數(shù)據(jù),他們用程序生成了1000萬張,把圖表解析定義成一個(gè)“看圖說話”的任務(wù),直接輸出HTML格式的表格。化學(xué)公式,利用公開的化學(xué)數(shù)據(jù)庫生成了500萬張圖片。平面幾何圖形也生成了100萬張,還特意做了數(shù)據(jù)增強(qiáng),把同一個(gè)幾何圖形在畫面里挪來挪去,讓模型明白,位置變了,但圖形本身沒變。

第三類是通用視覺數(shù)據(jù),占兩成。
為了讓它保留一些基本的圖像理解能力,比如看圖說話、物體檢測(cè)等,團(tuán)隊(duì)也喂了一些通用視覺數(shù)據(jù)。這主要是為了給未來的研究留個(gè)口子,方便大家在這個(gè)模型的基礎(chǔ)上做二次開發(fā)。
最后,為了保證模型的語言能力不退化,還混入了10%的純文本數(shù)據(jù)一起訓(xùn)練。整個(gè)訓(xùn)練數(shù)據(jù)里,OCR數(shù)據(jù)占70%,通用視覺數(shù)據(jù)占20%,純文本數(shù)據(jù)占10%,配比相當(dāng)講究。
訓(xùn)練過程分兩步走。第一步,單獨(dú)訓(xùn)練DeepEncoder編碼器,讓它先學(xué)會(huì)怎么高效地看圖和壓縮。第二步,把訓(xùn)練好的編碼器和解碼器連在一起,用上面說的數(shù)據(jù)配方,正式訓(xùn)練DeepSeek-OCR。
模型性能測(cè)試
核心的視覺-文本壓縮能力測(cè)試。
研究團(tuán)隊(duì)用了Fox的基準(zhǔn)測(cè)試集,專門挑了那些文本token數(shù)在600到1300之間的英文文檔來測(cè)試。這個(gè)token數(shù),用Tiny模式(64個(gè)視覺token)和Small模式(100個(gè)視覺token)來處理正合適。

表格里的數(shù)據(jù)非常直觀。在10倍壓縮比以內(nèi),模型的解碼精度幾乎沒損失,都在97%左右。
這結(jié)果讓人很興奮,意味著未來也許真的可以通過“文轉(zhuǎn)圖”的方式,實(shí)現(xiàn)接近無損的上下文壓縮。
當(dāng)壓縮比超過10倍,性能開始下降,原因可能是長文檔的排版更復(fù)雜,也可能是圖片分辨率不夠,文字開始模糊了。但即便壓縮到近20倍,精度還能保持在60%上下。
這充分證明了,上下文光學(xué)壓縮這個(gè)方向,大有可為。
接下來是實(shí)際的OCR性能。在另一個(gè)更全面的基準(zhǔn)測(cè)試OmniDocBench上,它的表現(xiàn)同樣亮眼。

從這張密密麻麻的表里能看出,DeepSeek-OCR只用100個(gè)視覺token(Small模式),就超過了用256個(gè)token的GOT-OCR2.0。用不到800個(gè)token的Gundam模式,更是把需要近7000個(gè)token的MinerU2.0甩在身后。這說明DeepSeek-OCR的token效率極高,用更少的資源干了更多的活。
不同類型的文檔,對(duì)視覺token的需求也不一樣。

你看,像幻燈片這種格式簡單的,64個(gè)token的Tiny模式就夠用了。書籍和報(bào)告,100個(gè)token的Small模式也表現(xiàn)不錯(cuò)。
這再次印證了前面的結(jié)論,這些文檔的文本token數(shù)大多在1000以內(nèi),沒超過10倍壓縮比的臨界點(diǎn)。但對(duì)于報(bào)紙這種信息密度極高的文檔,文本token動(dòng)輒四五千,就必須得上Gundam模式甚至更強(qiáng)的模式才行。這些實(shí)驗(yàn)清晰地劃出了上下文光學(xué)壓縮的適用邊界。
除了能打的性能,DeepSeek-OCR還有很多“才藝”。它能進(jìn)行“深度解析”,比如識(shí)別出文檔里的圖表,并把它轉(zhuǎn)換成結(jié)構(gòu)化的數(shù)據(jù)。

還能看懂化學(xué)公式,并把它轉(zhuǎn)成SMILES格式。

它還能處理近100種語言的文檔。

當(dāng)然,作為VLM,基本的看圖說話、物體檢測(cè)等通用能力也都在線。

未來的想象空間還很大
DeepSeek-AI團(tuán)隊(duì)的這項(xiàng)工作,是對(duì)視覺-文本壓縮邊界的一次成功探索。10倍壓縮比下接近無損,20倍壓縮比下仍能看,這個(gè)結(jié)果足夠讓人興奮。
這為未來打開了一扇新的大門。
比如,在多輪對(duì)話中,可以把幾輪之前的對(duì)話歷史渲染成一張圖片存起來,實(shí)現(xiàn)10倍的壓縮效率。對(duì)于更久遠(yuǎn)的上下文,還可以通過逐步縮小圖片分辨率來進(jìn)一步減少token消耗。
這個(gè)過程,很像人腦的記憶機(jī)制。剛發(fā)生的事情記得清清楚楚,細(xì)節(jié)分明。時(shí)間久遠(yuǎn)的事情,就只剩下個(gè)模糊的輪廓。通過這種光學(xué)壓縮的方式,我們可以模擬出一條生物學(xué)的遺忘曲線,讓模型在處理超長上下文時(shí),能把寶貴的計(jì)算資源留給最重要的近期信息,同時(shí)又不會(huì)完全“忘記”過去,實(shí)現(xiàn)了信息保留和計(jì)算成本之間的完美平衡。
僅靠OCR任務(wù)還不足以完全驗(yàn)證光學(xué)壓縮的全部潛力,未來還需要更多更復(fù)雜的測(cè)試。
DeepSeek-OCR已經(jīng)證明,上下文光學(xué)壓縮是一個(gè)非常有前景的新方向,它可能為解決大型語言模型“記性差”這個(gè)老大難問題,提供一把全新的鑰匙。