整體生成 × 精準控制:HoloCine 如何實現分鐘級電影敘事?

大家好,我是肆〇柒。今天我們一起了解一項來自香港科技大學(HKUST)與螞蟻集團(Ant Group)聯合團隊的創新研究——HoloCine。這項研究首次實現了分鐘級、多鏡頭、高一致性的電影級視頻整體生成,不僅在Transition Control指標上達到0.9837(遠超現有方法),更展現出對鏡頭語言、角色記憶甚至電影術語的“理解”能力。它標志著AI視頻生成正從“片段合成”邁向“自動拍片”的新階段。
當前最先進的文本到視頻(Text-to-Video, T2V)模型雖能生成高質量的5秒單鏡頭視頻,卻難以構建電影敘事的核心要素——連貫的多鏡頭序列。這一斷層被研究者明確界定為"敘事鴻溝":現有技術擅長生成孤立片段,卻無法創造連貫、多鏡頭的敘事,而后者正是講故事的本質。HoloCine的突破性進展首次實現了分鐘級、多鏡頭、高一致性的電影級視頻整體生成,其Transition Control指標達到0.9837,遠超次優方法的0.5370。這一技術不僅解決了長期困擾行業的連貫敘事難題,更標志著AI視頻生成從"片段合成"邁向"導演場景"的范式轉變,為自動化影視創作開辟了全新路徑。

多鏡頭視頻敘事示例
從上圖可見,僅憑文本提示,HoloCine就能生成連貫的電影級多鏡頭視頻敘事。圖中展示了模型的多樣性能力,包括原創場景(上三行)和對《泰坦尼克號》的電影致敬(下三行)。所有場景均展現出卓越的角色一致性和敘事連貫性,底部擴展行則展示了鏡頭內平滑的運動和質量。這一成果證明了模型在單一生成過程中實現多鏡頭敘事的可能性。
當前 T2V 模型的根本局限
電影、電視劇和紀錄片并非單個長鏡頭的簡單延續,而是由多個不同鏡頭通過剪輯組合而成的敘事結構。當前最先進的文本到視頻模型雖能生成高質量的單鏡頭視頻,卻缺乏構建連貫多鏡頭敘事的能力。這一根本性斷層構成了生成式AI在視覺媒體領域應用的關鍵瓶頸。
現有解決方案主要面臨三重挑戰。分段生成方法通過逐塊生成長視頻,不可避免地導致誤差累積和視覺質量隨長度下降;兩階段方法先創建關鍵幀再獨立合成連接鏡頭,雖然能在關鍵幀層面保障一致性,但各鏡頭的視頻填充仍孤立進行。

定量結果。最佳和亞軍結果以加粗和下劃線標出
如上表所示,Wan2.2單獨模型的Inter-shot Consistency為0.6772,而StoryDiffusion與Wan2.2結合后提升至0.8487,但仍低于HoloCine的0.7509。這一數據差異揭示了關鍵問題:兩階段方法在鏡頭間一致性上存在固有局限,如下圖中中Shot 4-5的人物特征變化所示。StoryDiffusion和IC-LoRA都生成了男孩和女人在一起的中景鏡頭,而非預期的特寫。更嚴重的是,它們在Shot 4-5中角色特征明顯漂移,證明了兩階段方法在長程一致性上的不足。

多鏡頭生成對比
上圖直觀展示了現有方法的局限。基礎模型Wan2.2無法理解多鏡頭指令,僅生成靜態單鏡頭;兩階段方法StoryDiffusion和IC-LoRA雖能生成不同圖像,但在提示保真度和長程一致性上表現不佳。例如,提示要求Shot 2為"Medium close-up of woman's pensive expression",但這兩個方法都生成了男孩和女人在一起的中景鏡頭。更關鍵的是,它們在Shot 4-5中角色特征明顯漂移——同一角色的發型、服裝和面部特征發生不一致變化。這些缺陷源于兩階段方法的本質:關鍵幀生成與視頻填充分離進行,導致視覺屬性隨鏡頭數量增加而退化。
更根本的問題是"控制稀釋"。大家可能會問:為什么不能簡單地將多個鏡頭提示拼接起來讓模型生成?答案是"控制稀釋"問題——當使用全局提示指導多鏡頭生成時,針對特定鏡頭的指令在整體上下文中被稀釋,難以實現精確的鏡頭內容控制與轉場。
整體生成范式為解決這些問題提供了新思路。以LCT為例,這種方法將整個多鏡頭序列在一個統一的擴散過程中聯合建模,天然保障了全局一致性。然而,這一方向面臨兩大挑戰:如何實現精確的導演控制,以及如何克服自注意力機制帶來的計算瓶頸——其復雜度隨序列長度呈平方級增長,使分鐘級視頻生成變得不切實際。HoloCine通過兩項創新性架構設計,成功解鎖了整體生成范式的潛力。
HoloCine 的核心突破:整體生成 × 精準控制 × 高效計算
HoloCine通過三大技術支柱,構建了完整的多鏡頭敘事生成框架:整體生成基礎、精準導演控制和高效計算機制。這三大要素協同工作,使分鐘級多鏡頭視頻的整體生成成為可能。
在整體生成框架中,所有鏡頭的潛在表示在擴散模型中同步處理。通過共享的自注意力機制,模型自然維持長程一致性,確保角色身份、背景細節和整體風格在鏡頭邊界處保持連貫。這一框架建立在強大的14B參數wan2.2模型基礎上,為分鐘級視頻生成提供了堅實基礎。

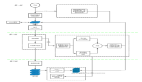
整體架構設計
上圖展示了HoloCine的整體架構。左側是分層提示處理流程:全局提示與各鏡頭提示被拼接,通過[shot cut] token明確界定邊界;中間是核心的注意力機制:Window Cross-Attention確保每鏡頭僅關注相關提示,Sparse Inter-Shot Self-Attention實現高效的鏡頭間通信;右側是視頻生成結果,展示了平滑的鏡頭過渡和一致的角色表現。這一設計的關鍵在于將文本提示結構與視頻生成過程對齊,使模型能理解"鏡頭1:中景,鏡頭2:特寫"等指令的精確含義。
HoloCine通過一種創新的稀疏注意力模式,將計算復雜度從O(L2)降低到近線性,使分鐘級視頻的整體生成成為可能。這種模式的核心思想是:鏡頭內需要密集連接保證動作流暢,鏡頭間則可通過稀疏摘要實現高效通信。


整體架構設計

HoloCine的數據構建是實現整體生成的關鍵基礎。如上圖所示,通過將鏡頭邊界檢測、嚴格過濾和分層標注相結合,HoloCine構建了40萬樣本的多鏡頭數據集,其中[shot cut] token的引入使模型能夠明確識別鏡頭邊界,這是實現精確鏡頭切換的基礎。上圖展示了完整的數據處理流程:首先使用鏡頭邊界檢測算法分割影視內容;然后嚴格過濾掉含字幕、過短、過暗或美學評分低的片段;接著按5s/15s/60s目標時長聚合連續鏡頭,形成多樣化樣本;最后通過Gemini 2.5 Flash進行分層標注。這種分層標注結構包含三個關鍵元素:全局提示描述整體場景(角色、環境、劇情);各鏡頭提示詳述具體動作、攝像機運動;[shot cut] token明確界定鏡頭邊界。這一設計使模型既能理解全局敘事,又能執行精確的鏡頭級控制。
實證效果:不只是"看起來不錯"


定量評估結果對比
上表全面展示了HoloCine與其他方法的性能對比。在Transition Control指標上,HoloCine達到0.9837,遠超CineTrans的0.5370和StoryDiffusion的0.7364,表明其在鏡頭切換控制上的顯著優勢。Inter-shot Consistency指標為0.7509,略低于StoryDiffusion+Wan2.2的0.8487,但高于Wan2.2單獨模型的0.6772。值得注意的是,雖然StoryDiffusion在Aesthetic Quality上略勝一籌(0.5773 vs 0.5598),但這恰恰反映了HoloCine的取舍——犧牲微小的美學質量換取敘事連貫性,而這正是電影敘事的核心需求。

消融實驗結果
上表的消融實驗提供了關鍵點。完全移除Window Cross-Attention(WO WINDOW)導致Transition Control從0.9736降至0.6266,證明了該機制對鏡頭控制的必要性。這一下降意味著鏡頭切換的準確性從"幾乎完美"降至"嚴重錯誤"——在10次鏡頭切換中,有近4次無法正確執行,導致敘事斷裂。使用全自注意力(FULL ATT WINDOW)雖能達到0.8923的Transition Control,但計算成本過高;而稀疏注意力(SPARSE)在Transition Control上僅輕微下降(0.9736 vs 0.8923),卻大幅提升了效率。特別值得注意的是,移除跨鏡頭摘要token(SPARSE ZERO)導致Inter-shot Consistency從0.7225降至0.6761,證明了這一機制對維持角色一致性的關鍵作用。

消融實驗定性結果
上圖的消融實驗揭示了各組件的關鍵作用。移除Window Cross-Attention(第一行)導致模型無法執行鏡頭切換,忽略新內容提示(如Shot 3的特寫),并鎖定在初始場景中。這一結果證明了Window Cross-Attention對實現精確鏡頭控制的必要性。使用全自注意力(第二行)雖能生成高質量視頻,但計算成本過高;而稀疏注意力(第四行)在美學質量上僅輕微下降(0.5693 vs 0.5700),卻大幅提升了可擴展性。最嚴重的是移除跨鏡頭摘要token(第三行),導致角色一致性完全崩潰——老人的身份和外觀在不同鏡頭間發生劇烈變化,這一結果證明了Sparse Inter-Shot Self-Attention中摘要token的關鍵作用——它們作為鏡頭間的"記憶橋梁",使模型能夠在不同鏡頭間保持角色一致性。沒有這些橋梁,每個鏡頭就像孤立的島嶼,無法形成連貫敘事。

商業模型對比
上圖定性對比直觀展示了HoloCine的技術優勢。基礎模型Wan2.2無法理解多鏡頭指令,僅生成靜態單鏡頭;兩階段方法StoryDiffusion和IC-LoRA雖能生成不同圖像,但在提示保真度和長程一致性上表現不佳。例如,提示要求Shot 2為"Medium close-up of woman's pensive expression",但這兩個方法都生成了男孩和女人在一起的中景鏡頭。它們在Shot 4-5中角色特征明顯漂移的問題尤為突出。CineTrans雖嘗試整體生成,卻無法正確執行復雜鏡頭轉換,畫面質量顯著下降。相比之下,HoloCine成功解析分層提示,生成五個不同鏡頭的連貫序列,每個鏡頭都精確匹配相應文本描述,同時在整個視頻中保持高角色和風格一致性。
更值得注意的是與商業模型的對比:Vidu和Kling 2.5 Turbo完全無法解析多鏡頭指令,僅生成單鏡頭視頻;而HoloCine與Sora 2表現相當,均能準確執行"從中景到特寫"的鏡頭轉換,這是開源模型首次在敘事能力上媲美頂級閉源方案。上圖清晰展示了這一差異:HoloCine成功執行了從人物中景到面部特寫的鏡頭轉換,同時保持角色一致性,而商業模型則無法理解這一指令。
在訓練細節上,HoloCine在128塊NVIDIA H800 GPU上訓練10k步(學習率1×10??),采用混合并行策略:使用Fully Sharded Data Parallelism(FSDP)分片模型參數,結合Context Parallelism(CP)分割長序列。該模型支持5秒、15秒和60秒不同長度的視頻生成,最多包含13個鏡頭,為實際應用提供了靈活選擇。
超越生成:涌現能力揭示模型"理解"敘事
HoloCine展現出令人驚訝的涌現能力,表明模型不僅學習了表面視覺轉換,還構建了對場景和對象的隱式持久表征。

模型持久記憶能力
上圖揭示了HoloCine令人驚訝的持久記憶能力。在角色身份跨視角一致性方面(a),藝術家的金發、灰色T恤和圍裙在不同角度和表情的鏡頭中保持高度一致;在長程重現能力上(b),教授在Shot 1引入后,經Shot 2(圖書館環境)干擾,Shot 5中仍能準確重現,證明模型具有超越相鄰鏡頭的記憶能力;最引人注目的是細粒度細節記憶能力(c),背景中的藍色磁鐵(非顯著元素)在Shot 1和Shot 5中位置完全一致,表明模型具備對場景的全面理解。這些能力并非顯式編程,而是從數據中自然涌現的。這一細粒度記憶能力表明模型不僅關注主要角色,還構建了對場景的完整理解,這是實現真實電影敘事的關鍵——在專業電影制作中,道具的連續性是保證敘事可信度的基本要求。

電影語言控制能力
上圖展示了HoloCine對電影語言的精確控制。在鏡頭尺度控制方面(a),模型能準確生成Long/Medium/Close-up鏡頭,符合電影工業定義;對于攝像機角度(b),模型能精確響應Low-angle/Eye-level/High-angle指令;對于攝像機運動(c),模型執行Tilt up(向上傾斜)時,生成了從樹根到樹冠的平滑垂直運動,準確捕捉了這一電影術語的含義;Dolly out(后拉)則使相機向后移動,逐步揭示藝術家工作室的全貌;Tracking則正確跟隨主體移動,保持鷹在畫面中心。這一對專業電影語言的理解表明,HoloCine已發展出對電影語言的隱式理解,能夠將文本指令轉化為符合電影規范的視覺表達。
局限與啟示
盡管HoloCine在視覺一致性方面表現出色,但在因果推理能力上仍有明顯局限。

因果推理失敗案例
上圖揭示了HoloCine的深層局限。面對"空杯→倒水→結果"的場景序列,模型無法理解動作的物理后果:Shot 1顯示空杯,Shot 2展示倒水動作,但Shot 3仍渲染為空杯狀態。這一失敗表明模型優先考慮與初始鏡頭的視覺一致性,而非動作的邏輯結果。這一局限源于HoloCine的訓練目標——它被優化為保持視覺一致性,而非物理邏輯。在訓練數據中,鏡頭間可能存在視覺相似但物理狀態不同的場景,模型學習到的是"保持初始狀態"而非"執行物理變化"。對于希望將HoloCine應用于需要物理常識的場景(如產品演示、教育視頻)的開發者,需要額外添加因果推理模塊,或在提示中明確指定結果狀態。這一局限意味著HoloCine難以生成需要物理連貫性的場景,如"倒水→水杯變滿"或"推門→門打開"等因果序列。在實際應用中,創作者需特別注意避免這類需要物理推理的敘事場景。
這一局限為未來研究指明了方向:需要將物理常識與視覺一致性相結合,推動模型從感知一致性向邏輯因果推理演進。同時,HoloCine提出的稀疏注意力模式為長視頻生成提供了新思路,其分層提示結構也證明是實現精準導演控制的關鍵要素。
范式躍遷的意義
HoloCine不僅彌合了"敘事鴻溝",更標志著從"片段合成"到"導演場景"的范式轉變。通過整體生成框架,模型能夠理解并執行電影敘事語言。對工業界而言,這一技術為自動化短視頻制作、影視預演和游戲過場提供了新工具;對學術界而言,"整體生成+結構稀疏注意力"的架構范式為解決長視頻生成的計算瓶頸提供了新思路。
HoloCine代表了通向自動化電影制作的關鍵一步,使端到端電影生成成為一個切實可行的未來。這一進展不僅推動了技術邊界,更重新定義了AI在創意產業中的角色——從工具到協作者,最終可能成為真正的"數字導演"。