從 “一刀切” 到 “精準(zhǔn)篩”:DeepSieve 用四步流水線重構(gòu) RAG,告別檢索噪聲!

在大語言模型(LLMs)主導(dǎo)的AI時(shí)代,知識(shí)密集型任務(wù)始終面臨一個(gè)核心矛盾:LLM擅長(zhǎng)復(fù)雜推理,但受限于固定參數(shù)無法動(dòng)態(tài)獲取最新或領(lǐng)域?qū)僦R(shí);檢索增強(qiáng)生成(RAG)雖能鏈接外部知識(shí),卻常因“一刀切”的檢索邏輯陷入噪聲冗余、推理淺薄的困境。
來自羅格斯大學(xué)、西北大學(xué)與NEC實(shí)驗(yàn)室的團(tuán)隊(duì)提出的DeepSieve,創(chuàng)新性地將LLM作為“知識(shí)路由器”,通過多階段信息篩選機(jī)制,為異構(gòu)知識(shí)源與復(fù)雜查詢的精準(zhǔn)匹配提供了新解法。本文將帶您深入拆解這一方案的設(shè)計(jì)思路與實(shí)驗(yàn)效果。
論文地址:https://arxiv.org/pdf/2507.22050
項(xiàng)目代碼:https://github.com/MinghoKwok/DeepSieve
01、為什么需要DeepSieve?RAG的兩大核心痛點(diǎn)
現(xiàn)有RAG系統(tǒng)雖能緩解LLM的“知識(shí)過時(shí)”問題,但在處理真實(shí)場(chǎng)景任務(wù)時(shí),存在難以逾越的兩大障礙:
1. query側(cè):復(fù)雜查詢被“一刀切”
多數(shù)RAG將用戶查詢視為“原子單元”,直接送入檢索器匹配。例如面對(duì)“誰是尼日利亞空中醫(yī)生服務(wù)創(chuàng)始人的丈夫”這類嵌套查詢,系統(tǒng)無法拆解“先找創(chuàng)始人→再查其配偶”的推理鏈,要么返回?zé)o關(guān)信息,要么直接 hallucinate 出虛假答案。
2. 知識(shí)源側(cè):異構(gòu)信息難兼容
真實(shí)世界的知識(shí)源高度多樣:既有非結(jié)構(gòu)化的文檔庫,也有結(jié)構(gòu)化的SQL數(shù)據(jù)庫,還有需API調(diào)用的實(shí)時(shí)數(shù)據(jù)(如天氣、地圖)。傳統(tǒng)RAG將所有源合并為統(tǒng)一索引,不僅因格式?jīng)_突丟失信息,還會(huì)因隱私限制(如企業(yè)私有數(shù)據(jù)庫)無法實(shí)現(xiàn);更糟的是,檢索時(shí)不區(qū)分源特性,比如用文本檢索處理“19世紀(jì)出生的放射性發(fā)現(xiàn)者”這類需時(shí)間篩選的問題,效率極低。
而DeepSieve的核心目標(biāo),就是通過結(jié)構(gòu)化分解查詢與源感知路由,實(shí)現(xiàn)“查詢按需拆、知識(shí)精準(zhǔn)取”。

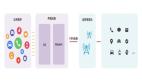
02、DeepSieve的核心設(shè)計(jì):四階段信息篩選流水線
DeepSieve的本質(zhì)是一套“模塊化、可迭代”的檢索推理框架,通過四個(gè)核心階段完成從復(fù)雜查詢到精準(zhǔn)答案的轉(zhuǎn)化,整體流程如圖所示:

關(guān)鍵符號(hào)定義
- Q:原始復(fù)雜查詢(如“尼日利亞空中醫(yī)生服務(wù)創(chuàng)始人的丈夫是誰”)
 :知識(shí)源集合,
:知識(shí)源集合, 是工具(如SQL、RAG檢索器),
是工具(如SQL、RAG檢索器), 是對(duì)應(yīng)語料庫(如員工數(shù)據(jù)庫、維基文檔)
是對(duì)應(yīng)語料庫(如員工數(shù)據(jù)庫、維基文檔)- 核心操作:分解→路由→檢索→反思→融合
階段1:Query分解——把復(fù)雜問題拆成“可解單元”
第一步是將原始查詢轉(zhuǎn)化為結(jié)構(gòu)化的子問題有向無環(huán)圖(DAG)。例如:
- 原始查詢:“誰是尼日利亞空中醫(yī)生服務(wù)創(chuàng)始人的丈夫?”
- 分解結(jié)果:
 :誰創(chuàng)立了尼日利亞空中醫(yī)生服務(wù)?
:誰創(chuàng)立了尼日利亞空中醫(yī)生服務(wù)? :該創(chuàng)始人的丈夫是誰?
:該創(chuàng)始人的丈夫是誰?
這里的關(guān)鍵是用LLM作為“規(guī)劃器”,確保每個(gè)子問題 僅對(duì)應(yīng)一個(gè)“可檢索事實(shí)”,且DAG的邊能體現(xiàn)子問題間的依賴關(guān)系(如
僅對(duì)應(yīng)一個(gè)“可檢索事實(shí)”,且DAG的邊能體現(xiàn)子問題間的依賴關(guān)系(如 依賴
依賴 的結(jié)果)。這一步就像把“拆快遞”的復(fù)雜動(dòng)作,拆解為“找快遞單→核對(duì)地址→拆包裝”的明確步驟。
的結(jié)果)。這一步就像把“拆快遞”的復(fù)雜動(dòng)作,拆解為“找快遞單→核對(duì)地址→拆包裝”的明確步驟。
階段2:知識(shí)路由——LLM當(dāng)“路由器”,子問題匹配最優(yōu)源
對(duì)每個(gè)子問題 ,LLM會(huì)根據(jù)三個(gè)維度選擇最優(yōu)(工具-語料庫)對(duì):
,LLM會(huì)根據(jù)三個(gè)維度選擇最優(yōu)(工具-語料庫)對(duì):
 的語義:比如“創(chuàng)始人是誰”是實(shí)體查詢,“丈夫是誰”是個(gè)人關(guān)系查詢;
的語義:比如“創(chuàng)始人是誰”是實(shí)體查詢,“丈夫是誰”是個(gè)人關(guān)系查詢;- 知識(shí)源 profile:每個(gè)源會(huì)標(biāo)注領(lǐng)域(如“員工數(shù)據(jù)庫-存儲(chǔ)個(gè)人信息”“維基文檔-通用知識(shí)”)、格式(SQL/文本)、隱私級(jí)別;
- 歷史失敗記錄:若某源曾檢索失敗(如查“創(chuàng)始人丈夫”用維基無果),則優(yōu)先避開。
仍以“空中醫(yī)生”查詢?yōu)槔?/span>
 (找創(chuàng)始人)→ 路由到“維基文檔+RAG檢索器”(通用知識(shí)源);
(找創(chuàng)始人)→ 路由到“維基文檔+RAG檢索器”(通用知識(shí)源); (找丈夫)→ 路由到“本地人物數(shù)據(jù)庫+SQL工具”(私有個(gè)人信息源)。
(找丈夫)→ 路由到“本地人物數(shù)據(jù)庫+SQL工具”(私有個(gè)人信息源)。
這種“按需分配”的邏輯,徹底避免了傳統(tǒng)RAG“用文本檢索查結(jié)構(gòu)化數(shù)據(jù)”的低效問題。
階段3:觀察與反思——檢索失敗時(shí)的“自我修正”
檢索到子答案 后,LLM會(huì)先判斷其是否“有效”(如是否完整、是否相關(guān))。若無效(如
后,LLM會(huì)先判斷其是否“有效”(如是否完整、是否相關(guān))。若無效(如 檢索到“無公開信息”),則觸發(fā)“反思循環(huán)”:
檢索到“無公開信息”),則觸發(fā)“反思循環(huán)”:
- 不修改子問題本身,而是重新路由(如從“本地?cái)?shù)據(jù)庫”切換到“社交媒體文檔庫”);
- 所有嘗試結(jié)果會(huì)存入記憶模塊MMM:成功結(jié)果
 (如
(如 的“創(chuàng)始人是Ola Orekunrin”)用于最終融合,失敗結(jié)果
的“創(chuàng)始人是Ola Orekunrin”)用于最終融合,失敗結(jié)果 (如“維基查丈夫無果”)用于后續(xù)避坑。
(如“維基查丈夫無果”)用于后續(xù)避坑。
這一步讓DeepSieve具備了“抗錯(cuò)能力”,而非像傳統(tǒng)RAG那樣“一次檢索定生死”。
階段4:答案融合——從子答案到連貫響應(yīng)
所有子問題解決后,LLM會(huì)基于DAG的依賴關(guān)系,將 中的子答案聚合為最終答案。例如:
中的子答案聚合為最終答案。例如:
- 子答案1:Ola Orekunrin創(chuàng)立了尼日利亞空中醫(yī)生服務(wù);
- 子答案2:未檢索到Ola Orekunrin丈夫的公開信息;
- 最終答案:尼日利亞空中醫(yī)生服務(wù)的創(chuàng)始人是Ola Orekunrin,目前暫無其丈夫的公開記錄。
若子答案存在沖突(如不同源對(duì)“創(chuàng)始人”有不同說法),LLM還會(huì)進(jìn)行全局推理,優(yōu)先選擇高可信度源的信息。

模塊化優(yōu)勢(shì):即插即用,靈活擴(kuò)展
DeepSieve的每個(gè)階段都是獨(dú)立模塊,可按需替換:
- 檢索器:支持BM25、FAISS、ColBERTv2等;
- 知識(shí)源:新增“實(shí)時(shí)天氣API”只需注冊(cè)工具和profile,無需修改整體流程;
- LLM backbone:可切換DeepSeek-V3、GPT-4o等模型。
這種設(shè)計(jì)讓它既能適配學(xué)術(shù)場(chǎng)景的“多跳問答”,也能落地工業(yè)場(chǎng)景的“企業(yè)私有知識(shí)檢索”。
03、實(shí)驗(yàn)驗(yàn)證:性能與效率雙超越
團(tuán)隊(duì)在三個(gè)經(jīng)典多跳問答基準(zhǔn)(MuSiQue、2WikiMultiHopQA、HotpotQA)上做了全面測(cè)試,核心回答四個(gè)問題:
性能是否超越傳統(tǒng)RAG?(RQ1)
在DeepSeek-V3作為 backbone 時(shí):
- MuSiQue數(shù)據(jù)集:DeepSieve(Naive RAG)F1分?jǐn)?shù)46.8,比IRCoT+HippoRAG(傳統(tǒng)RAG組合)高13.5;
- 2WikiMultiHopQA數(shù)據(jù)集:F1分?jǐn)?shù)68.4,比傳統(tǒng)組合高5.3;
- 平均F1 58.9,超越所有純RAG和智能體RAG(如ReAct、Reflexion)基線。
即使切換到GPT-4o,DeepSieve在HotpotQA的F1仍達(dá)61.7,遠(yuǎn)超CoT(30.8)、ReAct(39.6)等方法。
實(shí)驗(yàn)結(jié)果表明,DeepSieve在多個(gè)多跳問答數(shù)據(jù)集上顯著提高了答案準(zhǔn)確性。

推理成本是否更低?(RQ2)
Token效率是工業(yè)落地的關(guān)鍵指標(biāo)。實(shí)驗(yàn)顯示,DeepSieve在HotpotQA上:
- 平均每查詢僅用3.9K Token;
- 而Reflexion(智能體RAG)需37.9K Token,ReAct需9.8K Token;

- 雷達(dá)圖顯示,DeepSieve在“F1分?jǐn)?shù)、EM分?jǐn)?shù)、Token效率”三個(gè)維度的綜合表現(xiàn)最優(yōu),是“精準(zhǔn)與高效”的平衡者。

結(jié)果表明,DeepSieve使用的Token數(shù)明顯少于其他基于大語言模型的系統(tǒng),同時(shí)實(shí)現(xiàn)了更高的準(zhǔn)確性,表現(xiàn)出很強(qiáng)的成本效益。
各模塊的貢獻(xiàn)有多大?(RQ3)
消融實(shí)驗(yàn)揭示了三個(gè)核心模塊的價(jià)值:
- 分解模塊:移除后MuSiQue的F1下降17.5分,證明“拆查詢”是多跳推理的基礎(chǔ);
- 反思模塊:移除后2WikiMultiHopQA的F1從68.4暴跌至15.4,說明“自我修正”對(duì)處理噪聲至關(guān)重要;
- 路由模塊:?jiǎn)为?dú)使用時(shí)效果有限,但與前兩者結(jié)合后,能顯著提升異構(gòu)源場(chǎng)景的魯棒性(如跨SQL和文本源檢索)。
驗(yàn)結(jié)果")


結(jié)果表明,分解和反思是準(zhǔn)確性的關(guān)鍵。單獨(dú)的路由可能表現(xiàn)不佳,但結(jié)合使用時(shí),它在不犧牲性能的情況下提高了魯棒性,并能處理異構(gòu)知識(shí)源。
能否適配不同知識(shí)源?(RQ4)
測(cè)試了兩種檢索設(shè)置(Naive RAG、GraphRAG)和兩種知識(shí)源(本地+全局拆分的異構(gòu)源、統(tǒng)一源):
- 在異構(gòu)源場(chǎng)景:DeepSieve的F1比傳統(tǒng)RAG高8-12分;
- 在統(tǒng)一源場(chǎng)景:仍比傳統(tǒng)RAG高5-7分,證明其不僅適配多源,還能優(yōu)化單源檢索;
- 新增SQL源后:無需修改核心邏輯,僅注冊(cè)工具即可支持“19世紀(jì)放射性發(fā)現(xiàn)者”這類需篩選的查詢,F(xiàn)1達(dá)59.1,接近專家Oracle的性能。

04、總結(jié):DeepSieve的價(jià)值與未來方向
核心價(jià)值
- 解決RAG痛點(diǎn):通過“分解+路由”終結(jié)“檢索噪聲”,通過“反思”提升抗錯(cuò)能力;
- 兼顧性能與效率:在三個(gè)基準(zhǔn)上實(shí)現(xiàn)F1最優(yōu),同時(shí)Token成本僅為Reflexion的1/10;
- 工業(yè)級(jí)適配性:模塊化設(shè)計(jì)支持SQL、API、文本等多源,隱私數(shù)據(jù)無需合并索引。
未來可探索方向
- 細(xì)粒度路由:當(dāng)前僅選擇(工具-語料庫)對(duì),未來可擴(kuò)展到工具參數(shù)(如檢索深度、API調(diào)用模式);
- 個(gè)性化適配:針對(duì)不同用戶(如醫(yī)生vs學(xué)生)定制知識(shí)源優(yōu)先級(jí),實(shí)現(xiàn)“千人千面”的檢索;
- 成本感知:在路由時(shí)加入成本權(quán)重(如API調(diào)用費(fèi)vs本地檢索),進(jìn)一步優(yōu)化工業(yè)落地成本。