6666!NeurIPS滿分論文來了
四個審稿人全給6分,NeurIPS唯一滿分論文炸了!
之所以說它炸,主要是論文給出的結論實在太出人意料了——
真正決定推理上限的是基座模型本身而非強化學習,且蒸餾比強化學習更有望實現大模型自我進化。
好家伙,這無異于給正炙手可熱的RLVR(可驗證獎勵的強化學習)迎面潑下一盆冷水~
RLVR,自大模型推理范式開啟后就成為一眾主流模型(如OpenAI-o1、DeepSeek-R1)的核心驅動力。
由于無需人工標注,通過自動驗證獎勵優化模型,它一度被視為實現模型自我進化、逼近更高推理能力的終極路徑。
但來自清華上交的這篇論文,卻讓風向陡然生變——
如果進化的鑰匙不在強化學習,那當前圍繞RLVR的巨額投入與探索,意義何在?

真正能突破推理上限:蒸餾而非強化學習
這篇論文題目為《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? 》,“獲NeurIPS唯一滿分”的結論由PaperCopilot(非官方論文分析平臺)統計得出。
同時它還榮獲ICML 2025 AI4Math Workshop最佳論文獎,并入選NeurIPS 2025大會口頭報告。

之所以提出這項研究,主要是近年來RLVR在大語言模型中被廣泛應用于提升數學、編程、視覺推理等任務的表現。
隨之而來的是,AI圈普遍假設——
RLVR不但能提升推理效率,還可能擴展模型的推理能力,即讓模型學會底層基礎模型本來不會的新推理路徑。
但問題是,這一結論真的成立嗎?
于是帶著疑問,來自清華上交的研究團隊核心想要弄清一個問題:
RLVR是否真的讓大語言模型超越其“底模”推理能力邊界,還是只是優化已有能力?
而通過一系列實驗,團隊得出以下最新結論:
- RLVR主要是在“強化”底模已有的路徑,而不是“發現”底模沒有的路徑。
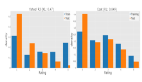
- RL訓練后的模型在低采樣次數(如pass@1)表現更好,但隨著采樣次數增加(pass@64、pass@256…),底模反而能超過RL模型,這說明底模隱藏的推理能力被低估了。
- 多種RL算法(如PPO、GRPO、Reinforce++等)在提升采樣效率方面差異不大,且與“理論上底模最大能力”相比,仍有明顯差距,這說明想靠RL突破底模上限還不夠。
- 蒸餾方法更有可能“擴展”模型的推理能力范圍,因為其接收來自教師模型的新推理模式,而RLVR更受限于底模。

換句話說,與普遍認知相反,RLVR的實際作用很可能被嚴重高估了。

關鍵評估指標:pass@k
而為了得出上述結論,他們采用了pass@k這一關鍵評估指標。
所謂pass@k,是指衡量一個模型在多次嘗試中,至少成功一次的幾率。
相比一些傳統指標(如greedy decoding準確率)僅反映平均表現,它通過多輪采樣揭示模型的推理邊界,能更精準判斷模型是否“有能力”解決問題,而非“大概率”解決問題。
具體來說,他們主要把底模、RL模型放在同一批題目上反復測試,來看模型是“真的變聰明”還是只是“更會挑答案”。
為避免實驗結果的局限性,團隊選取了大語言模型推理能力的三大典型應用領域,并搭配權威基準數據集,確保測試的全面性和代表性。
- 數學推理(GSM8K、MATH500等6個基準)
- 代碼生成(LiveCodeBench等3個基準)
- 視覺推理(MathVista等2個基準)
模型則以主流大語言模型家族為基礎,包括Qwen2.5系列(70億、140億、320億參數)和LLaMA-3.1-80億參數模型等,并構建“基礎模型 vs RLVR訓練模型”的對照組合。
其中RLVR訓練模型是指,分別用PPO、GRPO、Reinforce++等6種主流RLVR算法訓練后的版本,形成多組平行對照。這樣既能對比RLVR與基礎模型的差異,也能橫向比較不同RLVR算法的效果。

然后就是對不同模型在各基準任務上的pass@k指標進行多維度采集與分析。
針對每個測試樣本,分別讓基礎模型和RLVR模型進行不同次數的采樣(k值從1逐步提升至1024),記錄每次采樣中“至少出現一個正確結果”的概率。
隨后團隊重點分析兩個關鍵規律:
一是同一k值下,RLVR模型與基礎模型的pass@k差異;二是隨著k值增大,兩類模型pass@k曲線的變化趨勢。
同時,結合模型輸出的推理路徑困惑度分析(perplexity)、可解問題子集比對等輔助手段,最終形成對RLVR能力的全面判斷。
論文作者介紹
值得一提的是,這項研究還是出自咱們國內研究人員之手。
一共8位,7位來自清華大學LeapLab,1位來自上海交通大學。
項目負責人Yang Yue (樂洋),清華大學自動化系四年級博士生。
研究方向為強化學習、世界模型、多模態大模型和具身智能,之前曾在顏水成創辦的新加坡Sea AI Lab和字節跳動 Seed團隊實習過。
雖然還是學生,但發表或參與發表的多篇論文均入選頂會。這當中,他以核心作者身份發表的論文《How Far is Video Generation from World Model: A Physical Law Perspective》,因探索視頻模型能否學會物理規律,還被國內外眾多大佬Yan Lecun,xie saining,Kevin Murphy等轉發。

另一位和他貢獻相同的作者Zhiqi Chen,目前為清華大學自動化工程系大三學生。
研究方向為推理密集型大語言模型的強化學習,在校期間多次獲得國家獎學金。

通訊作者Gao Huang(黃高),清華大學自動化系副教授、博士生導師, LeapLab負責人。
他最知名的工作之一就是發表了論文《Densely Connected Convolutional Networks》,其中提出了經典卷積架構模型DenseNet。
該論文不僅榮獲CVPR2017最佳論文,而且被編入多本深度學習著作,單篇引用量接近6萬次。

其他作者中,來自清華的還有:
- Rui Lu(盧睿),清華大學自動化系四年級博士生,本科畢業于姚班。
- Andrew Zhao(趙啟晨),清華大學自動化系博士生,本碩畢業于加拿大哥倫比亞大學和南加州大學。
- Shiji Song,清華大學自動化系教授,與黃高一起負責指導本項研究。
- Yang Yue (樂陽) ,和項目負責人名字同音,但由于相對低調網上暫無太多公開資料。
以及唯一來自交大的Zhaokai Wang(王肇凱),目前是上海交通大學四年級博士生。
本科畢業于北京航空航天大學,同一時期還拿到了北大經濟學學士學位,當前也在上海人工智能實驗室通用視覺團隊(OpenGVLab)實習。
對于這項研究,團隊作者特意在論文主頁強調:這并不是說強化學習無用了。實際上,它在一些低采樣場景仍舊非常實用。

以及有網友發現,有意思的是,DeepSeek在一年前的一篇論文中也提到了相關現象。
……這些發現表明,強化學習通過使輸出分布更加魯棒來提升模型的整體表現,換言之,性能的提升似乎源于促進了正確答案出現在TopK結果中,而非源于基礎能力的增強。

而這一次,結論被用論文完整論證了。
論文:https://limit-of-rlvr.github.io/