RecSys 2025 | 小紅書推薦團隊提出視頻時長預估新方法:EGMN

小紅書推薦算法團隊提出基于指數-高斯先驗分布的視頻時長預估新方法EGMN,入選 RecSys 2025,并獲得Best Paper Nomination。
論文標題:Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network
論文地址:https://arxiv.org/abs/2508.12665
01、背景
作為中國領先的生活興趣社區,小紅書已經從 2015年的 5000萬 MAU 增長到 2024年的 3.5億 MAU 以上。在這個規模基礎上,推薦系統預測模型的每一個小改進都會在用戶體驗和業務成果方面產生有意義的收益。而在所有反饋信號中,觀看時長是一個至關重要的基礎信號,它是衡量平臺內容質量與用戶滿意度的關鍵指標,尤其在小紅書視頻單列場景中,觀看時長信號是最為稠密的(覆蓋率 100%)。在預估觀看時長方面的精準和精細化,可以有效地提升留存和 DAU。

預估觀看時長是大部分推薦場景都要面臨的基礎問題,也是經典的回歸問題。對于回歸問題而言,目標數據的分布是非常重要的,它很大程度上決定了回歸任務的難度。然而我們都知道,短視頻觀看時長的分布是復雜的,這也使得傳統的值回歸難以取得好的效果。針對這個問題,很多已有的方法往往通過目標轉化的方式(歸一化、離散化等等)來規避掉直接建模復雜分布帶來的挑戰,卻也不可避免地造成信息失真或者引入額外誤差。
我們選擇直面這個挑戰,為此我們對小紅書的短視頻觀看時長數據分布做了全面分析,發現主要有以下幾個特點:
- 從整體維度來看,幾秒內快速跳過的行為大量聚集。
- 從 duration 維度來看,觀看時長在各自 duration 分桶內呈現雙峰分布。
- 從用戶視角來看,不同用戶存在顯著差異。一些用戶非常挑剔,快速跳過去找感興趣的視頻;一些用戶更加寬容,傾向于以更大的耐心觀看每個系統推薦的視頻。
- 從視頻視角來看,情況更為復雜,快速跳過、中間跳出、完播、重播等等行為,構成了形狀各異的多峰分布。

通過對上述特點的總結,我們得出短視頻觀看時長預估面臨以下兩個核心挑戰:
- 粗粒度的偏態性:由大量快速跳過行為引起,使得數據整體而言非常右偏。
- 細粒度的多樣性:由各種用戶視頻交互模式引起,大大增加了預測的復雜性。
02、方法
2.1 先驗概率假設
據此,我們提出 Exponential-Gaussian Mixture(EGM)分布作為觀看時長的生成假設:用指數分布刻畫“快速滑過”帶來的偏斜,用高斯混合刻畫細粒度的多樣性。具體地,給定特征向量 ,我們假設該樣本對應的播放時長分布服從一個指數分布和
個高斯分布組成的混合概率分布,概率密度公式如下:


為避免混合分布中高斯分布和指數分布的“混淆”現象,并使指數項專注于“零附近的偏斜密度”,我們在上述假設的基礎上約束高斯均值大于指數均值:

2.2 概率模型參數化
在上述先驗概率假設下,我們嘗試使用神經網絡來對EGM分布進行參數化,來對混合分布中的各個子分布以及權重進行擬合,整體為“共享編碼器 + 多頭參數生成 + 門控混合”的架構:

2.2.1 隱表示編碼器
- 模型輸入:用戶特征、視頻特征、上下文特征,經嵌入后拼接為向量
。
- 通過特征交叉Backbone得到共享隱式表征:
- Backbone 可選:DCN、DIN、SENet、Transformer、MMoE/PLE 等,EGMN 與之解耦。
2.2.2 混合分布參數生成器
- 指數分布指數率生成,通過 softplus 激活函數確保正值:

- 高斯分布均值生成,通過如下公式保證高斯分布均值大于指數分布均值:

- 高斯分布方差生成:

- 混合權重生成,通過 softmax 進行歸一化:

2.3 訓練目標
采用“分布擬合 + 去塌陷 + 值回歸”的三目標聯合優化:
- 通過極大似然函數來進行分布擬合(MLE):

- 熵正則損失,防止權重塌到單一成分,讓模型盡量激活更多的子分布:

- 回歸損失,對混合分布的期望與真實 label 進行直接進行回歸優化,在分布擬合的同時進行單點擬合:


- 總損失:

經驗上,該組合既保證了分布刻畫能力(MLE)、避免組件塌陷(熵正則)、又兼顧業務所需的數值精度(回歸)。
2.4 推理與策略衍生
- 標準預測:輸出條件期望
。
- 置信與分位數:通過混合分布 CDF 做數值反解獲得分位數;或給出區間概率。
- 快速滑過識別:根據預估的概率密度分布直接計算快速滑過行為概率
。
03、實驗
3.1 實驗設置
3.1.1 數據集
- Indust:951,870 交互,25,947 用戶,7155 視頻。
- KuaiRec:12,530,806 交互,7176 用戶,10,728 視頻
- WeChat:7,310,108 交互,20,000 用戶,96,418 視頻。
- CIKM:搜索會話時長數據,310,302 sessions,122,991 items(驗證可遷移性)。
3.1.2 對比方法
- VR(直接回歸)、TPM(樹分解序回歸)、D2Q(分位數去時長偏)、CREAD(分類-重構,誤差自適應離散)、D2CO(去偏+降噪)。
- 統一 Backbone 與特征處理,公平對比。
3.1.3 評價指標
- MAE:絕對誤差
- XAUC:成對排序一致性
- KL:預測分布與真實分布的 KL 散度(線上校準評估)
3.1.4 訓練與實現
- 嵌入維度 16、學習率 0.1、batch size 2048、Adagrad。
- EGMN 默認
,高斯分量數不經精調即達優。
- 損失權重:
。
- 公共數據集用隨機切分;工業數據離線用時間切分,線上實時流訓練+部署。
3.2 離線實驗

我們將 EGMN 模型與五種基線方法進行離線觀看時長預測效果對比。如上表所示的主要實驗結果表明:在四個數據集上,EGMN 模型的平均絕對誤差(MAE)平均降低 14.11%,XAUC 指標平均提升7.76%,這證明該模型在跨平臺觀看時長預測任務中達到了最先進水平。具體對比表現次優的模型(主要為CREAD),EGMN 在 Indust 數據集上 MAE 降低6.75%、XAUC 提升5.09%;在 KuaiRec 上分別提升5.04%和 4.67%;在微信數據集上提升 1.72%和1.39%;在CIKM數據集上提升 2.42% 和 0.49%。其中 Indust 和微信數據集的提升最為顯著,我們的模型在兩項指標上均保持穩定進步,有力驗證了 EGMN捕捉復雜特征以實現跨數據集精準觀看時長預測的有效性。
值得注意的是,三個公開數據集采用隨機劃分策略,但是按照時序的數據劃分方式對工業場景確保線上線下一致性至關重要,因此我們額外提供了公開數據集在時序劃分下的結果:EGMN 在 KuaiRec 上以XAUC 提升1.77%和 MAE 降低 1.36%超越次優基線;在微信數據集上實現XAUC提升 2.41%和 MAE降低 1.23%;在 CIKM 上以 XAUC 提升 0.5%和MAE 顯著降低 2.37%領先。結合上表數據可知,無論采用何種劃分策略,EGMN 均能持續保持最先進性能。
3.3 在線實驗

為深入驗證 EGMN 的有效性,我們在小紅書工業級短視頻推薦系統中進行了為期 7天的線上 A/B 測試。將10%的真實流量分別分配至EGMN及現有基線模型CREAD(每組實驗覆蓋 1500萬真實用戶,確保結果可靠性)。該排序階段的預測主干網絡采用MMOE模型。上表左側的線上 A/B 測試結果顯示:相比CREAD,EGMN 顯著提升用戶觀看時長0.681%且未對其他指標產生負面影響。此外,EGMN 在視頻播放量指標上也實現 0.189% 的顯著提升,這歸因于其更精準匹配用戶興趣,從而有效提升用戶參與度。
眾所周知,相較無噪聲的離線評估,線上準確性更能可靠衡量推薦系統模型的泛化能力。因此除用戶參與度指標的 A/B 測試外,我們嚴格對比了 EGMN 與CREAD 的實時預測精度。如上表右側所示,EGMN在 MAE 和 XAUC 指標上均顯著優于 CREAD,與離線評估結論一致。進一步通過 KL 散度評估預測時長與實際分布的線上對齊程度:EGMN 較 CREAD 降低 KL 散度近 20%,表明其更逼近真實分布,直接驗證了其在實時觀看時長分布建模中的有效性。
3.4 快滑行為識別能力

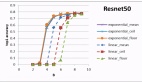
為評估 EGMN 識別快滑的能力(該行為在短視頻推薦系統中是重要的隱性負反饋信號),上圖展示了多個模型在三個快滑閾值(2秒、4秒及6秒)下的區分能力。針對每個閾值,我們構建二分類任務并對比預測觀看時長的 AUC 值。EGMN 在所有閾值下均持續優于 CREAD 和 D2Q 模型,取得最高 AUC 評分。進一步地,我們在上圖中評估了移除指數分布的模型變體(EGMN w/o exp)。實驗發現:在全部三個跳過閾值下,該變體的 AUC 值均出現超過6%的顯著下降,這證明 EGM 分布中的指數分量對捕捉瞬時跳過行為具有關鍵作用。
3.5 跨粒度分布擬合
3.5.1 整體分布擬合

我們對比了 EGMN 與其他基線模型的預測觀看時長分布與實際分布的擬合效果。我們計算了模型預測與真實分布間的 KL 散度:KL 散度越低表明分布擬合能力越強。如上圖瑣事,除 EGMN 與 D2Q 外,所有方法的分布擬合能力均較差(KL散度>1.0),其中 VR模型甚至未能學習到有效規律。EGMN 收斂至 0.5 的KL 散度,而 D2Q 達到 0.1。上圖下方展示了 EGMN 與 D2Q 的 MAE 趨勢對比分析。關鍵發現在于:D2Q 的 MAE 在第6輪訓練后呈現先降后升的急劇波動,而 EGMN 則保持近似單調下降趨勢。這種對比表明:盡管 D2Q 通過剛性約束(直接擬合預計算分位數)實現了最小 KL 散度,卻嚴重損害了數值回歸精度;反觀 EGMN,其 KL 散度與 MAE 在整個訓練周期中呈現同步優化的聯合收斂態勢。總體而言,EGMN 能更優地平衡分布建模與數值回歸間的權衡關系。
3.5.2 視頻長度粒度

本節中,我們對比了 EGMN 與基線模型 CREAD 在視頻長度粒度的分布建模能力。如上圖所示,我們展示了四個不同視頻長度區間內實際觀看時長分布與EGMN、CREAD 預測分布的對比結果。如前所述:雖然整體觀看時長分布在零值附近呈現顯著偏態,但相同長度視頻的觀看分布始終表現出雙峰特性(一個峰值在3秒附近,另一峰值接近視頻長度)。EGMN的預測分布與真實分布高度吻合,精準保留了雙峰特征。值得注意的是,EGMN 沒有顯式的視頻長度糾偏操作,僅將視頻長度作為模型特征即可捕捉時長相關的分布規律,這證明其混合架構天然具備跨特征粒度的分布建模能力。相較之下,CREAD 在所有時長區間均近似高斯分布(僅存在微小均值偏移),表明其無法捕捉時長層面的分布規律。
3.5.3 User-Video 粒度

為進一步評估 EGMN 的分布建模能力,我們在User-Video 粒度進行了精細化評估。如背景中所述,我們選取兩類典型用戶:User1 呈現挑剔型的觀看模式,User2 展現寬容型的觀看模式;同時選擇兩類視頻:Video1(美妝類視頻)呈現雙峰觀看分布,Video2(電影混剪)具有扁平化多峰分布特征。上圖中,User/Video邊緣概率分布面板(左列與頂部行)以直方圖展示真實概率密度分布,疊加曲線為 EGMN 預測概率密度。可以看到 EGMN 對用戶與視頻的邊緣分布均實現精準擬合,證實其能準確建模個體用戶消費習慣與特定視頻的播放時長分布。
黃色背景的 2×2 矩陣展示了 EGMN 對特定 User-Video的觀看時長分布預測。這些分布揭示了模型融合用戶行為模式與視頻特征的能力。例如在 ??(??|????????2,??????????2)分布中:指數分量權重趨近于零(反映 User2 的低快滑傾向),而分布中的四個峰值精準對應 Video2 邊緣分布的四峰特征。這證明 EGMN 不僅能分別建模用戶與視頻分布,更能有效融合生成精確的聯合預測分布——成功捕獲用戶偏好與視頻特性間的交互效應,使預測結果同時反映用戶觀看習慣與視頻特定的播放模式。
上述實驗驗證了 EGMN 卓越的由粗到細粒度分布建模能力,這對于需要完整理解用戶觀看時長分布以實現精準推薦的系統具有重要價值。
04、結語
我們從分布角度揭示了觀看時長預測面臨的兩大核心難題:
- 由大量快速跳過行為引發的粗粒度偏態分布
- 多樣化用戶-視頻交互模式導致的細粒度多樣性分布。為此,我們提出觀看時長遵循指數-高斯混合分布的假設,其中指數分布刻畫偏態特征,高斯分布刻畫多樣性特征。
我們進一步提出指數-高斯混合網絡來實現上述分布的參數化建模,該框架包含兩大核心模塊:隱式表征編碼器和混合參數生成器。我們在工業級短視頻平臺上進行了大量離線實驗和在線A/B測試,驗證了該方法相對于現有最優方法的優越性。
該模型通過預估觀看時長的概率密度函數,不僅可以直接求解期望作為觀看時長的預估值,還可以靈活的提供額外信息:
- 快速跳過行為的識別
- 特定觀看時長區間的累積概率計算
- 面向用戶/視頻的分位數估計
- 不確定性量化的統計置信度
這種靈活性使得工業推薦系統能基于同一底層模型支持多樣化策略設計,無需開發專用模型變體。
05、作者簡介
碩風
碩士畢業于清華大學計算機系,負責小紅書視頻推薦場景的模型以及策略優化。在 SIGIR RECSYS ACL EMNLP 等機器學習、推薦系統、自然語言處理頂會發表多篇一作論文。主要研究方向:推薦系統多目標優化、時長預估、多目標融合等。
觴闕
小紅書視頻推薦團隊算法工程師,畢業于北京郵電大學,小紅書視頻內流LTR、Rerank等技術模塊的負責人,主要研究時長建模、LTV建模等方向。
姬昊
小紅書單列視頻推薦團隊負責人,畢業于中科院自動化所, 曾在WWW、Recsys、PR等機器學習、推薦系統、數據挖掘會刊發表論文數篇,曾獲Recsys25 Best Paper Nomination。主要研究方向:多任務建模、跨域學習、時長建模、Learning2Rank、序列生成等。
陳佳琦(實習生)
小紅書視頻推薦實習生,現碩士就讀于北京理工大學,主攻推薦系統中時長建模與排序方向。