基于流的數(shù)據(jù)處理可以使Hadoop運行更快嗎?
作者:佚名
Apache Hadoop分布式文件處理系統(tǒng)是有好處的,而且它正在獲得注意力。然而,它也有壞處。有些組織發(fā)現(xiàn)從Hadoop開始的話需要重新思考軟件架構(gòu),而且它所需要的數(shù)據(jù)技能也是必要的。
Apache Hadoop分布式文件處理系統(tǒng)是有好處的,而且它正在獲得注意力。然而,它也有壞處。有些組織發(fā)現(xiàn)從Hadoop開始的話需要重新思考軟件架構(gòu),而且它所需要的數(shù)據(jù)技能也是必要的。
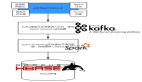
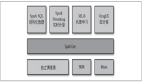
對于一些人來說,Hadoop的批處理模型的一個問題是,它估計在突增數(shù)據(jù)采集之間的進行批處理時會有宕機的時間。這是許多企業(yè)都的情況,當他們在本地操作,或者在白天有大量事務(wù),但很少在晚上(如果有的話)。如果夜間窗口足夠大可以處理前一天積累的數(shù)據(jù),那么一切都會順利。雖然對于一些企業(yè),窗口的停機時間是小或不存在的,甚至使用Hadoop的高性能的處理,他們?nèi)匀辉谝惶靸?nèi)得到的數(shù)據(jù)比他們可以在24內(nèi)小時處理的要多。
對于可接受小窗口的組織,添加基于數(shù)據(jù)處理組件的方法可能有幫助,GigaSpaces的***技術(shù)官Nati Shalom在最近的一篇關(guān)于使用Hadoop更快的博客中寫到。通過不斷地處理傳入的數(shù)據(jù)轉(zhuǎn)化成有用的包和刪除那些不需要企業(yè)處理(或再加工)的靜態(tài)數(shù)據(jù),可以顯著加速他們的大數(shù)據(jù)的批處理過程。
責(zé)任編輯:王程程
來源:
中云網(wǎng)