如何用PyTorch實現遞歸神經網絡?
從 Siri 到谷歌翻譯,深度神經網絡已經在機器理解自然語言方面取得了巨大突破。這些模型大多數將語言視為單調的單詞或字符序列,并使用一種稱為循環神經網絡(recurrent neural network/RNN)的模型來處理該序列。但是許多語言學家認為語言最好被理解為具有樹形結構的層次化詞組,一種被稱為遞歸神經網絡(recursive neural network)的深度學習模型考慮到了這種結構,這方面已經有大量的研究。雖然這些模型非常難以實現且效率很低,但是一個全新的深度學習框架 PyTorch 能使它們和其它復雜的自然語言處理模型變得更加容易。
雖然遞歸神經網絡很好地顯示了 PyTorch 的靈活性,但它也廣泛支持其它的各種深度學習框架,特別的是,它能夠對計算機視覺(computer vision)計算提供強大的支撐。PyTorch 是 Facebook AI Research 和其它幾個實驗室的開發人員的成果,該框架結合了 Torch7 高效靈活的 GPU 加速后端庫與直觀的 Python 前端,它的特點是快速成形、代碼可讀和支持最廣泛的深度學習模型。
開始 SPINN
鏈接中的文章(https://github.com/jekbradbury/examples/tree/spinn/snli)詳細介紹了一個遞歸神經網絡的 PyTorch 實現,它具有一個循環跟蹤器(recurrent tracker)和 TreeLSTM 節點,也稱為 SPINN——SPINN 是深度學習模型用于自然語言處理的一個例子,它很難通過許多流行的框架構建。這里的模型實現部分運用了批處理(batch),所以它可以利用 GPU 加速,使得運行速度明顯快于不使用批處理的版本。
SPINN 的意思是堆棧增強的解析器-解釋器神經網絡(Stack-augmented Parser-Interpreter Neural Network),由 Bowman 等人于 2016 年作為解決自然語言推理任務的一種方法引入,該論文中使用了斯坦福大學的 SNLI 數據集。
該任務是將語句對分為三類:假設語句 1 是一幅看不見的圖像的準確標題,那么語句 2(a)肯定(b)可能還是(c)絕對不是一個準確的標題?(這些類分別被稱為蘊含(entailment)、中立(neutral)和矛盾(contradiction))。例如,假設一句話是「兩只狗正跑過一片場地」,蘊含可能會使這個語句對變成「戶外的動物」,中立可能會使這個語句對變成「一些小狗正在跑并試圖抓住一根棍子」,矛盾能會使這個語句對變成「寵物正坐在沙發上」。
特別地,研究 SPINN 的初始目標是在確定語句的關系之前將每個句子編碼(encoding)成固定長度的向量表示(也有其它方式,例如注意模型(attention model)中將每個句子的每個部分用一種柔焦(soft focus)的方法相互比較)。
數據集是用句法解析樹(syntactic parse tree)方法由機器生成的,句法解析樹將每個句子中的單詞分組成具有獨立意義的短語和子句,每個短語由兩個詞或子短語組成。許多語言學家認為,人類通過如上面所說的樹的分層方式來組合詞意并理解語言,所以用相同的方式嘗試構建一個神經網絡是值得的。下面的例子是數據集中的一個句子,其解析樹由嵌套括號表示:
- ( ( The church ) ( ( has ( cracks ( in ( the ceiling ) ) ) ) . ) )
這個句子進行編碼的一種方式是使用含有解析樹的神經網絡構建一個神經網絡層 Reduce,這個神經網絡層能夠組合詞語對(用詞嵌入(word embedding)表示,如 GloVe)、 和/或短語,然后遞歸地應用此層(函數),將最后一個 Reduce 產生的結果作為句子的編碼:
- X = Reduce(“the”, “ceiling”)
- Y = Reduce(“in”, X)
- ... etc.
但是,如果我希望網絡以更類似人類的方式工作,從左到右閱讀并保留句子的語境,同時仍然使用解析樹組合短語?或者,如果我想訓練一個網絡來構建自己的解析樹,讓解析樹根據它看到的單詞讀取句子?這是一個同樣的但方式略有不同的解析樹的寫法:
- The church ) has cracks in the ceiling ) ) ) ) . ) )
或者用第 3 種方式表示,如下:
- WORDS: The church has cracks in the ceiling .
- PARSES: S S R S S S S S R R R R S R R
我所做的只是刪除開括號,然后用「S」標記「shift」,并用「R」替換閉括號用于「reduce」。但是現在可以從左到右讀取信息作為一組指令來操作一個堆棧(stack)和一個類似堆棧的緩沖區(buffer),能得到與上述遞歸方法完全相同的結果:
- 將單詞放入緩沖區。
- 從緩沖區的前部彈出「The」,將其推送(push)到堆棧上層,緊接著是「church」。
- 彈出前 2 個堆棧值,應用于 Reduce,然后將結果推送回堆棧。
- 從緩沖區彈出「has」,然后推送到堆棧,然后是「cracks」,然后是「in」,然后是「the」,然后是「ceiling」。
- 重復四次:彈出 2 個堆棧值,應用于 Reduce,然后推送結果。
- 從緩沖區彈出「.」,然后推送到堆棧上層。
- 重復兩次:彈出 2 個堆棧值,應用于 Reduce,然后推送結果。
- 彈出剩余的堆棧值,并將其作為句子編碼返回。
我還想保留句子的語境,以便在對句子的后半部分應用 Reduce 層時考慮系統已經讀取的句子部分的信息。所以我將用一個三參數函數替換雙參數的 Reduce 函數,該函數的輸入值為一個左子句、一個右子句和當前句的上下文狀態。該狀態由神經網絡的第二層(稱為循環跟蹤器(Tracker)的單元)創建。Tracker 在給定當前句子上下文狀態、緩沖區中的頂部條目 b 和堆棧中前兩個條目 s1\s2 時,在堆棧操作的每個步驟(即,讀取每個單詞或閉括號)后生成一個新狀態:
- context[t+1] = Tracker(context[t], b, s1, s2)
容易設想用你最喜歡的編程語言來編寫代碼做這些事情。對于要處理的每個句子,它將從緩沖區加載下一個單詞,運行跟蹤器,檢查是否將單詞推送入堆棧或執行 Reduce 函數,執行該操作;然后重復,直到對整個句子完成處理。通過對單個句子的應用,該過程構成了一個大而復雜的深度神經網絡,通過堆棧操作的方式一遍又一遍地應用它的兩個可訓練層。但是,如果你熟悉 TensorFlow 或 Theano 等傳統的深度學習框架,就知道它們很難實現這樣的動態過程。你值得花點時間回顧一下,探索為什么 PyTorch 能有所不同。
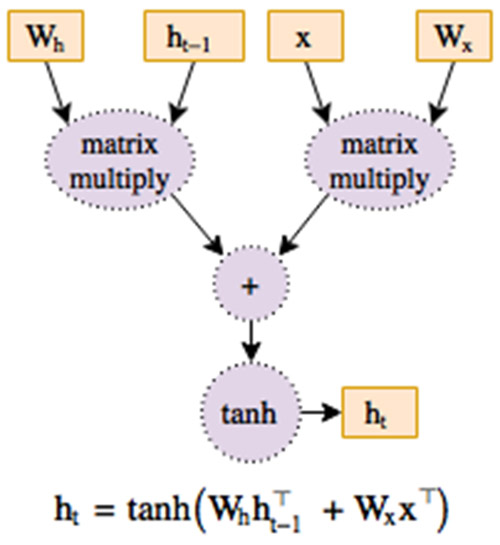
圖 1:一個函數的圖結構表示
深度神經網絡本質上是有大量參數的復雜函數。深度學習的目的是通過計算以損失函數(loss)度量的偏導數(梯度)來優化這些參數。如果函數表示為計算圖結構(圖 1),則向后遍歷該圖可實現這些梯度的計算,而無需冗余工作。每個現代深度學習框架都是基于此反向傳播(backpropagation)的概念,因此每個框架都需要一個表示計算圖的方式。
在許多流行的框架中,包括 TensorFlow、Theano 和 Keras 以及 Torch7 的 nngraph 庫,計算圖是一個提前構建的靜態對象。該圖是用像數學表達式的代碼定義的,但其變量實際上是尚未保存任何數值的占位符(placeholder)。圖中的占位符變量被編譯進函數,然后可以在訓練集的批處理上重復運行該函數來產生輸出和梯度值。
這種靜態計算圖(static computation graph)方法對于固定結構的卷積神經網絡效果很好。但是在許多其它應用中,有用的做法是令神經網絡的圖結構根據數據而有所不同。在自然語言處理中,研究人員通常希望通過每個時間步驟中輸入的單詞來展開(確定)循環神經網絡。上述 SPINN 模型中的堆棧操作很大程度上依賴于控制流程(如 for 和 if 語句)來定義特定句子的計算圖結構。在更復雜的情況下,你可能需要構建結構依賴于模型自身的子網絡輸出的模型。
這些想法中的一些(雖然不是全部)可以被生搬硬套到靜態圖系統中,但幾乎總是以降低透明度和增加代碼的困惑度為代價。該框架必須在其計算圖中添加特殊的節點,這些節點代表如循環和條件的編程原語(programming primitive),而用戶必須學習和使用這些節點,而不僅僅是編程代碼語言中的 for 和 if 語句。這是因為程序員使用的任何控制流程語句將僅運行一次,當構建圖時程序員需要硬編碼(hard coding)單個計算路徑。
例如,通過詞向量(從初始狀態 h0 開始)運行循環神經網絡單元(rnn_unit)需要 TensorFlow 中的特殊控制流節點 tf.while_loop。需要一個額外的特殊節點來獲取運行時的詞長度,因為在運行代碼時它只是一個占位符。
- # TensorFlow
- # (this code runs once, during model initialization)
- # “words” is not a real list (it’s a placeholder variable) so
- # I can’t use “len”
- cond = lambda i, h: i < tf.shape(words)[0]
- cell = lambda i, h: rnn_unit(words[i], h)
- i = 0
- _, h = tf.while_loop(cond, cell, (i, h0))
基于動態計算圖(dynamic computation graph)的方法與之前的方法有根本性不同,它有幾十年的學術研究歷史,其中包括了哈佛的 Kayak、自動微分庫(autograd)以及以研究為中心的框架 Chainer和 DyNet。在這樣的框架(也稱為運行時定義(define-by-run))中,計算圖在運行時被建立和重建,使用相同的代碼為前向通過(forward pass)執行計算,同時也為反向傳播(backpropagation)建立所需的數據結構。這種方法能產生更直接的代碼,因為控制流程的編寫可以使用標準的 for 和 if。它還使調試更容易,因為運行時斷點(run-time breakpoint)或堆棧跟蹤(stack trace)將追蹤到實際編寫的代碼,而不是執行引擎中的編譯函數。可以在動態框架中使用簡單的 Python 的 for 循環來實現有相同變量長度的循環神經網絡。
- # PyTorch (also works in Chainer)
- # (this code runs on every forward pass of the model)
- # “words” is a Python list with actual values in it
- h = h0
- for word in words: h = rnn_unit(word, h)
PyTorch 是第一個 define-by-run 的深度學習框架,它與靜態圖框架(如 TensorFlow)的功能和性能相匹配,使其能很好地適合從標準卷積神經網絡(convolutional network)到最瘋狂的強化學習(reinforcement learning)等思想。所以讓我們來看看 SPINN 的實現。
代碼
在開始構建網絡之前,我需要設置一個數據加載器(data loader)。通過深度學習,模型可以通過數據樣本的批處理進行操作,通過并行化(parallelism)加快訓練,并在每一步都有一個更平滑的梯度變化。我想在這里可以做到這一點(稍后我將解釋上述堆棧操作過程如何進行批處理)。以下 Python 代碼使用內置于 PyTorch 的文本庫的系統來加載數據,它可以通過連接相似長度的數據樣本自動生成批處理。運行此代碼之后,train_iter、dev_iter 和 test_itercontain 循環遍歷訓練集、驗證集和測試集分塊 SNLI 的批處理。
- from torchtext import data, datasets TEXT = datasets.snli.ParsedTextField(lower=True)
- TRANSITIONS = datasets.snli.ShiftReduceField()
- LABELS = data.Field(sequential=False)train, dev, test = datasets.SNLI.splits( TEXT, TRANSITIONS, LABELS, wv_type='glove.42B')TEXT.build_vocab(train, dev, test)
- train_iter, dev_iter, test_iter = data.BucketIterator.splits( (train, dev, test), batch_size=64)
你可以在 train.py中找到設置訓練循環和準確性(accuracy)測量的其余代碼。讓我們繼續。如上所述,SPINN 編碼器包含參數化的 Reduce 層和可選的循環跟蹤器來跟蹤句子上下文,以便在每次網絡讀取單詞或應用 Reduce 時更新隱藏狀態;以下代碼代表的是,創建一個 SPINN 只是意味著創建這兩個子模塊(我們將很快看到它們的代碼),并將它們放在一個容器中以供稍后使用。
- import torchfrom torch import nn
- # subclass the Module class from PyTorch’s neural network package
- class SPINN(nn.Module):
- def __init__(self, config):
- super(SPINN, self).__init__()
- self.config = config
- self.reduce = Reduce(config.d_hidden, config.d_tracker)
- if config.d_tracker is not None:
- self.tracker = Tracker(config.d_hidden, config.d_tracker)
當創建模型時,SPINN.__init__ 被調用了一次;它分配和初始化參數,但不執行任何神經網絡操作或構建任何類型的計算圖。在每個新的批處理數據上運行的代碼由 SPINN.forward 方法定義,它是用戶實現的方法中用于定義模型向前過程的標準 PyTorch 名稱。上面描述的是堆棧操作算法的一個有效實現,即在一般 Python 中,在一批緩沖區和堆棧上運行,每一個例子都對應一個緩沖區和堆棧。我使用轉移矩陣(transition)包含的「shift」和「reduce」操作集合進行迭代,運行 Tracker(如果存在),并遍歷批處理中的每個樣本來應用「shift」操作(如果請求),或將其添加到需要「reduce」操作的樣本列表中。然后在該列表中的所有樣本上運行 Reduce 層,并將結果推送回到它們各自的堆棧。
- def forward(self, buffers, transitions):
- # The input comes in as a single tensor of word embeddings;
- # I need it to be a list of stacks, one for each example in
- # the batch, that we can pop from independently. The words in
- # each example have already been reversed, so that they can
- # be read from left to right by popping from the end of each
- # list; they have also been prefixed with a null value.
- buffers = [list(torch.split(b.squeeze(1), 1, 0))
- for b in torch.split(buffers, 1, 1)]
- # we also need two null values at the bottom of each stack,
- # so we can copy from the nulls in the input; these nulls
- # are all needed so that the tracker can run even if the
- # buffer or stack is empty
- stacks = [[buf[0], buf[0]] for buf in buffers]
- if hasattr(self, 'tracker'):
- self.tracker.reset_state()
- for trans_batch in transitions:
- if hasattr(self, 'tracker'):
- # I described the Tracker earlier as taking 4
- # arguments (context_t, b, s1, s2), but here I
- # provide the stack contents as a single argument
- # while storing the context inside the Tracker
- # object itself.
- tracker_states, _ = self.tracker(buffers, stacks)
- else:
- tracker_states = itertools.repeat(None)
- lefts, rights, trackings = [], [], []
- batch = zip(trans_batch, buffers, stacks, tracker_states)
- for transition, buf, stack, tracking in batch:
- if transition == SHIFT:
- stack.append(buf.pop())
- elif transition == REDUCE:
- rights.append(stack.pop())
- lefts.append(stack.pop())
- trackings.append(tracking)
- if rights:
- reduced = iter(self.reduce(lefts, rights, trackings))
- for transition, stack in zip(trans_batch, stacks):
- if transition == REDUCE:
- stack.append(next(reduced))
- return [stack.pop() for stack in stacks]
在調用 self.tracker 或 self.reduce 時分別運行 Tracker 或 Reduce 子模塊的向前方法,該方法需要在樣本列表上應用前向操作。在主函數的向前方法中,在不同的樣本上進行獨立的操作是有意義的,即為批處理中每個樣本提供分離的緩沖區和堆棧,因為所有受益于批處理執行的重度使用數學和需要 GPU 加速的操作都在 Tracker 和 Reduce 中進行。為了更干凈地編寫這些函數,我將使用一些 helper(稍后將定義)將這些樣本列表轉化成批處理張量(tensor),反之亦然。
我希望 Reduce 模塊自動批處理其參數以加速計算,然后解批處理(unbatch)它們,以便可以單獨推送和彈出。用于將每對左、右子短語表達組合成父短語(parent phrase)的實際組合函數是 TreeLSTM,它是普通循環神經網絡單元 LSTM 的變型。該組合函數要求每個子短語的狀態實際上由兩個張量組成,一個隱藏狀態 h 和一個存儲單元(memory cell)狀態 c,而函數是使用在子短語的隱藏狀態操作的兩個線性層(nn.Linear)和將線性層的結果與子短語的存儲單元狀態相結合的非線性組合函數 tree_lstm。在 SPINN 中,這種方式通過添加在 Tracker 的隱藏狀態下運行的第 3 個線性層進行擴展。
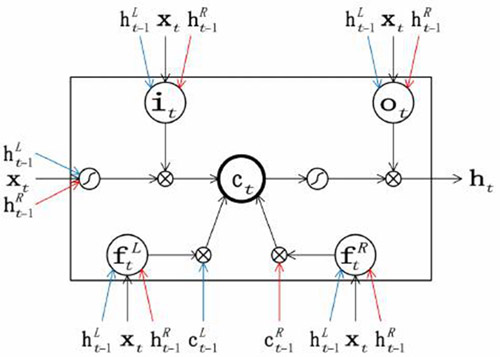
圖 2:TreeLSTM 組合函數增加了第 3 個輸入(x,在這種情況下為 Tracker 狀態)。在下面所示的 PyTorch 實現中,5 組的三種線性變換(由藍色、黑色和紅色箭頭的三元組表示)組合為三個 nn.Linear 模塊,而 tree_lstm 函數執行位于框內的所有計算。圖來自 Chen et al. (2016)。
- def tree_lstm(c1, c2, lstm_in):
- # Takes the memory cell states (c1, c2) of the two children, as
- # well as the sum of linear transformations of the children’s
- # hidden states (lstm_in)
- # That sum of transformed hidden states is broken up into a
- # candidate output a and four gates (i, f1, f2, and o).
- a, i, f1, f2, o = lstm_in.chunk(5, 1)
- c = a.tanh() * i.sigmoid() + f1.sigmoid() * c1 + f2.sigmoid() * c2
- h = o.sigmoid() * c.tanh()
- return h, cclass Reduce(nn.Module):
- def __init__(self, size, tracker_size=None):
- super(Reduce, self).__init__()
- self.left = nn.Linear(size, 5 * size)
- self.right = nn.Linear(size, 5 * size, bias=False)
- if tracker_size is not None:
- self.track = nn.Linear(tracker_size, 5 * size, bias=False)
- def forward(self, left_in, right_in, tracking=None):
- left, right = batch(left_in), batch(right_in)
- tracking = batch(tracking)
- lstm_in = self.left(left[0])
- lstm_in += self.right(right[0])
- if hasattr(self, 'track'):
- lstm_in += self.track(tracking[0])
- return unbatch(tree_lstm(left[1], right[1], lstm_in))
由于 Reduce 層和類似實現方法的 Tracker 都用 LSTM 進行工作,所以批處理和解批處理幫助函數在隱藏狀態和存儲狀態對(h,c)上運行。
- def batch(states):
- if states is None:
- return None
- states = tuple(states)
- if states[0] is None:
- return None
- # states is a list of B tensors of dimension (1, 2H)
- # this returns two tensors of dimension (B, H)
- return torch.cat(states, 0).chunk(2, 1)def unbatch(state):
- if state is None:
- return itertools.repeat(None)
- # state is a pair of tensors of dimension (B, H)
- # this returns a list of B tensors of dimension (1, 2H)
- return torch.split(torch.cat(state, 1), 1, 0)
這就是所有。其余的必要代碼(包括 Tracker),在 spinn.py中,同時分類器層可以從兩個句子編碼中計算 SNLI 類別,并在給出最終損失(loss)變量的情況下將此結果與目標進行比較,代碼在 model.py中。SPINN 及其子模塊的向前代碼產生了非常復雜的計算圖(圖 3),最終計算出損失函數,其細節在數據集中的每個批處理中都完全不同,但是每次只需很少的開銷(overhead)即可自動反向傳播,通過調用 loss.backward(),一個內置于 PyTorch 中的函數,它可以從圖中的任何一點執行反向傳播。
完整代碼中的模型和超參數可以與原始 SPINN 論文中報告的性能相匹配,但是充分利用了批處理加工和 PyTorch 的效率后,在 GPU 上訓練的速度要快幾倍。雖然原始實現需要21 分鐘來編譯計算圖(意味著實施過程中的調試周期至少要那么長),然后訓練大約 5 天時間,這里描述的版本沒有編譯步驟,它的訓練在 Tesla K40 的 GPU 上需要約 13 個小時,或者在 Quadro GP100 上約 9 小時。
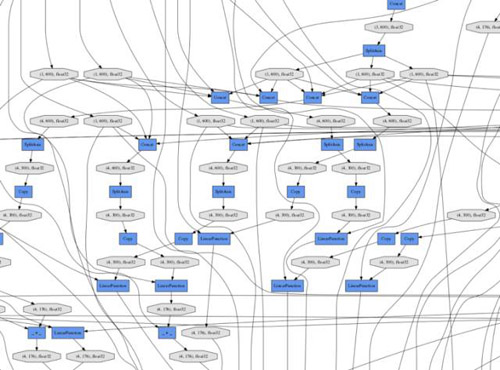
圖 3:具有批大小為 2 的 SPINN 計算圖的一小部分,它運行的是本文中提供的 Chainer 代碼版本。
調用所有的強化學習
上述沒有跟蹤器(Tracker)的模型版本實際上非常適合 TensorFlow 的新 tf.fold 域特定語言,它針對動態圖形的特殊情況,但是有跟蹤器的版本將難以實現。這是因為添加跟蹤器意味著從遞歸(recursive)方法切換到基于堆棧的方法。這(如上面的代碼)是最直接地使用依賴于輸入值的條件分支(conditional branch)來實現的。但是 Fold 缺少內置的條件分支操作,所以使用它構建的模型中的圖形結構只能取決于輸入的結構而不是其數值。此外,構建一個其跟蹤器在讀取輸入句子時就決定如何解析輸入句子的 SPINN 的版本是完全沒有可能的,因為一旦加載了一個輸入樣本 Fold 中的圖結構必須完全固定(圖結構依賴于輸入樣本的結構)。
DeepMind 和谷歌大腦的研究人員研究了一個這樣的模型,他們應用強化學習來訓練一個 SPINN 的跟蹤器解析輸入句子,而不使用任何外部解析數據。本質上,這樣一個模型從隨機猜測開始,當它的解析在整體分類任務上恰好產生良好的準確性時,它產生一個自我獎勵(reward)并通過獎勵來學習。研究人員寫道,他們「使用的批處理大小為 1,因為在每次迭代中計算圖需要根據每個來自策略網絡(policy network)的樣本重新構建 [Tracker]」——但 PyTorch 使得在像這樣一個復雜的、結構隨機變化的網絡上進行批處理訓練成為可能。
PyTorch 也是第一個以隨機計算圖(stochastic computation graph)形式建立強化學習(RL)庫的框架,使得策略梯度(policy gradient)強化學習如反向傳播一樣易于使用。要將其添加到上述模型中,你只需重新編寫主 SPINN 的 for 循環的前幾行,如下所示,使得 Tracker 能夠定義進行每種解析轉移矩陣的概率。
- !# nn.functional contains neural network operations without parametersfrom torch.nn import functional as F
- transitions = []for i in range(len(buffers[0]) * 2 - 3):
- # we know how many steps
- # obtain raw scores for each kind of parser transition
- tracker_states, transition_scores = self.tracker(buffers, stacks)
- # use a softmax function to normalize scores into probabilities,
- # then sample from the distribution these probabilities define
- transition_batch = F.softmax(transition_scores).multinomial()
- transitions.append(transition_batch
然后,隨著批處理一直運行,模型會得出它預測的類別的準確程度,我可以通過這些隨機計算圖的節點發出獎勵信號,另外在圖的其余部分以傳統方式進行反向傳播:
- # losses should contain a loss per example, while mean and std
- # represent averages across many batches
- rewards = (-losses - mean) / std
- for transition in transitions:
- transition.reinforce(rewards)
- # connect the stochastic nodes to the final loss variable
- # so that backpropagation can find them, multiplying by zero
- # because this trick shouldn’t change the loss value
- loss = losses.mean() + 0 * sum(transitions).sum()
- # perform backpropagation through deterministic nodes and
- # policy gradient RL for stochastic nodesloss.backward()
谷歌研究人員報告了包含強化學習的 SPINN 的結果,比原始的在 SNLI 數據集的 SPINN 上獲得的結果要好一些——盡管強化學習版本不使用預先計算的解析樹信息。自然語言處理的深度強化學習領域是全新的,該領域的研究課題非常廣泛;通過將強化學習構建到框架中,PyTorch 大大降低了進入門檻。
從今天起開始使用 PyTorch
遵循 pytorch.org 網站上的說明安裝,選擇安裝平臺(即將推出 Windows 版本的支持)。PyTorch 支持 Python 2 和 3 以及使用 CUDA 7.5 或 8.0 和 CUDNN 5.1 或 6.0 的 CPU 或 NVIDIA GPU 上的計算。它有針對 conda 和 pip 的 Linux 二進制文件甚至含有 CUDA 本身,因此你不需要自己設置它。
官方教程包含 60 分鐘的介紹和深度 Q-學習(Deep Q-Learning,一種現代強化學習模型)的演練。斯坦福的 Justin Johnson 教授有一個非常全面的教程,官方示例還包括——深度卷積生成對抗網絡(DCGAN)、ImageNet 模型和神經機器翻譯模型(neural machine translation)。新加坡國立大學的 Richie Ng 制作了最新的其它 PyTorch 實現、示例和教程的列表。PyTorch 開發人員和用戶社區在討論論壇上的第一時間回答問題,但你應該首先檢查 API 文檔。
盡管 PyTorch 僅使用了較短時間,但三篇研究論文已經使用了它,幾個學術實驗室和業界實驗室也采用了 PyTorch。回溯過去,在當時動態計算圖比現在模糊時,我與同事在 Salesforce Research(https://metamind.io/research.html)也曾經考慮過 Chainer 作為我們的秘密配方;現在,在大公司的支持下,我們很高興 PyTorch 將這一水平的能力和靈活性帶入了主流。