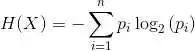機器學習算法實踐:決策樹 (Decision Tree)
前言
最近打算系統學習下機器學習的基礎算法,避免眼高手低,決定把常用的機器學習基礎算法都實現一遍以便加深印象。本文為這系列博客的第一篇,關于決策樹(Decision Tree)的算法實現,文中我將對決策樹種涉及到的算法進行總結并附上自己相關的實現代碼。所有算法代碼以及用于相應模型的訓練的數據都會放到GitHub上(https://github.com/PytLab/MLBox).
本文中我將一步步通過MLiA的隱形眼鏡處方數集構建決策樹并使用Graphviz將決策樹可視化。
正文
決策樹學習
決策樹學習是根據數據的屬性采用樹狀結構建立的一種決策模型,可以用此模型解決分類和回歸問題。常見的算法包括 CART(Classification And Regression Tree), ID3, C4.5等。我們往往根據數據集來構建一棵決策樹,他的一個重要任務就是為了數據中所蘊含的知識信息,并提取出一系列的規則,這些規則也就是樹結構的創建過程就是機器學習的過程。
決策樹的結構
以下面一個簡單的用于是否買電腦預測的決策樹為例子,樹中的內部節點表示某個屬性,節點引出的分支表示此屬性的所有可能的值,葉子節點表示最終的判斷結果也就是類型。
借助可視化工具例如Graphviz,matplotlib的注解等等都可以講我們創建的決策樹模型可視化并直接被人理解,這是貝葉斯神經網絡等算法沒有的特性。
決策樹算法
決策樹算法主要是指決策樹進行創建中進行樹分裂(劃分數據集)的時候選取最優特征的算法,他的主要目的就是要選取一個特征能夠將分開的數據集盡量的規整,也就是盡可能的純. 最大的原則就是: 將無序的數據變得更加有序
這里總結下三個常用的方法:
- 信息增益(information gain)
- 增益比率(gain ratio)
- 基尼不純度(Gini impurity)
信息增益 (Information gain)
這里涉及到了信息論中的一些概念:某個事件的信息量,信息熵,信息增益等, 關于事件信息的通俗解釋可以看知乎上的一個回答
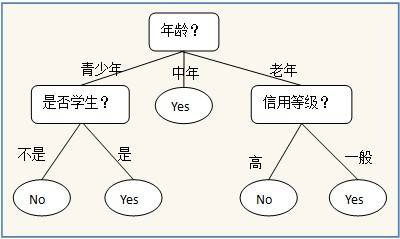
- 某個事件 i 的信息量: 這個事件發生的概率的負對數
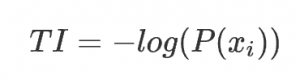
- 信息熵就是平均而言一個事件發生得到的信息量大小,也就是信息量的期望值

任何一個序列都可以獲取這個序列的信息熵,也就是將此序列分類后統計每個類型的概率,再用上述公式計算,使用Python實現如下:
- def get_shanno_entropy(self, values):
- ''' 根據給定列表中的值計算其Shanno Entropy
- '''
- uniq_vals = set(values)
- val_nums = {key: values.count(key) for key in uniq_vals}
- probs = [v/len(values) for k, v in val_nums.items()]
- entropy = sum([-prob*log2(prob) for prob in probs])
- return entropy
信息增益
我們將一組數據集進行劃分后,數據的信息熵會發生改變,我們可以通過使用信息熵的計算公式分別計算被劃分的子數據集的信息熵并計算他們的平均值(期望值)來作為分割后的數據集的信息熵。新的信息熵的相比未劃分數據的信息熵的減小值便是信息增益了. 這里我在最初就理解錯了,于是寫出的代碼并不能創建正確的決策樹。
假設我們將數據集D劃分成kk 份D1,D2,…,Dk,則劃分后的信息熵為:
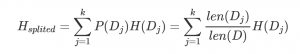
信息增益便是兩個信息熵的差值
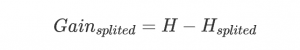
在這里我主要使用信息增益來進行屬性選擇,具體的實現代碼如下:
- def choose_best_split_feature(self, dataset, classes):
- ''' 根據信息增益確定最好的劃分數據的特征
- :param dataset: 待劃分的數據集
- :param classes: 數據集對應的類型
- :return: 劃分數據的增益最大的屬性索引
- '''
- base_entropy = self.get_shanno_entropy(classes)
- feat_num = len(dataset[0])
- entropy_gains = []
- for i in range(feat_num):
- splited_dict = self.split_dataset(dataset, classes, i)
- new_entropy = sum([
- len(sub_classes)/len(classes)*self.get_shanno_entropy(sub_classes)
- for _, (_, sub_classes) in splited_dict.items()
- ])
- entropy_gains.append(base_entropy - new_entropy)
- return entropy_gains.index(max(entropy_gains))
增益比率
增益比率是信息增益方法的一種擴展,是為了克服信息增益帶來的弱泛化的缺陷。因為按照信息增益選擇,總是會傾向于選擇分支多的屬性,這樣會是的每個子集的信息熵最小。例如給每個數據添加一個第一無二的id值特征,則按照這個id值進行分類是獲得信息增益最大的,這樣每個子集中的信息熵都為0,但是這樣的分類便沒有任何意義,沒有任何泛化能力,類似過擬合。
因此我們可以通過引入一個分裂信息來找到一個更合適的衡量數據劃分的標準,即增益比率。
分裂信息的公式表示為:
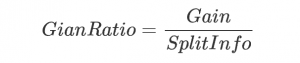
當然SplitInfo有可能趨近于0,這個時候增益比率就會變得非常大而不可信,因此有時還需在分母上添加一個平滑函數,具體的可以參考參考部分列出的文章
基尼不純度(Gini impurity)
基尼不純度的定義:
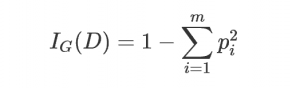
其中m 表示數據集D 中類別的個數, pi 表示某種類型出現的概率。可見當只有一種類型的時候基尼不純度的值為0,此時不純度最低。
針對劃分成k個子數據集的數據集的基尼不純度可以通過如下式子計算:
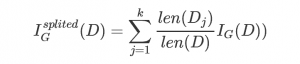
由此我們可以根據不純度的變化來選取最有的樹分裂屬性
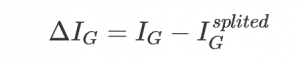
樹分裂
有了選取最佳分裂屬性的算法,下面我們就需要根據選擇的屬性來將樹進一步的分裂。所謂樹分裂只不過是根據選擇的屬性將數據集劃分,然后在總劃分出來的數據集中再次調用選取屬性的方法選取子數據集的中屬性。實現的最好方式就是遞歸了.
關于用什么數據結構來表示決策樹,在Python中可以使用字典很方便的表示決策樹的嵌套,一個樹的根節點便是屬性,屬性對應的值又是一個新的字典,其中key為屬性的可能值,value為新的子樹。
下面是我使用Python實現的根據數據集創建決策樹:
- def create_tree(self, dataset, classes, feat_names):
- ''' 根據當前數據集遞歸創建決策樹
- :param dataset: 數據集
- :param feat_names: 數據集中數據相應的特征名稱
- :param classes: 數據集中數據相應的類型
- :param tree: 以字典形式返回決策樹
- '''
- # 如果數據集中只有一種類型停止樹分裂
- if len(set(classes)) == 1:
- return classes[0]
- # 如果遍歷完所有特征,返回比例最多的類型
- if len(feat_names) == 0:
- return get_majority(classes)
- # 分裂創建新的子樹
- tree = {}
- best_feat_idx = self.choose_best_split_feature(dataset, classes)
- feature = feat_names[best_feat_idx]
- tree[feature] = {}
- # 創建用于遞歸創建子樹的子數據集
- sub_feat_names = feat_names[:]
- sub_feat_names.pop(best_feat_idx)
- splited_dict = self.split_dataset(dataset, classes, best_feat_idx)
- for feat_val, (sub_dataset, sub_classes) in splited_dict.items():
- tree[feature][feat_val] = self.create_tree(sub_dataset,
- sub_classes,
- sub_feat_names)
- self.tree = tree
- self.feat_names = feat_names
- return tree
樹分裂的終止條件有兩個
- 一個是遍歷完所有的屬性
可以看到,在進行樹分裂的時候,我們的數據集中的數據向量的長度是不斷縮短的,當縮短到0時,說明數據集已經將所有的屬性用盡,便也分裂不下去了, 這時我們選取最終子數據集中的眾數作為最終的分類結果放到葉子節點上.
- 另一個是新劃分的數據集中只有一個類型。
若某個節點所指向的數據集都是同一種類型,那自然沒有必要在分裂下去了即使屬性還沒有遍歷完.
構建一棵決策樹
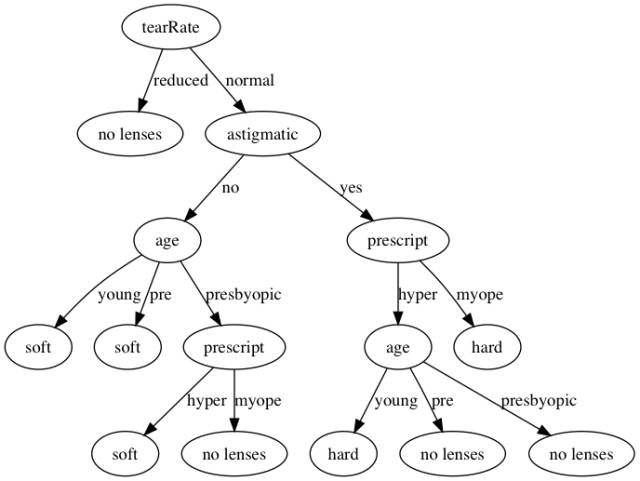
這我用了一下MLiA書上附帶的隱形眼鏡的數據來生成一棵決策樹,數據中包含了患者眼部狀況以及醫生推薦的隱形眼鏡類型.
首先先導入數據并將數據特征同類型分開作為訓練數據用于生成決策樹
- from trees import DecisionTreeClassifier
- lense_labels = ['age', 'prescript', 'astigmatic', 'tearRate']
- X = []
- Y = []
- with open('lenses.txt', 'r') as f:
- for line in f:
- comps = line.strip().split('\t')
- X.append(comps[: -1])
- Y.append(comps[-1])
生成決策樹:
- clf = DecisionTreeClassifier()
- clf.create_tree(X, Y, lense_labels)
查看生成的決策樹:
- In [2]: clf.tree
- Out[2]:
- {'tearRate': {'normal': {'astigmatic': {'no': {'age': {'pre': 'soft',
- 'presbyopic': {'prescript': {'hyper': 'soft', 'myope': 'no lenses'}},
- 'young': 'soft'}},
- 'yes': {'prescript': {'hyper': {'age': {'pre': 'no lenses',
- 'presbyopic': 'no lenses',
- 'young': 'hard'}},
- 'myope': 'hard'}}}},
- 'reduced': 'no lenses'}}
可視化決策樹
直接通過嵌套字典表示決策樹對人來說不好理解,我們需要借助可視化工具可視化樹結構,這里我將使用Graphviz來可視化樹結構。為此實現了講字典表示的樹生成Graphviz Dot文件內容的函數,大致思想就是遞歸獲取整棵樹的所有節點和連接節點的邊然后將這些節點和邊生成Dot格式的字符串寫入文件中并繪圖。
遞歸獲取樹的節點和邊,其中使用了uuid給每個節點添加了id屬性以便將相同屬性的節點區分開.
- def get_nodes_edges(self, tree=None, root_node=None):
- ''' 返回樹中所有節點和邊
- '''
- Node = namedtuple('Node', ['id', 'label'])
- Edge = namedtuple('Edge', ['start', 'end', 'label'])
- if tree is None:
- tree = self.tree
- if type(tree) is not dict:
- return [], []
- nodes, edges = [], []
- if root_node is None:
- label = list(tree.keys())[0]
- root_node = Node._make([uuid.uuid4(), label])
- nodes.append(root_node)
- for edge_label, sub_tree in tree[root_node.label].items():
- node_label = list(sub_tree.keys())[0] if type(sub_tree) is dict else sub_tree
- sub_node = Node._make([uuid.uuid4(), node_label])
- nodes.append(sub_node)
- edge = Edge._make([root_node, sub_node, edge_label])
- edges.append(edge)
- sub_nodes, sub_edges = self.get_nodes_edges(sub_tree, root_node=sub_node)
- nodes.extend(sub_nodes)
- edges.extend(sub_edges)
- return nodes, edges
生成dot文件內容
- def dotify(self, tree=None):
- ''' 獲取樹的Graphviz Dot文件的內容
- '''
- if tree is None:
- tree = self.tree
- content = 'digraph decision_tree {\n'
- nodes, edges = self.get_nodes_edges(tree)
- for node in nodes:
- content += ' "{}" [label="{}"];\n'.format(node.id, node.label)
- for edge in edges:
- start, label, end = edge.start, edge.label, edge.end
- content += ' "{}" -> "{}" [label="{}"];\n'.format(start.id, end.id, label)
- content += '}'
- return content
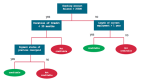
隱形眼鏡數據生成Dot文件內容如下:
- digraph decision_tree {
- "959b4c0c-1821-446d-94a1-c619c2decfcd" [label="call"];
- "18665160-b058-437f-9b2e-05df2eb55661" [label="to"];
- "2eb9860d-d241-45ca-85e6-cbd80fe2ebf7" [label="your"];
- "bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd" [label="areyouunique"];
- "ca091fc7-8a4e-4970-9ec3-485a4628ad29" [label="02073162414"];
- "aac20872-1aac-499d-b2b5-caf0ef56eff3" [label="ham"];
- "18aa8685-a6e8-4d76-bad5-ccea922bb14d" [label="spam"];
- "3f7f30b1-4dbb-4459-9f25-358ad3c6d50b" [label="spam"];
- "44d1f972-cd97-4636-b6e6-a389bf560656" [label="spam"];
- "7f3c8562-69b5-47a9-8ee4-898bd4b6b506" [label="i"];
- "a6f22325-8841-4a81-bc04-4e7485117aa1" [label="spam"];
- "c181fe42-fd3c-48db-968a-502f8dd462a4" [label="ldn"];
- "51b9477a-0326-4774-8622-24d1d869a283" [label="ham"];
- "16f6aecd-c675-4291-867c-6c64d27eb3fc" [label="spam"];
- "adb05303-813a-4fe0-bf98-c319eb70be48" [label="spam"];
- "959b4c0c-1821-446d-94a1-c619c2decfcd" -> "18665160-b058-437f-9b2e-05df2eb55661" [label="0"];
- "18665160-b058-437f-9b2e-05df2eb55661" -> "2eb9860d-d241-45ca-85e6-cbd80fe2ebf7" [label="0"];
- "2eb9860d-d241-45ca-85e6-cbd80fe2ebf7" -> "bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd" [label="0"];
- "bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd" -> "ca091fc7-8a4e-4970-9ec3-485a4628ad29" [label="0"];
- "ca091fc7-8a4e-4970-9ec3-485a4628ad29" -> "aac20872-1aac-499d-b2b5-caf0ef56eff3" [label="0"];
- "ca091fc7-8a4e-4970-9ec3-485a4628ad29" -> "18aa8685-a6e8-4d76-bad5-ccea922bb14d" [label="1"];
- "bcbcc17c-9e2a-4bd4-a039-6e51fde5f8fd" -> "3f7f30b1-4dbb-4459-9f25-358ad3c6d50b" [label="1"];
- "2eb9860d-d241-45ca-85e6-cbd80fe2ebf7" -> "44d1f972-cd97-4636-b6e6-a389bf560656" [label="1"];
- "18665160-b058-437f-9b2e-05df2eb55661" -> "7f3c8562-69b5-47a9-8ee4-898bd4b6b506" [label="1"];
- "7f3c8562-69b5-47a9-8ee4-898bd4b6b506" -> "a6f22325-8841-4a81-bc04-4e7485117aa1" [label="0"];
- "7f3c8562-69b5-47a9-8ee4-898bd4b6b506" -> "c181fe42-fd3c-48db-968a-502f8dd462a4" [label="1"];
- "c181fe42-fd3c-48db-968a-502f8dd462a4" -> "51b9477a-0326-4774-8622-24d1d869a283" [label="0"];
- "c181fe42-fd3c-48db-968a-502f8dd462a4" -> "16f6aecd-c675-4291-867c-6c64d27eb3fc" [label="1"];
- "959b4c0c-1821-446d-94a1-c619c2decfcd" -> "adb05303-813a-4fe0-bf98-c319eb70be48" [label="1"];
- }
這樣我們便可以使用Graphviz將決策樹繪制出來
- with open('lenses.dot', 'w') as f:
- dot = clf.tree.dotify()
- f.write(dot)
- dot -Tgif lenses.dot -o lenses.gif
效果如下:
使用生成的決策樹進行分類
對未知數據進行預測,主要是根據樹中的節點遞歸的找到葉子節點即可。z這里可以通過為遞歸進行優化,代碼實現如下:
- def classify(self, data_vect, feat_names=None, tree=None):
- ''' 根據構建的決策樹對數據進行分類
- '''
- if tree is None:
- tree = self.tree
- if feat_names is None:
- feat_names = self.feat_names
- # Recursive base case.
- if type(tree) is not dict:
- return tree
- feature = list(tree.keys())[0]
- value = data_vect[feat_names.index(feature)]
- sub_tree = tree[feature][value]
- return self.classify(feat_names, data_vect, sub_tree)
決策樹的存儲
通過字典表示決策樹,這樣我們可以通過內置的pickle或者json模塊將其存儲到硬盤上,同時也可以從硬盤中讀取樹結構,這樣在數據集很大的時候可以節省構建決策樹的時間.
- def dump_tree(self, filename, tree=None):
- ''' 存儲決策樹
- '''
- if tree is None:
- tree = self.tree
- with open(filename, 'w') as f:
- pickle.dump(tree, f)
- def load_tree(self, filename):
- ''' 加載樹結構
- '''
- with open(filename, 'r') as f:
- tree = pickle.load(f)
- self.tree = tree
- return tree
總結
本文一步步實現了決策樹的實現, 其中使用了ID3算法確定最佳劃分屬性,并通過Graphviz可視化了構建的決策樹。本文相關的代碼鏈接: https://github.com/PytLab/MLBox/tree/master/decision_tree
參考:
- 《Machine Learning in Action》
- 數據挖掘系列(6)決策樹分類算法