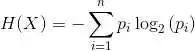機(jī)器學(xué)習(xí)方法之決策樹建模
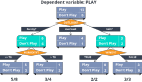
決策樹是一種簡單的機(jī)器學(xué)習(xí)方法。決策樹經(jīng)過訓(xùn)練之后,看起來像是以樹狀形式排列的一系列if-then語句。一旦我們有了決策樹,只要沿著樹的路徑一直向下,正確回答每一個問題,最終就會得到答案。沿著最終的葉節(jié)點(diǎn)向上回溯,就會得到一個有關(guān)最終分類結(jié)果的推理過程。
決策樹:
- class decisionnode:
- def __init__(self,col=-1,value=None,results=None,tb=None,fb=None):
- self.col=col #待檢驗(yàn)的判斷條件
- self.value=value #對應(yīng)于為了使結(jié)果為true,當(dāng)前列必須匹配的值
- self.results=results #針對當(dāng)前分支的結(jié)果
- self.tb=tb #結(jié)果為true時,樹上相對于當(dāng)前節(jié)點(diǎn)的子樹上的節(jié)點(diǎn)
- self.fb=fb #結(jié)果為false時,樹上相對于當(dāng)前節(jié)點(diǎn)的子樹上的節(jié)點(diǎn)
下面利用分類回歸樹的算法。為了構(gòu)造決策樹,算法首先創(chuàng)建一個根節(jié)點(diǎn),然后評估表中的所有觀測變量,從中選出最合適的變量對數(shù)據(jù)進(jìn)行拆分。為了選擇合適的變量,我們需要一種方法來衡量數(shù)據(jù)集合中各種因素的混合情況。對于混雜程度的測度,有幾種度量方式可供選擇:
基尼不純度:將來自集合中的某種結(jié)果隨機(jī)應(yīng)用于集合中某一數(shù)據(jù)項(xiàng)的預(yù)期誤差率。
維基上的公式是這樣:

下面是《集體智慧編程》中的python實(shí)現(xiàn):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def uniquecounts(rows): results={} for row in rows: # The result is the last column r=row[len(row)-1] if r not in results: results[r]=0 results[r]+=1 return results
def giniimpurity(rows): total=len(rows) counts=uniquecounts(rows) imp=0 for k1 in counts: p1=float(counts[k1])/total #imp+=p1*p1 for k2 in counts: if k1==k2: continue p2=float(counts[k2])/total imp+=p1*p2 return imp#1-imp |
每一結(jié)果出現(xiàn)次數(shù)除以集合總行數(shù)來計(jì)算相應(yīng)概率,然后把所有這些概率值的乘積累加起來。這樣得到某一行數(shù)據(jù)被隨機(jī)分配到錯誤結(jié)果的總概率。(顯然直接按照公式的算法(注釋中)效率更高。)這一概率越高,說明對數(shù)據(jù)的拆分越不理想。
熵:代表集合的無序程度。信息論熵的概念在吳軍的《數(shù)學(xué)之美》中有很好的解釋:
我們來看一個例子,馬上要舉行世界杯賽了。大家都很關(guān)心誰會是冠軍。假如我錯過了看世界杯,賽后我問一個知道比賽結(jié)果的觀 眾“哪支球隊(duì)是冠軍”? 他不愿意直接告訴我, 而要讓我猜,并且我每猜一次,他要收一元錢才肯告訴我是否猜對了,那么我需要付給他多少錢才能知道誰是冠軍呢? 我可以把球隊(duì)編上號,從 1 到 32, 然后提問: “冠軍的球隊(duì)在 1-16 號中嗎?” 假如他告訴我猜對了, 我會接著問: “冠軍在 1-8 號中嗎?” 假如他告訴我猜錯了, 我自然知道冠軍隊(duì)在 9-16 中。 這樣只需要五次, 我就能知道哪支球隊(duì)是冠軍。所以,誰是世界杯冠軍這條消息的信息量只值五塊錢。 當(dāng)然,香農(nóng)不是用錢,而是用 “比特”(bit)這個概念來度量信息量。 一個比特是一位二進(jìn)制數(shù),計(jì)算機(jī)中的一個字節(jié)是八個比特。在上面的例子中,這條消息的信息量是五比特。(如果有朝一日有六十四個隊(duì)進(jìn)入決賽階段的比賽,那 么“誰世界杯冠軍”的信息量就是六比特,因?yàn)槲覀円嗖乱淮巍#?讀者可能已經(jīng)發(fā)現(xiàn), 信息量的比特?cái)?shù)和所有可能情況的對數(shù)函數(shù) log 有關(guān)。 (log32=5, log64=6。) 有些讀者此時可能會發(fā)現(xiàn)我們實(shí)際上可能不需要猜五次就能猜出誰是冠軍,因?yàn)橄蟀臀鳌⒌聡⒁?大利這樣的球隊(duì)得冠軍的可能性比日本、美國、韓國等隊(duì)大的多。因此,我們第一次猜測時不需要把 32 個球隊(duì)等分成兩個組,而可以把少數(shù)幾個最可能的球隊(duì)分成一組,把其它隊(duì)分成另一組。然后我們猜冠軍球隊(duì)是否在那幾只熱門隊(duì)中。我們重復(fù)這樣的過程,根據(jù)奪 冠概率對剩下的候選球隊(duì)分組,直到找到冠軍隊(duì)。這樣,我們也許三次或四次就猜出結(jié)果。因此,當(dāng)每個球隊(duì)奪冠的可能性(概率)不等時,“誰世界杯冠軍”的信 息量的信息量比五比特少。香農(nóng)指出,它的準(zhǔn)確信息量應(yīng)該是
= -(p1*log p1 + p2 * log p2 + ... +p32 *log p32), 其 中,p1,p2 , ...,p32 分別是這 32 個球隊(duì)奪冠的概率。香農(nóng)把它稱為“信息熵” (Entropy),一般用符號 H 表示,單位是比特。有興趣的讀者可以推算一下當(dāng) 32 個球隊(duì)奪冠概率相同時,對應(yīng)的信息熵等于五比特。有數(shù)學(xué)基礎(chǔ)的讀者還可以證明上面公式的值不可能大于五。對于任意一個隨機(jī)變量 X(比如得冠軍的球隊(duì)),它的熵定義如下:

《集》中的實(shí)現(xiàn):
|
1 2 3 4 5 6 7 8 9 10 |
def entropy(rows): from math import log log2=lambda x:log(x)/log(2) results=uniquecounts(rows) # Now calculate the entropy ent=0.0 for r in results.keys(): p=float(results[r])/len(rows) ent=ent-p*log2(p) return ent |
熵和基尼不純度之間的主要區(qū)別在于,熵達(dá)到峰值的過程要相對慢一些。因此,熵對于混亂集合的判罰要更重一些。
我們的算法首先求出整個群組的熵,然后嘗試?yán)妹總€屬性的可能取值對群組進(jìn)行拆分,并求出兩個新群組的熵。算法會計(jì)算相應(yīng)的信息增益。信息增益是指當(dāng)前熵與兩個新群組經(jīng)加權(quán)平均后的熵之間的差值。算法會對每個屬性計(jì)算相應(yīng)的信息增益,然后從中選出信息增益最大的屬性。通過計(jì)算每個新生節(jié)點(diǎn)的最佳拆分屬性,對分支的拆分過程和樹的構(gòu)造過程會不斷持續(xù)下去。當(dāng)拆分某個節(jié)點(diǎn)所得的信息增益不大于0的時候,對分支的拆分才會停止:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
def buildtree(rows,scoref=entropy): if len(rows)==0: return decisionnode() current_score=scoref(rows)
# Set up some variables to track the best criteria best_gain=0.0 best_criteria=None best_sets=None
column_count=len(rows[0])-1 for col in range(0,column_count): # Generate the list of different values in # this column column_values={} for row in rows: column_values[row[col]]=1 # Now try dividing the rows up for each value # in this column for value in column_values.keys(): (set1,set2)=divideset(rows,col,value)
# Information gain p=float(len(set1))/len(rows) gain=current_score-p*scoref(set1)-(1-p)*scoref(set2) if gain>best_gain and len(set1)>0 and len(set2)>0: best_gain=gain best_criteria=(col,value) best_sets=(set1,set2) # Create the sub branches if best_gain>0: trueBranch=buildtree(best_sets[0]) falseBranch=buildtree(best_sets[1]) return decisionnode(col=best_criteria[0],value=best_criteria[1], tb=trueBranch,fb=falseBranch) else: return decisionnode(results=uniquecounts(rows)) |
函數(shù)首先接受一個由數(shù)據(jù)行構(gòu)成的列表作為參數(shù)。它遍歷了數(shù)據(jù)集中的每一列,針對各列查找每一種可能的取值,并將數(shù)據(jù)集拆分成兩個新的子集。通過將每個子集的熵乘以子集中所含數(shù)據(jù)項(xiàng)在元數(shù)據(jù)集中所占的比重,函數(shù)求出了每一對新生子集的甲醛平均熵,并記錄下熵最低的那一對子集。如果由熵值最低的一對子集求得的加權(quán)平均熵比當(dāng)前集合的當(dāng)前集合的熵要大,則拆分結(jié)束了,針對各種可能結(jié)果的計(jì)數(shù)所得將會被保存起來。否則,算法會在新生成的子集繼續(xù)調(diào)用buildtree函數(shù),并把調(diào)用所得的結(jié)果添加到樹上。我們把針對每個子集的調(diào)用結(jié)果,分別附加到節(jié)點(diǎn)的True分支和False分支上,最終整棵樹就這樣構(gòu)造出來了。
我們可以把它打印出來:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def printtree(tree,indent=''): # Is this a leaf node? if tree.results!=None: print str(tree.results) else: # Print the criteria print str(tree.col)+':'+str(tree.value)+'? '
# Print the branches print indent+'T->', printtree(tree.tb,indent+' ') print indent+'F->', printtree(tree.fb,indent+' ') |
現(xiàn)在到我們使用決策樹的時候了。接受新的觀測數(shù)據(jù)作為參數(shù),然后根據(jù)決策樹對其分類:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def classify(observation,tree): if tree.results!=None: return tree.results else: v=observation[tree.col] branch=None if isinstance(v,int) or isinstance(v,float): if v>=tree.value: branch=tree.tb else: branch=tree.fb else: if v==tree.value: branch=tree.tb else: branch=tree.fb return classify(observation,branch) |
該函數(shù)采用與printtree相同的方式對樹進(jìn)行遍歷。每次調(diào)用后,函數(shù)會根據(jù)調(diào)用結(jié)果來判斷是否到達(dá)分支的末端。如果尚未到達(dá)末端,它會對觀測數(shù)據(jù)評估,以確認(rèn)列數(shù)據(jù)是否與參考值匹配。如果匹配,則會在True分支調(diào)用classify,不匹配則在False分支調(diào)用classify。
上面方法訓(xùn)練決策樹會有一個問題:
過度擬合:它可能會變得過于針對訓(xùn)練數(shù)據(jù),其熵值與真實(shí)情況相比可能會有所降低。剪枝的過程就是對具有相同父節(jié)點(diǎn)的一組節(jié)點(diǎn)進(jìn)行檢查,判斷如果將其合并,熵的增加量是否會小于某個指定的閾值。如果確實(shí)如此,則這些葉節(jié)點(diǎn)會被合并成一個單一的節(jié)點(diǎn),合并后的新節(jié)點(diǎn)包含了所有可能的結(jié)果值。這種做法有助于過度避免過度擬合的情況,使得決策樹做出的預(yù)測結(jié)果,不至于比從數(shù)據(jù)集中得到的實(shí)際結(jié)論還要特殊:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
def prune(tree,mingain): # 如果分支不是葉節(jié)點(diǎn),則對其進(jìn)行剪枝操作 if tree.tb.results==None: prune(tree.tb,mingain) if tree.fb.results==None: prune(tree.fb,mingain)
# 如果兩個分支都是葉節(jié)點(diǎn),則判斷它們是否需要合并 if tree.tb.results!=None and tree.fb.results!=None: # 構(gòu)造合并后的數(shù)據(jù)集 tb,fb=[],[] for v,c in tree.tb.results.items(): tb+=[[v]]*c for v,c in tree.fb.results.items(): fb+=[[v]]*c
# 檢查熵的減少情況 delta=entropy(tb+fb)-(entropy(tb)+entropy(fb)/2)
if delta<mingain: # 合并分支 tree.tb,tree.fb=None,None tree.results=uniquecounts(tb+fb) |
當(dāng)我們在根節(jié)點(diǎn)調(diào)用上述函數(shù)時,算法將沿著樹的所有路徑向下遍歷到只包含葉節(jié)點(diǎn)的節(jié)點(diǎn)處。函數(shù)會將兩個葉節(jié)點(diǎn)中的結(jié)果值合起來形成一個新的列表,同時還會對熵進(jìn)行測試。如果熵的變化小于mingain參數(shù)指定的值,則葉節(jié)點(diǎn)也可能成為刪除對象,以及與其它節(jié)點(diǎn)的合并對象。
如果我們?nèi)笔Я四承?shù)據(jù),而這些數(shù)據(jù)是確定分支走向所必需的,那么我們可以選擇兩個分支都走。在一棵基本的決策樹中,所有節(jié)點(diǎn)都隱含有一個值為1的權(quán)重,即觀測數(shù)據(jù)項(xiàng)是否屬于某個特定分類的概率具有百分之百的影響。而如果要走多個分支的話,那么我們可以給每個分支賦以一個權(quán)重,其值等于所有位于該分支的其它數(shù)據(jù)行所占的比重:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
def mdclassify(observation,tree): if tree.results!=None: return tree.results else: v=observation[tree.col] if v==None: tr,fr=mdclassify(observation,tree.tb),mdclassify(observation,tree.fb) tcount=sum(tr.values()) fcount=sum(fr.values()) tw=float(tcount)/(tcount+fcount) fw=float(fcount)/(tcount+fcount) result={} for k,v in tr.items(): result[k]=v*tw for k,v in fr.items(): result[k]=v*fw return result else: if isinstance(v,int) or isinstance(v,float): if v>=tree.value: branch=tree.tb else: branch=tree.fb else: if v==tree.value: branch=tree.tb else: branch=tree.fb return mdclassify(observation,branch) |
mdclassify與classify相比,唯一的區(qū)別在于末尾處:如果發(fā)現(xiàn)有重要數(shù)據(jù)缺失,則每個分支的對應(yīng)結(jié)果值都會被計(jì)算一遍,并且最終的結(jié)果值會乘以它們各自的權(quán)重。
對與數(shù)值型問題,我們可以使用方差作為評價函數(shù)來取代熵或基尼不純度。偏低的方差代表數(shù)字彼此都非常接近,而偏高的方差則意味著數(shù)字分散得很開。這樣,選擇節(jié)點(diǎn)判斷條件的依據(jù)就變成了拆分后令數(shù)字較大者位于樹的一側(cè),數(shù)字較小者位于樹的另一側(cè)。