使用Python+機器學(xué)習(xí)方法進(jìn)行情感分析(詳細(xì)步驟)
不是有詞典匹配的方法了嗎?怎么還搞多個機器學(xué)習(xí)方法。
因為詞典方法和機器學(xué)習(xí)方法各有千秋。
機器學(xué)習(xí)的方法精確度更高,因為詞典匹配會由于語義表達(dá)的豐富性而出現(xiàn)很大誤差,而機器學(xué)習(xí)方法不會。而且它可使用的場景更多樣。無論是主客觀分類還是正負(fù)面情感分類,機器學(xué)習(xí)都可以完成任務(wù)。而無需像詞典匹配那樣要深入到詞語、句子、語法這些層面。
而詞典方法適用的語料范圍更廣,無論是手機、電腦這些商品,還是書評、影評這些語料,都可以適用。但機器學(xué)習(xí)則極度依賴語料,把手機語料訓(xùn)練出來的的分類器拿去給書評分類,那是注定要失敗的。
使用機器學(xué)習(xí)進(jìn)行情感分析,可以換一個相同意思的說法,就是用有監(jiān)督的(需要人工標(biāo)注類別)機器學(xué)習(xí)方法來對文本進(jìn)行分類。
這點與詞典匹配有著本質(zhì)的區(qū)別。詞典匹配是直接計算文本中的情感詞,得出它們的情感傾向分值。而機器學(xué)習(xí)方法的思路是先選出一部分表達(dá)積極情感的文本和一部分表達(dá)消極情感的文本,用機器學(xué)習(xí)方法進(jìn)行訓(xùn)練,獲得一個情感分類器。再通過這個情感分類器對所有文本進(jìn)行積極和消極的二分分類。最終的分類可以為文本給出0或1這樣的類別,也可以給出一個概率值,比如”這個文本的積極概率是90%,消極概率是10%“。
Python 有良好的程序包可以進(jìn)行情感分類,那就是Python 自然語言處理包,Natural Language Toolkit ,簡稱NLTK 。
NLTK 當(dāng)然不只是處理情感分析,NLTK 有著整套自然語言處理的工具,從分詞到實體識別,從情感分類到句法分析,完整而豐富,功能強大。實乃居家旅行,越貨殺人之必備良藥。
兩本NLTK 的參考書,非常好用。一本是《Python 自然語言處理》,這是《Natural Language Processing with Python》的中文翻譯版,是志愿者翻譯沒有出版社出版的,開源精神萬歲!另一本是《Python Text Processing with NLTK 2.0 Cookbook》,這本書寫得清晰明了,雖然是英文版的,看起來也很舒服。特別值得一提的是,該書作者Jacob 就是NLTK 包的主要貢獻(xiàn)者之一。而且他的博客中有一系列的文章是關(guān)于使用機器學(xué)習(xí)進(jìn)行情感分類的,我的代碼可以說是完全基于他的,在此表示我的感謝。
其實還有國外作者也被他啟發(fā),用Python 來處理情感分類。比如這篇文章,寫得特別詳細(xì)認(rèn)真,也是我重點參考的文章,他的代碼我也有所借用。
Jacob 在文章中也有提到,近段時間NLTK 新增的scikit-learn 的接口,使得它的分類功能更為強大好用了,可以用很多高端冷艷的分類算法了。于是我又滾過去看scikit-learn 。簡直是天賜我好工具,媽媽再也不用擔(dān)心我用不了機器學(xué)習(xí)啦!
有了scikit-learn 的接口,NLTK 做分類變得比之前更簡單快捷,但是相關(guān)的結(jié)合NLTK 和 sciki-learn 的文章實在少,這篇文章是僅有的講得比較詳細(xì)的把兩者結(jié)合的,在此也表示感謝。
但對于我而言還是有點不夠的,因為中文和英文有一定的差別,而且上面提到的一些博客里面的代碼也是需要改動的。終于把一份代碼啃完之后,能寫出一個跑得通的中文情感分類代碼了。接下來會介紹它的實現(xiàn)思路和具體代碼。
在這個系列的文章里面,機器學(xué)習(xí)都可以認(rèn)為是有監(jiān)督的分類方法。
總體流程如圖:
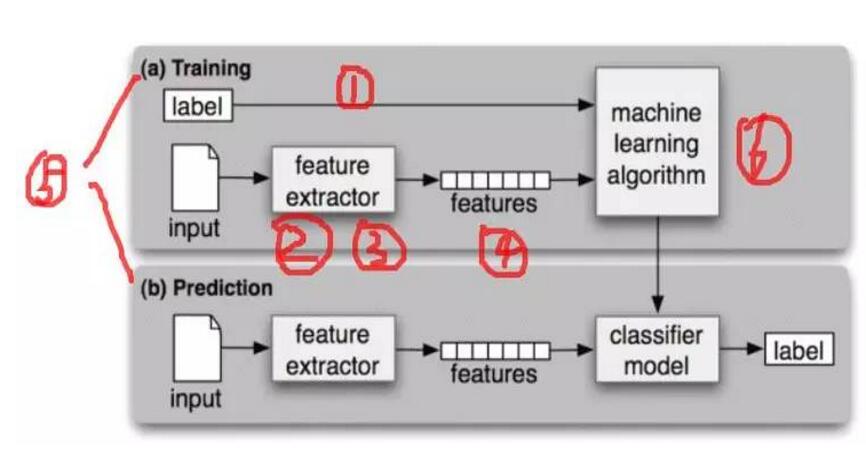
圖1:機器學(xué)習(xí)的流程和結(jié)構(gòu)(摘自《Natural Language Processing with Python》)
一、有監(jiān)督意味著需要人工標(biāo)注,需要人為的給文本一個類標(biāo)簽。
比如我有5000條商品評論,如果我要把這些評論分成積極和消極兩類。那我就可以先從里面選2000條評論,然后對這2000條數(shù)據(jù)進(jìn)行人工標(biāo)注,把這2000條評論標(biāo)為“積極”或“消極”。這“積極”和“消極”就是類標(biāo)簽。
假設(shè)有1000條評論被標(biāo)為“積極”,有1000條評論被標(biāo)為“消極”。(兩者數(shù)量相同對訓(xùn)練分類器是有用的,如果實際中數(shù)量不相同,應(yīng)該減少和增加數(shù)據(jù)以使得它們數(shù)量相同)
二、之后就要選擇特征。
特征就是分類對象所展現(xiàn)的部分特點,是實現(xiàn)分類的依據(jù)。我們經(jīng)常會做出分類的行為,那我們依據(jù)些什么進(jìn)行分類呢?
舉個例子,如果我看到一個年輕人,穿著新的正裝,提著嶄新的公文包,快步行走,那我就會覺得他是一個剛?cè)肼毜穆殘鲂氯恕T谶@里面,“嶄新”,“正裝”,“公文包”,“快步行走”都是這個人所展現(xiàn)出的特點,也是我用來判斷這個人屬于哪一類的依據(jù)。這些特點和依據(jù)就是特征。可能有些特征對我判斷更有用,有些對我判斷沒什么用,有些可能會讓我判斷錯誤,但這些都是我分類的依據(jù)。
我們沒辦法發(fā)現(xiàn)一個人的所有特點,所以我們沒辦法客觀的選擇所有特點,我們只能主觀的選擇一部分特點來作為我分類的依據(jù)。這也是特征選擇的特點,需要人為的進(jìn)行一定選擇。
而在情感分類中,一般從“詞”這個層次來選擇特征。
比如這句話“手機非常好用!”,我給了它一個類標(biāo)簽“Positive”。里面有四個詞(把感嘆號也算上),“手機”,“非常”,“好用”,“!”。我可以認(rèn)為這4個詞都對分類產(chǎn)生了影響,都是分類的依據(jù)。也就是無論什么地方出現(xiàn)了這四個詞的其中之一,文本都可以被分類為“積極”。這個是把所有詞都作為分類特征。
同樣的,對這句話,我也可以選擇它的雙詞搭配(Bigrams)作為特征。比如“手機 非常”,“非常 好用”,“好用 !”這三個搭配作為分類的特征。以此類推,三詞搭配(Trigrams),四詞搭配都是可以被作為特征的。
三、再之后特征要降維。
特征降維說白了就是減少特征的數(shù)量。這有兩個意義,一個是特征數(shù)量減少了之后可以加快算法計算的速度(數(shù)量少了當(dāng)然計算就快了),另一個是如果用一定的方法選擇信息量豐富的特征,可以減少噪音,有效提高分類的準(zhǔn)確率。
所謂信息量豐富,可以看回上面這個例子“手機非常好用!”,很明顯,其實不需要把“手機”,“非常”,“好用”,“!”這4個都當(dāng)做特征,因為“好用”這么一個詞,或者“非常 好用”這么一個雙詞搭配就已經(jīng)決定了這個句子是“積極”的。這就是說,“好用”這個詞的信息量非常豐富。
那要用什么方法來減少特征數(shù)量呢?答案是通過一定的統(tǒng)計方法找到信息量豐富的特征。
統(tǒng)計方法包括:詞頻(Term Frequency)、文檔頻率(Document Frequency)、互信息(Pointwise Mutual Information)、信息熵(Information Entropy)、卡方統(tǒng)計(Chi-Square)等等。
在情感分類中,用詞頻選擇特征,也就是選在語料庫中出現(xiàn)頻率高的詞。比如我可以選擇語料庫中詞頻最高的2000個詞作為特征。用文檔頻率選特征,是選在語料庫的不同文檔中出現(xiàn)頻率最高的詞。而其它三個,太高端冷艷,表示理解得還不清楚,暫且不表。。。
不過意思都是一樣的,都是要通過某個統(tǒng)計方法選擇信息量豐富的特征。特征可以是詞,可以是詞組合。
四、把語料文本變成使用特征表示。
在使用分類算法進(jìn)行分類之前,***步是要把所有原始的語料文本轉(zhuǎn)化為特征表示的形式。
還是以上面那句話做例子,“手機非常好用!”
- 如果在NLTK 中,如果選擇所有詞作為特征,其形式是這樣的:[ {“手機”: True, “非常”: True, “好用”: True, “!”: True} , positive]
- 如果選擇雙詞作為特征,其形式是這樣的:[ {“手機 非常”: True, “非常 好用”: True, “好用 !”: True} , positive ]
- 如果選擇信息量豐富的詞作為特征,其形式是這樣的:[ {“好用”: True} , positive ]
(NLTK需要使用字典和數(shù)組兩個數(shù)據(jù)類型,True 表示對應(yīng)的元素是特征。至于為什么要用True 這樣的方式,我也不知道。。。反正見到的例子都是這樣的。。。有空再研究看是不是可以不這樣的吧)
無論使用什么特征選擇方法,其形式都是一樣的。都是[ {“特征1”: True, “特征2”: True, “特征N”: True, }, 類標(biāo)簽 ]
五、把用特征表示之后的文本分成開發(fā)集和測試集,把開發(fā)集分成訓(xùn)練集和開發(fā)測試集。
機器學(xué)習(xí)分類必須有數(shù)據(jù)給分類算法訓(xùn)練,這樣才能得到一個(基于訓(xùn)練數(shù)據(jù)的)分類器。
有了分類器之后,就需要檢測這個分類器的準(zhǔn)確度。
根據(jù)《Python 自然語言處理》的方法,數(shù)據(jù)可以分為開發(fā)集合測試集。開發(fā)集專門用于不斷調(diào)整和發(fā)現(xiàn)***的分類算法和特征維度(數(shù)量),測試集應(yīng)該一直保持“不被污染”。在開發(fā)集開發(fā)完畢之后,再使用測試集檢驗由開發(fā)集確定的***算法和特征維度的效果。具體如圖:
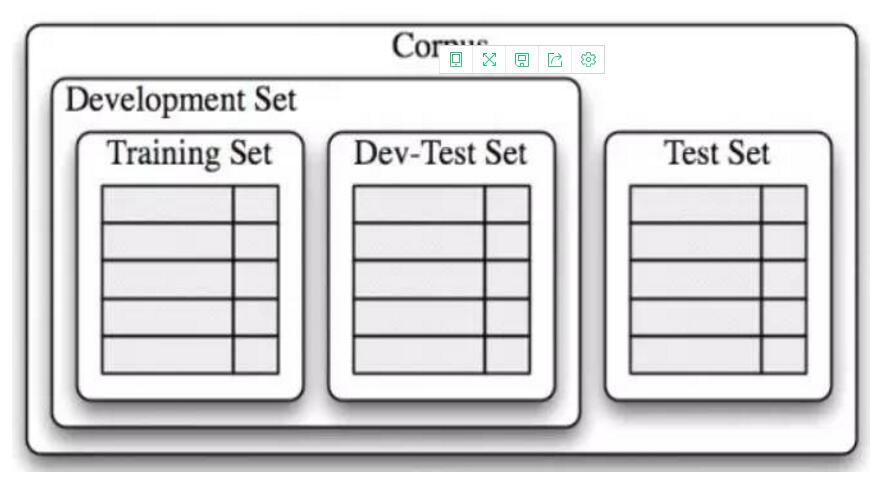
圖2:開發(fā)集和測試集(摘自《Natural Language Processing with Python》)
一般來說,訓(xùn)練集的數(shù)量應(yīng)該遠(yuǎn)大于測試集,這樣分類算法才能找出里面的規(guī)律,構(gòu)建出高效的分類器。
用回前面的例子。假設(shè)2000條已經(jīng)標(biāo)注了積極和消極的評論數(shù)據(jù),開發(fā)集可以是隨機的1600條,測試集是剩余的隨機400條。然后開發(fā)集中,訓(xùn)練集可以是隨機的1400條,開發(fā)測試集是200條。
六、用不同的分類算法給訓(xùn)練集構(gòu)建分類器,用開發(fā)測試集檢驗分類器的準(zhǔn)確度(選出***算法后可以調(diào)整特征的數(shù)量來測試準(zhǔn)確度)。
這個時候終于可以使用各種高端冷艷的機器學(xué)習(xí)算法啦!
我們的目標(biāo)是:找到***的機器學(xué)習(xí)算法。
可以使用樸素貝葉斯(NaiveBayes),決策樹(Decision Tree)等NLTK 自帶的機器學(xué)習(xí)方法。也可以更進(jìn)一步,使用NLTK 的scikit-learn 接口,這樣就可以調(diào)用scikit-learn 里面的所有,對,是所有機器學(xué)習(xí)算法了。我已經(jīng)忍不住的淚流滿面。
其實方法很容易。只要以下五步。
- 僅僅使用開發(fā)集(Development Set)。
- 用分類算法訓(xùn)練里面的訓(xùn)練集(Training Set),得出分類器。
- 用分類器給開發(fā)測試集分類(Dev-Test Set),得出分類結(jié)果。
- 對比分類器給出的分類結(jié)果和人工標(biāo)注的正確結(jié)果,給出分類器的準(zhǔn)確度。
- 使用另一個分類算法,重復(fù)以上三步。
在檢驗完所有算法的分類準(zhǔn)確度之后,就可以選出***的一個分類算法了。
在選出***的分類算法之后,就可以測試不同的特征維度對分類準(zhǔn)確度的影響了。一般來說,特征太少則不足以反映分類的所有特點,使得分類準(zhǔn)確率低;特征太多則會引入噪音,干擾分類,也會降低分類準(zhǔn)確度。所以,需要不斷的測試特征的數(shù)量,這樣才可以得到***的分類效果。
七、選擇出開發(fā)集中***的分類算法和特征維度,使用測試集檢驗得出情感分類的準(zhǔn)確度。
在終于得到***分類算法和特征維度(數(shù)量)之后,就可以動用測試集。
直接用***的分類算法對測試集進(jìn)行分類,得出分類結(jié)果。對比分類器的分類結(jié)果和人工標(biāo)注的正確結(jié)果,給出分類器的最終準(zhǔn)確度。
用Python 進(jìn)行機器學(xué)習(xí)及情感分析,需要用到兩個主要的程序包:nltk 和 scikit-learn
nltk 主要負(fù)責(zé)處理特征提取(雙詞或多詞搭配需要使用nltk 來做)和特征選擇(需要nltk 提供的統(tǒng)計方法)。
scikit-learn 主要負(fù)責(zé)分類算法,評價分類效果,進(jìn)行分類等任務(wù)。
接下來會有四篇文章按照以下步驟來實現(xiàn)機器學(xué)習(xí)的情感分析。
- 特征提取和特征選擇(選擇***特征)
- 賦予類標(biāo)簽,分割開發(fā)集和測試集
- 構(gòu)建分類器,檢驗分類準(zhǔn)確度,選擇***分類算法
- 存儲和使用***分類器進(jìn)行分類,分類結(jié)果為概率值
首先是特征提取和選擇
一、特征提取方法
1. 把所有詞作為特征
- def bag_of_words(words):
- return dict([(word, True) for word in words])
返回的是字典類型,這是nltk 處理情感分類的一個標(biāo)準(zhǔn)形式。
2. 把雙詞搭配(bigrams)作為特征
- mport nltk
- from nltk.collocations import BigramCollocationFinder
- from nltk.metrics import BigramAssocMeasures
- def bigram(words, score_fn=BigramAssocMeasures.chi_sq, n=1000):
- bigram_finder = BigramCollocationFinder.from_words(words) #把文本變成雙詞搭配的形式
- bigrams = bigram_finder.nbest(score_fn, n) #使用了卡方統(tǒng)計的方法,選擇排名前1000的雙詞
- return bag_of_words(bigrams)
除了可以使用卡方統(tǒng)計來選擇信息量豐富的雙詞搭配,還可以使用其它的方法,比如互信息(PMI)。而排名前1000也只是人工選擇的閾值,可以隨意選擇其它值,可經(jīng)過測試一步步找到***值。
3. 把所有詞和雙詞搭配一起作為特征
- def bigram_words(words, score_fn=BigramAssocMeasures.chi_sq, n=1000):
- bigram_finder = BigramCollocationFinder.from_words(words)
- bigrams = bigram_finder.nbest(score_fn, n)
- return bag_of_words(words + bigrams) #所有詞和(信息量大的)雙詞搭配一起作為特征
二、特征選擇方法
有了提取特征的方法后,我們就可以提取特征來進(jìn)行分類學(xué)習(xí)了。但一般來說,太多的特征會降低分類的準(zhǔn)確度,所以需要使用一定的方法,來“選擇”出信息量最豐富的特征,再使用這些特征來分類。
特征選擇遵循如下步驟:
- 計算出整個語料里面每個詞的信息量
- 根據(jù)信息量進(jìn)行倒序排序,選擇排名靠前的信息量的詞
- 把這些詞作為特征
1. 計算出整個語料里面每個詞的信息量
1.1 計算整個語料里面每個詞的信息量
- from nltk.probability import FreqDist, ConditionalFreqDist
- def create_word_scores(): posWords = pickle.load(open('D:/code/sentiment_test/pos_review.pkl','r')) ..... return word_scores #包括了每個詞和這個詞的信息量
1.2 計算整個語料里面每個詞和雙詞搭配的信息量
- def create_word_bigram_scores():
- posdata = pickle.load(open('D:/code/sentiment_test/pos_review.pkl','r')) negdata = pickle.load(open('D:/code/sentiment_test/neg_review.pkl','r')) ..... return word_scores
2. 根據(jù)信息量進(jìn)行倒序排序,選擇排名靠前的信息量的詞
- def find_best_words(word_scores, number):
- best_vals = sorted(word_scores.iteritems(), key=lambda (w, s): s, reverse=True)[:number] #把詞按信息量倒序排序。number是特征的維度,是可以不斷調(diào)整直至***的
- best_words = set([w for w, s in best_vals])
- return best_words
然后需要對find_best_words 賦值,如下:
- word_scores_1 = create_word_scores()
- word_scores_2 = create_word_bigram_scores()
3. 把選出的這些詞作為特征(這就是選擇了信息量豐富的特征)
- def best_word_features(words): return dict([(word, True) for word in words if word in best_words])
三、檢測哪中特征選擇方法更優(yōu)
見構(gòu)建分類器,檢驗分類準(zhǔn)確度,選擇***分類算法
***步,載入數(shù)據(jù)。
要做情感分析,首要的是要有數(shù)據(jù)。
數(shù)據(jù)是人工已經(jīng)標(biāo)注好的文本,有一部分積極的文本,一部分是消極的文本。
文本是已經(jīng)分詞去停用詞的商品評論,形式大致如下:[[word11, word12, ... word1n], [word21, word22, ... , word2n], ... , [wordn1, wordn2, ... , wordnn]]
這是一個多維數(shù)組,每一維是一條評論,每條評論是已經(jīng)又該評論的分詞組成。
- #! /usr/bin/env python2.7
- #coding=utf-8
- pos_review = pickle.load(open('D:/code/sentiment_test/pos_review.pkl','r'))
- neg_review = pickle.load(open('D:/code/sentiment_test/neg_review.pkl','r'))
我用pickle 存儲了相應(yīng)的數(shù)據(jù),這里直接載入即可。
第二步,使積極文本的數(shù)量和消極文本的數(shù)量一樣。
- from random import shuffle
- shuffle(pos_review) #把積極文本的排列隨機化
- size = int(len(pos_review)/2 - 18)
- pos = pos_review[:size]
- neg = neg_review
我這里積極文本的數(shù)據(jù)恰好是消極文本的2倍還多18個,所以為了平衡兩者數(shù)量才這樣做。
第三步,賦予類標(biāo)簽。
- def pos_features(feature_extraction_method):
- posFeatures = []
- ....
- negFeatures.append(negWords)
- return negFeatures
這個需要用特征選擇方法把文本特征化之后再賦予類標(biāo)簽。
第四步、把特征化之后的數(shù)據(jù)數(shù)據(jù)分割為開發(fā)集和測試集
- train = posFeatures[174:]+negFeatures[174:]
- devtest = posFeatures[124:174]+negFeatures[124:174]
- test = posFeatures[:124]+negFeatures[:124]
這里把前124個數(shù)據(jù)作為測試集,中間50個數(shù)據(jù)作為開發(fā)測試集,***剩下的大部分?jǐn)?shù)據(jù)作為訓(xùn)練集。
在把文本轉(zhuǎn)化為特征表示,并且分割為開發(fā)集和測試集之后,我們就需要針對開發(fā)集進(jìn)行情感分類器的開發(fā)。測試集就放在一邊暫時不管。
開發(fā)集分為訓(xùn)練集(Training Set)和開發(fā)測試集(Dev-Test Set)。訓(xùn)練集用于訓(xùn)練分類器,而開發(fā)測試集用于檢驗分類器的準(zhǔn)確度。
為了檢驗分類器準(zhǔn)確度,必須對比“分類器的分類結(jié)果”和“人工標(biāo)注的正確結(jié)果”之間的差異。
所以:
- ***步,是要把開發(fā)測試集中,人工標(biāo)注的標(biāo)簽和數(shù)據(jù)分割開來。
- 第二步是使用訓(xùn)練集訓(xùn)練分類器;
- 第三步是用分類器對開發(fā)測試集里面的數(shù)據(jù)進(jìn)行分類,給出分類預(yù)測的標(biāo)簽;第四步是對比分類標(biāo)簽和人工標(biāo)注的差異,計算出準(zhǔn)確度。
一、分割人工標(biāo)注的標(biāo)簽和數(shù)據(jù)
dev, tag_dev = zip(*devtest) #把開發(fā)測試集(已經(jīng)經(jīng)過特征化和賦予標(biāo)簽了)分為數(shù)據(jù)和標(biāo)簽
二到四、可以用一個函數(shù)來做
- def score(classifier):
- classifier = SklearnClassifier(classifier) #在nltk 中使用scikit-learn 的接口
- classifier.train(train) #訓(xùn)練分類器
- pred = classifier.batch_classify(testSet) #對開發(fā)測試集的數(shù)據(jù)進(jìn)行分類,給出預(yù)測的標(biāo)簽
- return accuracy_score(tag_test, pred) #對比分類預(yù)測結(jié)果和人工標(biāo)注的正確結(jié)果,給出分類器準(zhǔn)確度
之后我們就可以簡單的檢驗不同分類器和不同的特征選擇的結(jié)果。
- import sklearn
- .....
- print 'NuSVC`s accuracy is %f' %score(NuSVC())
1. 我選擇了六個分類算法,可以先看到它們在使用所有詞作特征時的效果:
- BernoulliNB`s accuracy is 0.790000
- MultinomiaNB`s accuracy is 0.810000
- LogisticRegression`s accuracy is 0.710000
- SVC`s accuracy is 0.650000
- LinearSVC`s accuracy is 0.680000
- NuSVC`s accuracy is 0.740000
2. 再看使用雙詞搭配作特征時的效果(代碼改動如下地方即可)
- posFeatures = pos_features(bigrams)
- negFeatures = neg_features(bigrams)
結(jié)果如下:
- BernoulliNB`s accuracy is 0.710000 MultinomiaNB`s accuracy is 0.750000 LogisticRegression`s accuracy is 0.790000 SVC`s accuracy is 0.750000 LinearSVC`s accuracy is 0.770000 NuSVC`s accuracy is 0.780000
3. 再看使用所有詞加上雙詞搭配作特征的效果
posFeatures = pos_features(bigram_words) negFeatures = neg_features(bigram_words)
結(jié)果如下:
- BernoulliNB`s accuracy is 0.710000
- MultinomiaNB`s accuracy is 0.750000
- LogisticRegression`s accuracy is 0.790000
- SVC`s accuracy is 0.750000
- LinearSVC`s accuracy is 0.770000
- NuSVC`s accuracy is 0.780000
可以看到在不選擇信息量豐富的特征時,僅僅使用全部的詞或雙詞搭配作為特征,分類器的效果并不理想。
接下來將使用卡方統(tǒng)計量(Chi-square)來選擇信息量豐富的特征,再用這些特征來訓(xùn)練分類器。
4. 計算信息量豐富的詞,并以此作為分類特征
- word_scores = create_word_scores()
- best_words = find_best_words(word_scores, 1500) #選擇信息量最豐富的1500個的特征
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
結(jié)果如下:
- BernoulliNB`s accuracy is 0.870000
- MultinomiaNB`s accuracy is 0.860000
- LogisticRegression`s accuracy is 0.730000
- SVC`s accuracy is 0.770000
- LinearSVC`s accuracy is 0.720000
- NuSVC`s accuracy is 0.780000
可見貝葉斯分類器的分類效果有了很大提升。
5. 計算信息量豐富的詞和雙詞搭配,并以此作為特征
- word_scores = create_word_bigram_scores()
- best_words = find_best_words(word_scores, 1500) #選擇信息量最豐富的1500個的特征
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
結(jié)果如下:
- BernoulliNB`s accuracy is 0.910000
- MultinomiaNB`s accuracy is 0.860000
- LogisticRegression`s accuracy is 0.800000
- SVC`s accuracy is 0.800000
- LinearSVC`s accuracy is 0.750000
- NuSVC`s accuracy is 0.860000
可以發(fā)現(xiàn)貝努利的貝葉斯分類器效果繼續(xù)提升,同時NuSVC 也有很大的提升。
此時,我們選用BernoulliNB、MultinomiaNB、NuSVC 作為候選分類器,使用詞和雙詞搭配作為特征提取方式,測試不同的特征維度的效果。
- dimension = ['500','1000','1500','2000','2500','3000']
- for d in dimension:
- word_scores = create_word_scores_bigram()
- best_words = find_best_words(word_scores, int(d))
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
- train = posFeatures[174:]+negFeatures[174:]
- devtest = posFeatures[124:174]+negFeatures[124:174]
- test = posFeatures[:124]+negFeatures[:124]
- dev, tag_dev = zip(*devtest)
- print 'Feature number %f' %d
- print 'BernoulliNB`s accuracy is %f' %score(BernoulliNB())
- print 'MultinomiaNB`s accuracy is %f' %score(MultinomialNB())
- print 'LogisticRegression`s accuracy is %f' %score(LogisticRegression())
- print 'SVC`s accuracy is %f' %score(SVC())
- print 'LinearSVC`s accuracy is %f' %score(LinearSVC())
- print 'NuSVC`s accuracy is %f' %score(NuSVC())
結(jié)果如下(很長。。):
- Feature number 500
- BernoulliNB`s accuracy is 0.880000
- MultinomiaNB`s accuracy is 0.850000
- LogisticRegression`s accuracy is 0.740000
- SVC`s accuracy is 0.840000
- LinearSVC`s accuracy is 0.700000
- NuSVC`s accuracy is 0.810000
- Feature number 1000
- BernoulliNB`s accuracy is 0.860000
- MultinomiaNB`s accuracy is 0.850000
- LogisticRegression`s accuracy is 0.750000
- SVC`s accuracy is 0.800000
- LinearSVC`s accuracy is 0.720000
- NuSVC`s accuracy is 0.760000
- Feature number 1500
- BernoulliNB`s accuracy is 0.870000
- MultinomiaNB`s accuracy is 0.860000
- LogisticRegression`s accuracy is 0.770000
- SVC`s accuracy is 0.770000
- LinearSVC`s accuracy is 0.750000
- NuSVC`s accuracy is 0.790000
- Feature number 2000
- BernoulliNB`s accuracy is 0.870000
- MultinomiaNB`s accuracy is 0.850000
- LogisticRegression`s accuracy is 0.770000
- SVC`s accuracy is 0.690000
- LinearSVC`s accuracy is 0.700000
- NuSVC`s accuracy is 0.800000
- Feature number 2500
- BernoulliNB`s accuracy is 0.850000
- MultinomiaNB`s accuracy is 0.830000
- LogisticRegression`s accuracy is 0.780000
- SVC`s accuracy is 0.700000
- LinearSVC`s accuracy is 0.730000
- NuSVC`s accuracy is 0.800000
- Feature number 3000
- BernoulliNB`s accuracy is 0.850000
- MultinomiaNB`s accuracy is 0.830000
- LogisticRegression`s accuracy is 0.780000
- SVC`s accuracy is 0.690000
- LinearSVC`s accuracy is 0.710000
- NuSVC`s accuracy is 0.800000
把上面的所有測試結(jié)果進(jìn)行綜合可匯總?cè)缦拢?/p>
不同分類器的不同特征選擇方法效果
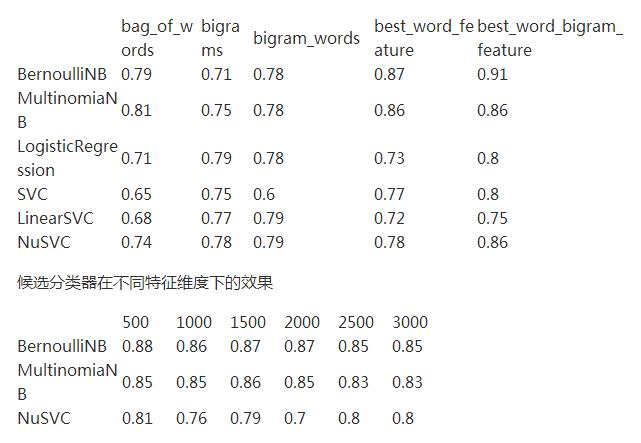
綜合來看,可以看出特征維數(shù)在500 或 1500的時候,分類器的效果是***的。
所以在經(jīng)過上面一系列的分析之后,可以得出如下的結(jié)論:
- Bernoulli 樸素貝葉斯分類器效果***
- 詞和雙詞搭配作為特征時效果***
- 當(dāng)特征維數(shù)為1500時效果***
為了不用每次分類之前都要訓(xùn)練一次數(shù)據(jù),所以可以在用開發(fā)集找出***分類器后,把***分類器存儲下來以便以后使用。然后再使用這個分類器對文本進(jìn)行分類。
一、使用測試集測試分類器的最終效果
- word_scores = create_word_bigram_scores() #使用詞和雙詞搭配作為特征
- best_words = find_best_words(word_scores, 1500) #特征維度1500
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
- trainSet = posFeatures[:500] + negFeatures[:500] #使用了更多數(shù)據(jù)
- testSet = posFeatures[500:] + negFeatures[500:]
- test, tag_test = zip(*testSet)
- def final_score(classifier):
- classifier = SklearnClassifier(classifier)
- classifier.train(trainSet)
- pred = classifier.batch_classify(test)
- return accuracy_score(tag_test, pred)
- print final_score(BernoulliNB()) #使用開發(fā)集中得出的***分類器
其結(jié)果是很給力的:
- 0.979166666667
二、把分類器存儲下來
(存儲分類器和前面沒有區(qū)別,只是使用了更多的訓(xùn)練數(shù)據(jù)以便分類器更為準(zhǔn)確)
- word_scores = create_word_bigram_scores()
- best_words = find_best_words(word_scores, 1500)
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
- trainSet = posFeatures + negFeatures
- BernoulliNB_classifier = SklearnClassifier(BernoulliNB())
- BernoulliNB_classifier.train(trainSet)
- pickle.dump(BernoulliNB_classifier, open('D:/code/sentiment_test/classifier.pkl','w'))
在存儲了分類器之后,就可以使用該分類器來進(jìn)行分類了。
三、使用分類器進(jìn)行分類,并給出概率值
給出概率值的意思是用分類器判斷一條評論文本的積極概率和消極概率。給出類別也是可以的,也就是可以直接用分類器判斷一條評論文本是積極的還是消極的,但概率可以提供更多的參考信息,對以后判斷評論的效用也是比單純給出類別更有幫助。
1. 把文本變?yōu)樘卣鞅硎镜男问?/strong>
要對文本進(jìn)行分類,首先要把文本變成特征表示的形式。而且要選擇和分類器一樣的特征提取方法。
- #! /usr/bin/env python2.7
- #coding=utf-8
- moto = pickle.load(open('D:/code/review_set/senti_review_pkl/moto_senti_seg.pkl','r')) #載入文本數(shù)據(jù)
- def extract_features(data):
- feat = []
- for i in data:
- feat.append(best_word_features(i))
- return feat
- moto_features = extract_features(moto) #把文本轉(zhuǎn)化為特征表示的形式
注:載入的文本數(shù)據(jù)已經(jīng)經(jīng)過分詞和去停用詞處理。
2. 對文本進(jìn)行分類,給出概率值
- import pickle
- import sklearn
- clf = pickle.load(open('D:/code/sentiment_test/classifier.pkl')) #載入分類器
- pred = clf.batch_prob_classify(moto_features) #該方法是計算分類概率值的
- p_file = open('D:/code/sentiment_test/score/Motorala/moto_ml_socre.txt','w') #把結(jié)果寫入文檔
- for i in pred:
- p_file.write(str(i.prob('pos')) + ' ' + str(i.prob('neg')) + '\n')
- p_file.close()
***分類結(jié)果如下圖:
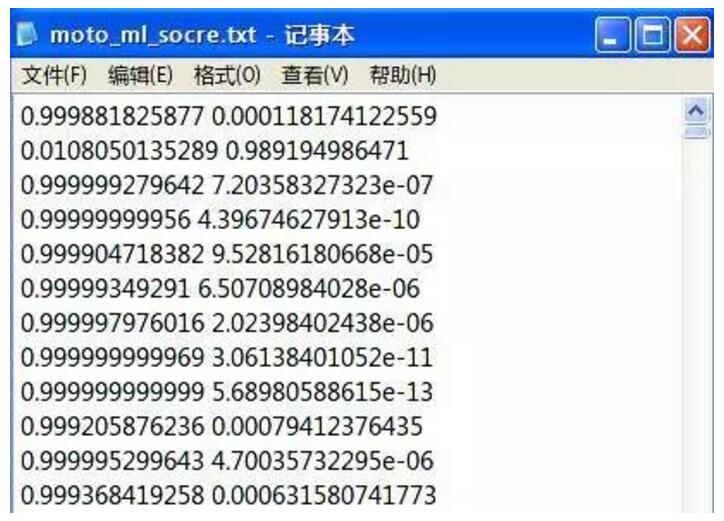
前面是積極概率,后面是消極概率
折騰了這么久就為了搞這么一個文件出來。。。這傷不起的節(jié)奏已經(jīng)無人阻擋了嗎。。。
不過這個結(jié)果確實比詞典匹配準(zhǔn)確很多,也算欣慰了。。。