













Kyligence:新零售時代,數據分析怎么玩?
近日,Kyligence參加了微軟加速器上海聯合普華永道加速器舉辦的零售及消費品行業客戶對接會,Kyligence 解決方案架構師海書山受邀參加大會,并發表題為《大數據分析:賦能創新零售戰略》的演講。

在他的演講中,不僅對大數據時代零售企業普遍面臨的數字化轉型挑戰拋出了自己的觀點,也通過案例分享,對Kyligence的大數據分析解決方案Kyligence Analytics Platform如何解決這一困境做了分享。以下是現場演講實錄:
大家好,首先感謝PwC和微軟的這次活動,先自我介紹一下,我叫海書山,是Kyligence的解決方案架構師,從個人層面來說我有一些零售行業架構、實施和咨詢的經驗,從公司的角度我們主要是通過大數據技術來幫助企業在不同的職能層面來提升數據洞察力和分析效率,所以我的主題是《大數據分析:賦能創新零售戰略》。
從我之前的項目經驗,和現在作為數據廠商跟不同的客戶溝通中,發現我們零售行業因為數據問題有很多痛點,比如因為渠道不同而造成消費者體驗的一個割裂,這也導致了消費者的忠誠度、成交率和轉化率比較低。另外就是因為很多零售企業數字化轉型程度還不是很高,所以就會有很多數據碎片,數據口徑不一致等問題。也因此帶來了管理成本很高,企業的數字化決策困難等等。
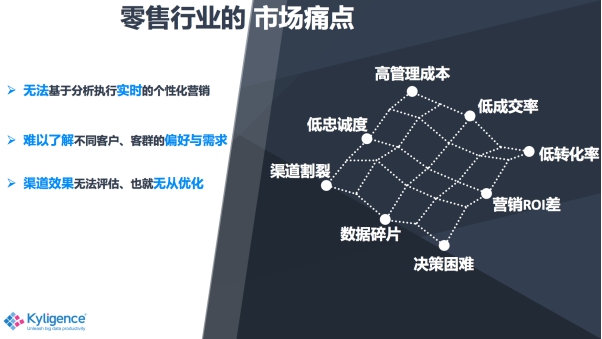
那這些問題在大數據時代怎么去解決呢?
現在很多零售企業都在做轉型,比如從IT到DT的一個轉型,我們來看一下大數據能帶來什么。首先大數據能讓我們對客戶有更好的洞察力,比如將不同渠道、來源的客戶進行統一整合和識別,這也給實時個性化推薦或者精準營銷等等提供了基礎。然后我們可以針對進銷存、物流效率等等做一些供需鏈的優化和相應的風險管控。***呢我們可以把這些關于客戶和運營的應用和場景,以大數據分析和可視化的形式呈現出來,并且給我們做一些決策上的支持。那這些就是我們叫做大數據零售的核心能力,也就是通過大數據分析的手段給零售行業的賦能。
為了達到或者實現這些應用,我們在技術上需要做到什么?
首先我們面臨的肯定是海量數據,不管是數據量還是數據的復雜程度都比傳統的數據應用提升了一個等級;同時不管是實時分析,還是交互式分析,都對數據的實時性要求更高,也就是我們要低延遲;接著在海量數據和低延遲的基礎之上,我們還要求并發性,因為我們面臨的可能是一線運營人員,甚至說終端消費者,并發量從幾十上百,到成千上萬,所以高并發是很重要的,甚至是必須的。***我們還希望資源可以彈性伸縮,因為數據量可能有波峰波谷,并發水平也有高有低,所以計算和存儲資源***能隨時的scale in/scale out。
這些是我們想要大數據能達到的技術要求,那現在的大數據分析平臺是不是能做到呢?
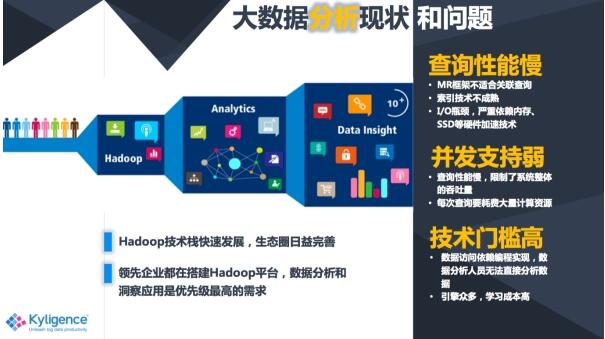
首先說到大數據,離不開的話題肯定是Hadoop,Hadoop已經基本成為大數據領域的標配,它的生態系統也比較完善,大家都在各自的Hadoop平臺上面去實現數據分析和洞察的一些應用。但與此同時呢,其實我們發現了一些問題,比如說查詢性能比較慢,對并發支持也很弱等等一些Haddop的技術特性所決定的弱點,另外呢就是因為技術門檻高,所以大數據的人才比較難找。
正是因為看到了大數據分析平臺的這些問題,所以我們Kyligence提出有針對性的解決方案,其實就是在數據中心和數據應用之間搭建了一個橋梁,或者說數據加速層,我們融合了現在比較流行的ABC技術,那A就是用AI分析引擎,去智能化的完成數據準備和查詢優化,降低使用門檻;B就是我們的Big Data,實現數據應用的高并發和加速,甚至可以支持實時分析;C就是Cloud,云,那我們同時支持本地和云端部署,實現統一的數據訪問入口。這就是我們叫Kyligence Analytics Platform,或者我們的大數據分析解決方案。
那這套解決方案的應用場景到底有哪些呢?
其實有很多,比如說我們最常用到的多維分析報表,還有在預定義指標和維度的基礎上實現靈活分析,或者說自助分析;另外比如說用戶畫像應用,還有將數據和平臺以云計算的方式提供服務(DaaS),這些都是我們已經實現的應用場景。

我們來看一個客戶案例,這是我們幫某全球跨國連鎖餐廳的市場部門做的一個大數據分析平臺的case,他們在數字營銷的過程中呢,確實遇到了一些問題,比如數據口徑不一致、分析周期太長、不能探索式的數據分析等等,相對來說制約了市場部門的活動和營銷效率。那我們的方案呢,是在他們現有的數據平臺上,搭建統一的大數據分析平臺,并且能直接給到市場部門的運營人員去自助地分析,極大的降低了分析的門檻。從商業的角度來說,提高了活動效率和ROI,也給一些市場決策提供了更好的分析支持,這也就是我們說大數據分析給數字營銷帶來的價值。
那介紹了完場景和案例,我們的核心技術到底是什么?
Apache Kylin!做技術或者數據圈的應該都知道Apache基金會在大數據領域的影響力,比如Hadoop、Spark其實都是在Apache下面開源的。Kylin是我們***個Apache的***開源項目,作為有獨立知識產權的***項目,我們也非常自豪,主要解決的就是前面一直說的大數據分析問題,也就是在海量數據下實現高并發和亞秒級響應。那現在在全球已經有超過1000家公司在用Kylin作為數據分析的解決方案,這也證明了我們技術的先進性。

那說到我們公司呢,Kyligence,這下就很好理解,是Kylin+Intelligence的合寫,其實就是用Kylin實現數據上的智能,我們也是Apache Kylin的原創團隊組建的,在商業上首先我們有Kylin的企業級產品KAP,和相關的一些基于Cloud的產品生態圈,另外我們的團隊會提供基于大數據或者行業的解決方案,包括平臺實施,架構咨詢等等一些專業的服務。
除了剛才說的案例,我們在各個行業都有一些典型案例,特別是金融、保險、互聯網等等在大數據方面走在前面的行業,比如說國泰君安的客戶洞察和營銷分析,OPPO的手機日志分析平臺等等,也確實在不同的客戶和場景下都驗證了我們的技術和解決方案的優勢。
我的分享就到這,希望有機會跟在座的各位做一些深入的溝通,謝謝!
關于Kyligence
Kyligence 由***來自中國的 Apache 軟件基金會***開源項目 Apache Kylin 核心團隊組建,是專注于大數據分析領域創新的數據科技公司。Kyligence 提供基于 Apache Kylin 的企業級大數據智能分析產品 Kyligence Enterprise,以及基于公有云的托管式 Kylin 在線服務 Kyligence Cloud。目前,Kyligence 已贏得了海內外多家金融、保險、證券、電信、制造、零售、廣告等企業級客戶。












