人工智能生成微笑悲傷憤怒驚奇等離散面部屬性利用生成對抗網絡簡介:我們的數字時代見證了對靈活,高質量肖像操作的需求飆升,不僅來自智能手機應用,還來自攝影行業,電子商務推廣,電影制作等。人像設備也得到了廣泛的研究[34] ,5,8,18,1,33]在計算機視覺和計算機圖形學術界。以前的方法專門用于添加化妝[23,6],執行風格轉移[9,14,24,12],年齡進展[42]和表達操作[1,39]等等。然而,這些方法是針對特定任務而定制的,并且不能被傳輸以執行連續和一般的多模態肖像操作。
最近,生成對抗網絡在合成和圖像翻譯中已經證明了引人注目的效果[15,38,4,35,44,13],其中[44,40]提出了不成對圖像翻譯的循環一致性。在本文中,我們通過利用額外的面部地標信息將這個想法擴展到條件設置,這些信息能夠捕獲復雜的表達變化。通過這種簡單而直接的修改產生的好處包括:首先,循環映射可以有效地防止多對一映射[44,45],也稱為模式崩潰。在面部/姿勢操縱的情況下,周期一致性也引起身份保持和雙向操縱,而先前的方法[1]假設中性面開始或單向[26,29],因此在同一域中操縱。其次,不同紋理或樣式的面部圖像被認為是不同的模態,當前的地標檢測器不適用于那些程式化的圖像。通過我們的設計,我們可以對來自多個域的樣本進行配對,并在每對域之間進行轉換,從而可以間接地在風格化的肖像上進行地標提取。一旦收集了相應的數據,我們的框架也可以擴展到化妝/卸妝,老化操作等。考慮到許多面部操作任務缺乏groundtruth數據,我們利用[14]的結果生成偽目標以學習同時表達和模態操作,但它可以被任何所需的目標域替換。
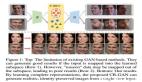
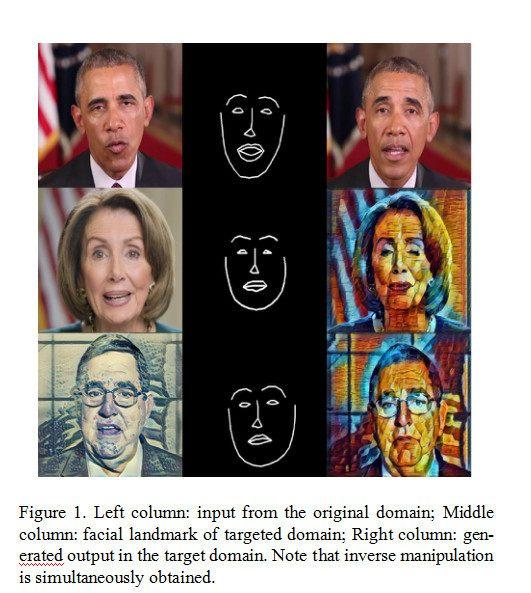
人工智能生成微笑悲傷憤怒驚奇等離散面部屬性利用生成對抗網絡貢獻:然而,實現高質量的肖像操作仍然存在兩個主要挑戰。我們建議學習單個發生器tt,如[7]。但StarGAN [7]處理離散操作,并且在具有不可移除偽像的高分辨率圖像上失敗。為了合成照片般逼真的質量圖像(512x512),我們提出了受[37,41]啟發的多層次平面監督,其中不同分辨率的合成圖像在被饋送到多級鑒別器之前被傳播和組合。其次,為了避免在不同域之間的平移過程中紋理不一致和偽影,我們將Gram矩陣[9]作為紋理距離的度量集成到我們的模型中,因為它是不同的,并且可以使用反向傳播進行端到端的訓練。圖1顯示了我們模型的結果。
廣泛的評估在數量和質量上都表明,我們的方法在執行高質量的肖像操作方面與***進的生成模型相當或更優(參見第4.2節)。我們的模型是雙向的,它避免了從中性面或固定域開始的需要。此功能還可確保穩定的培訓,身份保護,并可輕松擴展到其他所需的域操作。在下一節中,我們將審查相關的工作,并指出差異。有關PortraitGAN的詳細信息,請參見第3節。我們在第4節中評估了我們的方法,并在第5節中總結了論文。
人工智能生成微笑悲傷憤怒驚奇等離散面部屬性利用生成對抗網絡圖像翻譯:我們的工作可以分為圖像翻譯和生成對抗網絡,其目的是學習映射tt:誘導與目標域無法區分的分布,通過對抗訓練一對發電機tt和鑒別器。例如,Isola等人。 [13]將圖像作為在配對樣本上訓練的一般圖像到圖像翻譯的條件。后來,Zhu et.al [44]通過引入循環一致性損失來擴展[13],以避免匹配訓練對的需要。此外,它還減輕了訓練生成對抗網絡(也稱為模式崩潰)期間的多對一映射。受此啟發,我們將這種損失整合到我們的模型中,以便在不同領域之間保持身份。
啟發我們設計的另一項開創性工作是Star-GAN [7],其中目標面部屬性被編碼為單熱矢量。在StarGAN中,每個屬性都被視為一個不同的域,用于區分這些屬性的輔助分類對于監督培訓過程至關重要。與StarGAN不同,我們的目標是在像素空間中執行無法使用離散標簽枚舉的連續編輯。這隱含地暗示了平滑且連續的潛在空間,其中該空間中的每個點編碼數據中有意義的變化軸。我們將不同的樣式形式視為本文中的域,并可互換地使用兩個單詞。從這個意義上講,美化/去美化,衰老/年輕,胡須/無胡須等應用也可以納入我們的一般框架。我們將第4節中針對Cycle-GAN [44]和StarGAN [7]的方法進行了比較,并在第3節中詳細說明了我們的設計。
姿勢圖像生成:我們知道在人物圖像生成的人重新識別任務中使用姿勢作為條件的作品[36,20,31,29]。例如[26]以通道方式連接單熱姿勢特征圖來控制類似于[30]的姿勢生成,其中鳥類的關鍵點和分割掩模用于處理鳥類的位置和姿勢。為了合成更合理的人體姿勢,Siarohin et.al [31]開發了可變形的跳躍連接,并計算了一組仿射變換來逼近關節變形。這些作品與我們的作品有一些相似之處,因為面部地標和人體骨骼都可以被視為一種姿勢表現形式。但是,所有這些工作都涉及原始域中的操作,并且不保留身份。此外,這些工作中生成的結果是低分辨率,而我們的模型可以成功生成具有照片般逼真質量的512x512分辨率。

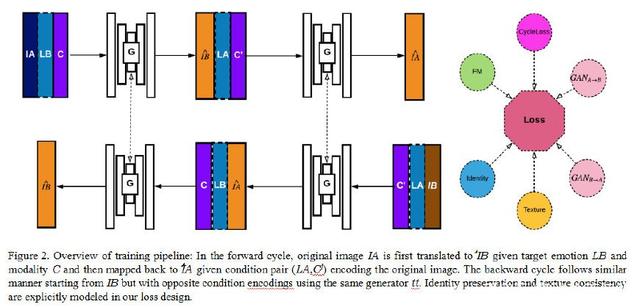
人工智能生成微笑悲傷憤怒驚奇等離散面部屬性利用生成對抗網絡整體框架:問題公式給定不同模態的域1,2,3,... n,我們的目標是學習單個通用映射函數tt:Xi→Xj,∀i,j∈{1,2,3,... n}(1)通過連續的形狀編輯將A中的A從域A轉換為B(圖1)。等式1還暗示tt在給定期望條件下是雙向的。我們使用面部界標j R1×H×W來表示域j中的面部表情。面部表情被表示為具有N = 68的2D關鍵點的矢量,其中每個點ui =(xi,yi)是j中的第i個像素位置。我們使用屬性向量c = [c1,c2,c3,... cn]來表示目標域。形式上,我們的輸入/輸出是形式(IA,LB,cB)/(IB,LA,cA)∈R(3 + 1 + n)×H×W的元組。模型體系結構我們的方法的總體流程很簡單,如圖2所示,由三個主要部分組成:(1)生成器tt(,c),其將域c1中的輸入面呈現給給定條件面部標記的另一域c2中的同一人。 tt是雙向的,并在前進和后退循環中重復使用。(2)一組不同分辨率的鑒別器Di,用于區分生成的樣本和實際的樣本。 我們采用PatchGAN [44]而不是將I映射到表示“真實”或“假”的單個標量,而PatchGAN [44]使用完全的convnet輸出矩陣,其中每個元素Mi,j表示重疊補丁ij為真實的概率。 如果我們追溯到原始圖像,每個輸出都有一個70 70的感受野。 (3)考慮到身份保存和紋理的損失函數不同域之間的一致性。 在以下小節中,我們將單獨詳細說明每個模塊,然后將它們組合在一起構建PortraitGAN。
人工智能生成微笑悲傷憤怒驚奇等離散面部屬性利用生成對抗網絡數據集訓練和驗證:Radboud Faces數據庫[19]包含4,824個圖像,共有67個參與者,每個圖像執行8個規范的情感表達:憤怒,厭惡,恐懼,快樂,悲傷,驚訝,蔑視和中立。 iCV多情感面部表情數據集[25]專為微情感識別(5184x3456分辨率)而設計,其中包括31,250種表情,表現出50種不同的情緒。 測試:我們從Youtube(縮寫為HRY Dataset)收集20個高分辨率視頻,其中包含提供語音或地址進行測試的人員。 對于上述數據集,我們使用dlib [17]進行面部標志性提取,并使用神經樣式傳遞算法[14]來生成多種模態的肖像。 請注意,在測試期間,groundtruths僅用于評估目的。