幾款優(yōu)秀的分布式關(guān)系數(shù)據(jù)庫
譯文【51CTO.com快譯】關(guān)系SQL數(shù)據(jù)庫自上世紀(jì)80年代以來就有了,以前運行在大型機或單一服務(wù)器上。如果想讓數(shù)據(jù)庫處理更多數(shù)據(jù)、運行得更快,只好將數(shù)據(jù)庫放在配備更多更快的CPU、內(nèi)存和磁盤的更龐大服務(wù)器上。換句話說,你求助于縱向擴展性即“向上擴展”。以后,如果你需要能夠故障切換以改善可用性,可以將熱備用服務(wù)器與活動服務(wù)器放在同一個“主動-被動”集群中,通常采用共享存儲。
需要ACID的四個屬性:原子性、一致性、隔離性和持久性,才能確保數(shù)據(jù)庫事務(wù)始終有效,即使出現(xiàn)網(wǎng)絡(luò)分區(qū)、電源故障及其他錯誤。單一服務(wù)器上的數(shù)據(jù)庫遵循ACID的全部四個屬性比較容易,但針對分布式數(shù)據(jù)庫實施這些屬性要難一點。
最近市面上出現(xiàn)了幾種“橫向擴展”的SQL數(shù)據(jù)庫。更棒的是,其中一些數(shù)據(jù)庫可以處理地理位置分散的服務(wù)器,而不犧牲一致性。由于光速帶來的限制,邊遠(yuǎn)的服務(wù)器節(jié)點比本地節(jié)點需要更長的時間來更新,但幾種技術(shù)可以緩解這個問題,包括使用共識組quora和超高速網(wǎng)絡(luò)及存儲。
通常,你一直使用的數(shù)據(jù)庫和想要使用的新分布式數(shù)據(jù)庫應(yīng)盡可能兼容,盡量降低模式和應(yīng)用程序轉(zhuǎn)換成本。簡單的情況是,你可以遷移模式和數(shù)據(jù),然后只需更改應(yīng)用程序中的連接字符串。復(fù)雜的情況是,你需要完成數(shù)據(jù)轉(zhuǎn)換過程,全面重寫存儲過程和觸發(fā)器,大范圍重寫應(yīng)用程序的數(shù)據(jù)層,包括SQL查詢。
Amazon RDS和Amazon Aurora
Amazon RDS(關(guān)系數(shù)據(jù)庫服務(wù))這種Web服務(wù)讓用戶更容易在云端安裝、操作和擴展關(guān)系數(shù)據(jù)庫。Amazon RDS支持MySQL、MariaDB、PostgreSQL、Oracle Database和微軟SQL Server。
可以使用面向故障切換的同步輔助實例來配置Amazon RDS數(shù)據(jù)庫,以實現(xiàn)高可用性。遺憾的是,你無法從備用輔助實例中讀取。可以使用MySQL、MariaDB或PostgreSQL Read Replicas來加強讀取擴展,但復(fù)制是異步的,因此副本的狀態(tài)可能落后于主實例的狀態(tài)。
Amazon Aurora是Amazon RDS中的一項服務(wù),可在快速分布式存儲上提供高性能的MySQL和PostgreSQL數(shù)據(jù)庫集群。你可以在數(shù)據(jù)庫集群中最多創(chuàng)建15個Aurora Replicas以支持只讀查詢,可以在多個可用區(qū)(AZ)中創(chuàng)建副本,以實現(xiàn)全局分布。
據(jù)亞馬遜聲稱,Aurora可以提供最多五倍于MySQL的吞吐量,最多三倍于PostgreSQL的吞吐量,無需更改大多數(shù)現(xiàn)有應(yīng)用程序。亞馬遜還聲稱更新Aurora讀取副本的延遲時間約20毫秒,這比MySQL讀取副本快得多。
Azure SQL Database
Azure SQL Database是一種全面托管的關(guān)系云數(shù)據(jù)庫服務(wù),提供廣泛的SQL Server引擎兼容性,讓你可以動態(tài)增減數(shù)據(jù)庫資源。Azure SQL Database包括創(chuàng)建活動地理副本的選項,這些地理副本是地理位置分散的輔助數(shù)據(jù)庫。
在相同或不同的區(qū)域支持最多四個輔助數(shù)據(jù)庫,輔助數(shù)據(jù)庫還可用于只讀查詢。如果你需要將主數(shù)據(jù)庫故障切換到其中一個輔助數(shù)據(jù)庫,可以手動或通過API執(zhí)行此操作。
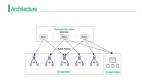
ClustrixDB
ClustrixDB現(xiàn)歸MariaDB所有,這個橫向擴展的集群關(guān)系HTAP(混合事務(wù)/分析處理)數(shù)據(jù)庫采用無共享架構(gòu)設(shè)計。ClustrixDB主要與MySQL和MariaDB兼容。我測評ClustrixDB時,該產(chǎn)品不支持空間擴展類型和全文搜索;上一個版本仍缺乏這兩項功能。
為ClustrixDB添加節(jié)點可以擴展讀寫。ClustrixDB允許集群跨多個區(qū)域部署,以便在非計劃區(qū)域故障期間提供容錯功能。在獨立實驗室(但不是《InfoWorld》)運行的測試)中,ClustrixDB能夠以15毫秒的延遲每秒處理4萬個事務(wù),其負(fù)載是90%的讀取和10%的寫入,為其提供了適用于電子商務(wù)的“網(wǎng)絡(luò)星期一”可擴展性。
CockroachDB
CockroachDB是一種可橫向擴展、與PostgreSQL兼容的開源分布式SQL數(shù)據(jù)庫,由熟悉Google Cloud Spanner的前谷歌員工開發(fā)。CockroachDB借鑒了Spanner的數(shù)據(jù)存儲系統(tǒng)設(shè)計,并使用Raft算法在其節(jié)點之間達(dá)成共識。CockroachDB不需要GPS和同步Spanner的原子鐘。
CockroachDB立足于事務(wù)性一致性的鍵值存儲系統(tǒng)RocksDB上。CockroachDB背后的主要設(shè)計目標(biāo)是支持ACID事務(wù)、橫向擴展性和(最重要的)生存性,因此得名。CockroachDB默認(rèn)使用可序列化隔離模式,這勝過其他大多數(shù)數(shù)據(jù)庫實施的隔離機制。
我在2018年初測試CockroachDB時,其JOIN性能不是很好。從那以后,這點已得到解決。CockroachDB支持將集群分散在多個可用區(qū)上,還在谷歌云平臺和AWS上提供全面托管的云數(shù)據(jù)庫集群。
Google Cloud Spanner
Google Cloud Spanner是一種托管分布式數(shù)據(jù)庫,擁有NoSQL數(shù)據(jù)庫的可擴展性,同時保留了SQL兼容性、關(guān)系模式、ACID事務(wù)和外部一致性。Spanner看起來像是顛覆了CAP定理。
Spanner是分片、全局分布、復(fù)制的,使用Paxos算法在節(jié)點之間達(dá)成共識。Spanner使用分兩個階段的提交以確保強一致性,但將Paxos組視為事務(wù)的成員。每個Paxos組只需要額定數(shù)(quorum),而不是需要100%的成員。
在谷歌內(nèi)部使用時,Spanner的可用性超過五個9,即高于99.999%,這意味著每年停機時間不到5分鐘。這足以讓大多數(shù)程序員通常不必為編寫代碼來處理Spanner可用性故障而操心。
Spanner使用Google Common SQL,這是ANSI 2011 SQL的一種方言。Common SQL與PostgreSQL、MySQL、SQL Server或Oracle Database使用的任何SQL方言都不完全相同,數(shù)據(jù)類型略有不同,數(shù)據(jù)操縱方面大不相同。
原文標(biāo)題:The best distributed relational databases,作者:Martin Heller
【51CTO譯稿,合作站點轉(zhuǎn)載請注明原文譯者和出處為51CTO.com】