如何用New Relic進行性能與壓力測試
譯文【51CTO.com快譯】在任何現代化軟件組織的日常工作中,性能工程(Performance engineering)和壓力測試(load testing)都是非常關鍵的組成部分。實際上,許多公司都會在此類團隊的建設上日益增加投入。而那些缺乏此類流程的公司,也正在朝著該方向迅速改進中。
從理論上說:在關鍵性能指標(KPI,請參見:https://kpi.org/KPI-Basics)的驅動下,軟件應用領域的性能工程和壓力測試具有如下三個主要目標:
1. 驗證應用程序的當前負載容量。
2. 識別應用代碼、軟件配置、以及硬件資源上的瓶頸限制。
3. 提高應用程序的可伸縮性,以滿足目標負載能力。
具體來說,典型的壓力測試會涉及如下六個方面:
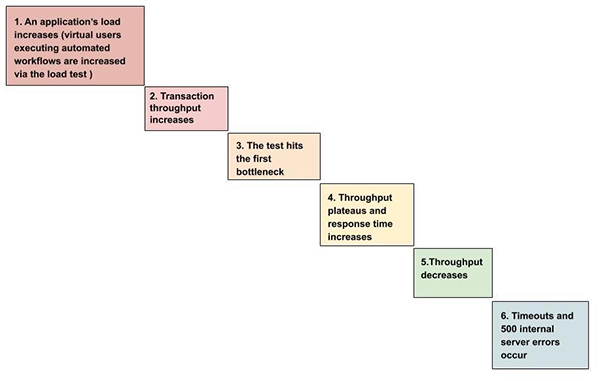
目前,雖然業界有著大量的相關測試工具,它們可以通過生成并非用戶的訪問負載,來進行性能測試,但是New Relic平臺,特別是New Relic APM(https://newrelic.com/products/application-monitoring)、New Relic Infrastructure(https://newrelic.com/products/infrastructure)和New Relic Browser(https://newrelic.com/products/browser-monitoring)都提供了較為深入的監控與服務,以及各種關鍵性的洞見。New Relic能夠分析瀏覽器的響應時間、用戶的會話數、應用程序的運行速度、以及后端資源的利用率。根據New Relic所創建的壓力測試環境,測試團隊能夠獲悉有關應用性能的端到端“全景視圖”。
本文將分為3部分、12個步驟,向您介紹在性能工程中,如何使用New Relic開展有序的壓力測試,并進行規范性的根本原因分析。
第1部分:設置基線并確定當前容量?
我們的首要任務就是先構造壓力測試,然后緩慢增加負載,直至應用程序出現瓶頸。
1.我們從最小用戶數的負載開始(例如:5個用戶的并發量),執行至少持續一小時的壓力測試。我們將這種低負載測試的結果作為一個基線。
如果針對基線壓力測試的結果,已經能夠出現并發的事務超出了服務級別協議(SLA),那么我們就沒有理由再進行下一步的可伸縮性測試了。而如果一切正常,我們則繼續下一步。
2.通過基線壓力測試的結果,您可以為應用設置可接受的Apdex分數(https://docs.newrelic.com/docs/apm/new-relic-apm/apdex/apdex-measure-user-satisfaction)。該Apdex是目標應用程序平均響應時間的標準。您需要為那些在執行時間上超過整體SLA的特定事務,創建關鍵事務(https://docs.newrelic.com/docs/apm/transactions/key-transactions/introduction-key-transactions)。例如,對于典型的Web應用而言,其Browser Apdex值應當為0.3秒。而Java應用程序的APM Apdex值則可能為0.5秒。如果您的應用程序有一個微服務集合,并通過API來處理事務,那么每個服務的Apdex則可能是0.2秒。因此,我們的宗旨是為每個執行事務的服務,設置適當的Adex值。
3.設計并執行壓力測試,然后有條不紊地增加用戶數量。請為每一個應用程序設計不同的吞吐量和用戶負載目標。例如,您可以使用5個并發用戶數來觸發壓力測試,接著每隔15秒鐘再添加5個用戶。隨著用戶數量的增加,壓力測試將慢慢接近性能的臨界點,這將使您能夠了解到目標應用程序所能夠處理負載的極限。
記住:壓力測試應當被設計為有序進行,而不要一股腦地將目標工作負載拋給應用程序,否則得到的結果不但混亂、且難以解釋。例如:如果您的目標是達到5,000個并發用戶,那么您設計的壓力測試應當先錨定該目標的一半。如果此應用能夠成功地擴展到目標負載的一半,那么您才可以繼續設計下一輪測試,以使負載加倍。同樣,如果您測試的是負載吞吐量,而不是用戶數與活動會話,那么您仍然可以使用相同的方法穩健地達到目標所設定的每秒事務數。例如,如果您的API吞吐量目標為每秒200個事務的話,那么您可以逐步將測試的壓力擴展到每秒100個事務。
4.在應用程序的APM概覽頁面中,您可以通過更改視圖,來查看“Web事務分位數(Web transactions percentiles)”。由于其中95%的記錄都會比中位或平均值更加敏銳與精細,因此您可以將主要精力集中在這95%的記錄行上。
通過觀察,您可以找到目標應用在壓力測試下開始出現服務質量下降的時間點,然后突出顯示并放大該時間范圍與跨度,以便您能夠執行更為深入的分析。例如,您可以深入挖掘各種事務性、分布式的軌跡、以及相關的錯誤,或是從APM模式切換到Browser模式,以便從前端轉為后端分析。New Relic能夠持續地自動聚焦該時間范圍內的各類信息。
記住:該測試部分的主要目標是首次識別瓶頸,因此您不需擔心在首次拐點之后的圖表走勢。任何跨過該點的狀態,都只是某個根本原因的后續癥狀而已。
第2部分:隔離首個瓶頸
針對上述發現的性能下降情況,您可以根據應用的實際情況,執行如下步驟5到9(可以不一定按照該順序)以進行問題排查。例如,您可以從使用New Relic Browser去分析響應的時間開始,順藤摸瓜,直到發現APM中的代碼缺陷(也就是所謂的自上而下的方法)。當然,您也可以從New Relic Infrastructure開始,以識別那些導致瀏覽器響應耗時的資源限制(也就是所謂的自下而上的方法)。
5.利用在步驟4中所收集的信息,采用服務映射(service maps,https://docs.newrelic.com/docs/understand-dependencies/understand-system-dependencies/service-maps/introduction-service-maps)來識別到底是哪個應用事務的哪些內、外部服務水平出現了下降,并導致了總體響應時間的增加。
如果您發現有多個事務存在著服務水平的下降趨勢,那么這通常表明有某些資源已經接近到了它們的飽和點。
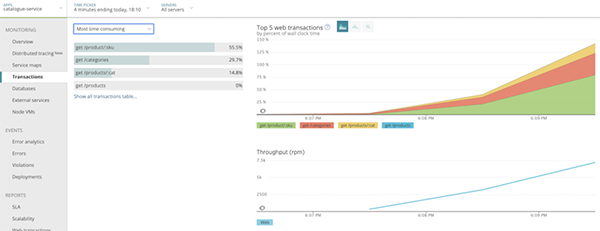
事務分析
6.使用New Relic APM來逐步隔離各種代碼的缺陷、或是錯誤的條件。使用事務跟蹤(transaction traces,https://docs.newrelic.com/docs/apm/transactions/transaction-traces/introduction-transaction-traces)的方法,來隔離服務降級、或是拋出錯誤的確切代碼。
7.使用Infrastructure的主機集成(on-host integrations,https://docs.newrelic.com/docs/integrations/host-integrations/getting-started/introduction-host-integrations),來識別基礎架構中諸如Web服務器、JVM或數據庫等方面的限制。
8.使用Infrastructure來檢查應用部署所涉及到的每一臺主機和服務器,以查看是否有硬件資源(CPU、內存、以及網絡等)被濫用的情況。
硬件資源不一定是在完全飽和時,才能導致響應時間的延長。有時候,達到70%的飽和度時,其性能就會受到影響。如果您在壓力測試中發現瓶頸并非源自硬件資源,那么就請檢查服務器的軟件資源,其中包括:連接池、數據源連接數、及其TCP堆棧等方面。因為當軟件資源飽和時,它們同樣會在基礎架構中出現“排隊”的狀況。
9.使用Browser來確定響應時間的增加是否來自應用的前端。例如,當您的站點需要呈現某些HTML類資產時,那些向第三方遠程服務器發送的Ajax請求數,就有可能會導致整體速度的下降。
第3部分:優化以緩解瓶頸問題
在確定了瓶頸的原因之后,您需要通過實施變更,來應對新的壓力測試。
10.對于應用程序的任何變更,您都需要設置New Relic的部署標記(deployment marker,https://docs.newrelic.com/docs/apm/new-relic-apm/maintenance/record-deployments)來予以記錄。您可以使用諸如:“向VM增加了2顆CPU”之類詳細信息,來標記針對某次變更的部署。
記住:一次僅修改一個變量。如果您一次性地修改了兩個、或更多的內容(例如,增加了多個硬件資源、并讓JVM堆棧的大小翻倍了),那么您將無從知曉到底是哪個變量,如何影響了應用程序的總體負載性能。
11.重新運行壓力測試并分析新的結果,以判斷性能是否有所改觀。如果沒有任何差異的話,那就意味著您并未找到真正的瓶頸。請保留或還原先前的變更,并按需重復前面的測試步驟。
12.持續進行壓力測試,直至真正消除了瓶頸,并滿足了既定的各項負載需求。
使性能工程成為一個迭代的過程
客觀地說,壓力測試和性能工程是“永無止境”的。由于從應用程序的工作負載、到功能服務、再到體系架構中的幾乎每個組件,我們都需要對它們進行持續的開發與部署,因此就算是某個新增的簡單變更,也可能會對前期的性能測試結果帶來干擾。所以說,性能測試應當隨著應用程序的迭代而繼續。
其他的壓力測試和性能分析資源
下面是一些您可能在壓力測試和性能分析中用得上的,其他類型的New Relic工具:
- 服務映射(https://docs.newrelic.com/docs/understand-dependencies/understand-system-dependencies/service-maps/introduction-service-maps):在應用程序的部署過程中,可用于識別服務之間的連接、以及上/下游的依賴關系。
- 分布式跟蹤(https://docs.newrelic.com/docs/apm/distributed-tracing/getting-started/introduction-distributed-tracing):方便用戶清楚地獲悉應用程序中不同事務的橫向服務。
- 儀表板(https://docs.newrelic.com/docs/dashboards/new-relic-one-dashboards/get-started/introduction-new-relic-one-dashboards):在壓力測試期間,通過靈活的交互方式,可視化地跟蹤那些用戶感興趣的KPI。
原文標題:How to Use New Relic for Performance Engineering and Load Testing ,作者:Rebecca Clinard
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】