高并發(fā)幾十萬的寫入,Kafka是如何實現(xiàn)的?
開篇
當下流行的MQ有很多,因為我們公司在技術選型上選擇了使用Kafka,所以我就整理了一篇關于Kafka的入門知識。通過技術選型 我們對業(yè)界主流的MQ進行了對比,Kakfa最大的優(yōu)點就是吞吐量高 。
Kafka是高吞吐低延遲的高并發(fā)、高性能的消息中間件,在大數(shù)據(jù)領域有極為廣泛的運用。配置良好的Kafka集群甚至可以做到每秒幾十萬、上百萬的超高并發(fā)寫入。
那么Kafka是如何做到這么高的吞吐量和性能的呢?在入門之后我們就來深入的扒一下Kafka的架構設計原理,掌握這些原理在互聯(lián)網(wǎng)面試中會占據(jù)優(yōu)勢
持久化
Kafka對消息的存儲和緩存依賴于文件系統(tǒng),每次接收數(shù)據(jù)都會往磁盤上寫,人們對于“磁盤速度慢”的普遍印象,使得人們對于持久化的架構能夠提供強有力的性能產(chǎn)生懷疑。
事實上,磁盤的速度比人們預期的要慢的多,也快得多,這取決于人們使用磁盤的方式。而且設計合理的磁盤結構通常可以和網(wǎng)絡一樣快。
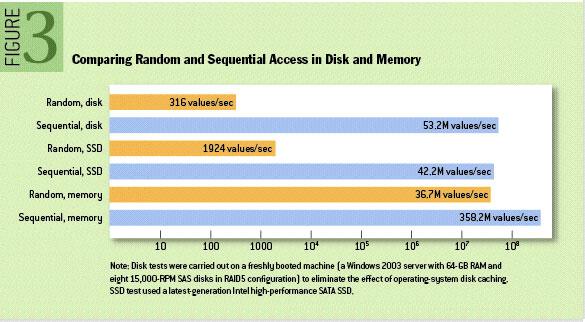
通過上圖對比,我們可以看出實際上順序磁盤訪問在某些情況下比隨機內存訪問還要快,其實Kafka就是利用這一優(yōu)勢來實現(xiàn)高性能寫磁盤
See:http://kafka.apachecn.org/documentation.html#persistence
頁緩存技術 + 磁盤順序寫
Kafka 為了保證磁盤寫入性能,首先Kafka是基于操作系統(tǒng)的頁緩存來實現(xiàn)文件寫入的。
操作系統(tǒng)本身有一層緩存,叫做page cache,是在內存里的緩存,我們也可以稱之為os cache,意思就是操作系統(tǒng)自己管理的緩存。
你在寫磁盤文件的時候,可以直接寫入os cache 中,也就是僅僅寫入內存中,接下來由操作系統(tǒng)自己決定什么時候把os cache 里的數(shù)據(jù)真的刷入到磁盤中。
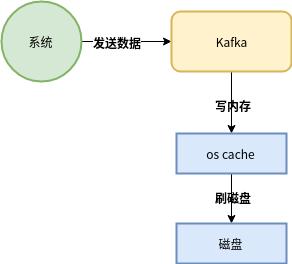
通過上圖這種方式可以將磁盤文件的寫性能提升很多,其實這種方式相當于寫內存,不是在寫磁盤
順序寫磁盤
另外還有非常關鍵的一點,Kafka在寫數(shù)據(jù)的時候是以磁盤順序寫的方式來落盤的,也就是說,僅僅將數(shù)據(jù)追加到文件的末尾(append),而不是在文件的隨機位置來修改數(shù)據(jù)。
對于普通的機械硬盤如果你要是隨機寫的話,確實性能極低,這里涉及到磁盤尋址的問題。但是如果只是追加文件末尾按照順序的方式來寫數(shù)據(jù)的話,那么這種磁盤順序寫的性能基本上可以跟寫內存的性能本身是差不多的。
來總結一下: Kafka就是基于頁緩存技術 + 磁盤順序寫 技術實現(xiàn)了寫入數(shù)據(jù)的超高性能。
所以要保證每秒寫入幾萬甚至幾十萬條數(shù)據(jù)的核心點,就是盡最大可能提升每條數(shù)據(jù)寫入的性能,這樣就可以在單位時間內寫入更多的數(shù)據(jù)量,提升吞吐量。
零拷貝技術(zero-copy)
說完了寫入這塊,再來談談消費這塊。
大家應該都知道,從Kafka里我們經(jīng)常要消費數(shù)據(jù),那么消費的時候實際上就是要從kafka的磁盤文件里讀取某條數(shù)據(jù)然后發(fā)送給下游的消費者,如下圖所示:
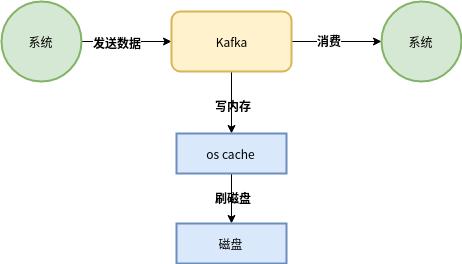
如果Kafka以上面這種方式從磁盤中讀取數(shù)據(jù)發(fā)送給下游的消費者,大概過程是:
- 先看看要讀的數(shù)據(jù)在不在os cache中,如果不在的話就從磁盤文件里讀取數(shù)據(jù)后放入os cache
- 接著從操作系統(tǒng)的os cache 里拷貝數(shù)據(jù)到應用程序進程的緩存里,再從應用程序進程的緩存里拷貝數(shù)據(jù)到操作系統(tǒng)層面的Socket緩存里,最后從Soket緩存里提取數(shù)據(jù)后發(fā)送到網(wǎng)卡,最后發(fā)送出去給下游消費者
整個過程如下圖:
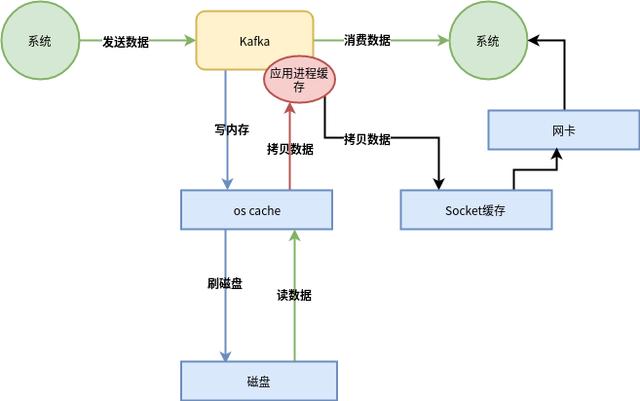
從上圖可以看出,這整個過程有兩次沒必要的拷貝
一次是從操作系統(tǒng)的cache里拷貝到應用進程的緩存里,接著又從應用程序緩存里拷貝回操作系統(tǒng)的Socket緩存里。
而且為了進行這兩次拷貝,中間還發(fā)生了好幾次上下文切換,一會兒是應用程序在執(zhí)行,一會兒上下文切換到操作系統(tǒng)來執(zhí)行。
所以這種方式來讀取數(shù)據(jù)是比較消耗性能的。
Kafka 為了解決這個問題,在讀數(shù)據(jù)的時候是引入零拷貝技術。
也就是說,直接讓操作系統(tǒng)的cache中的數(shù)據(jù)發(fā)送到網(wǎng)卡后傳出給下游的消費者,中間跳過了兩次拷貝數(shù)據(jù)的步驟,Socket緩存中僅僅會拷貝一個描述符過去,不會拷貝數(shù)據(jù)到Socket緩存。
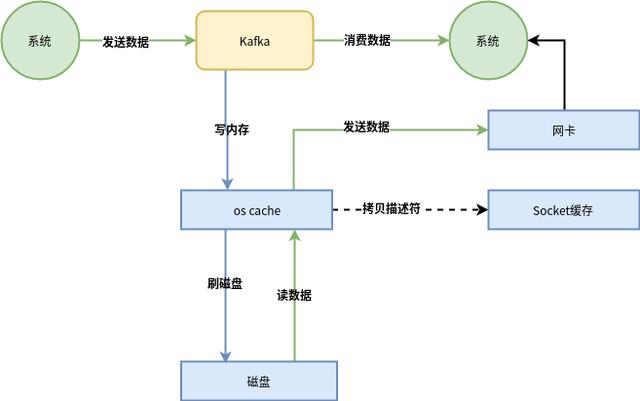
體會一下這個精妙的過程吧
通過零拷貝技術,就不需要把os cache里的數(shù)據(jù)拷貝到應用緩存,再從應用緩存拷貝到Socket緩存了,兩次拷貝都省略了,所以叫做零拷貝。
對Socket緩存僅僅就是拷貝數(shù)據(jù)的描述符過去,然后數(shù)據(jù)就直接從os cache中發(fā)送到網(wǎng)卡上去了,這個過程大大的提升了數(shù)據(jù)消費時讀取文件數(shù)據(jù)的性能。
而且大家會注意到,在從磁盤讀數(shù)據(jù)的時候,會先看看os cache內存中是否有,如果有的話,其實讀數(shù)據(jù)都是直接讀內存的。
如果kafka集群經(jīng)過良好的調優(yōu),大家會發(fā)現(xiàn)大量的數(shù)據(jù)都是直接寫入os cache中,然后讀數(shù)據(jù)的時候也是從os cache中讀。
相當于是Kafka完全基于內存提供數(shù)據(jù)的寫和讀了,所以這個整體性能會極其的高。
總結
通過學習Kafka的優(yōu)秀設計,我們了解了Kafka底層的頁緩存技術的使用,磁盤順序寫的思路,以及零拷貝技術的運用,才能使得Kafka有那么高的性能,做到每秒幾十萬的吞吐量。
名詞解釋
吞吐量(TPS):吞吐量是指對網(wǎng)絡、設備、端口、虛電路或其他設施,單位時間內成功地傳送數(shù)據(jù)的數(shù)量(以比特、字節(jié)、分組等測量)