













機器學習第一步,這是一篇手把手的隨機森林入門實戰
到了 2020 年,我們已經能找到很多好玩的機器學習教程。本文則從最流行的隨機森林出發,手把手教你構建一個模型,它的完整流程到底是什么樣的。
作為數據科學家,我們可以通過很多方法來創建分類模型。最受歡迎的方法之一是隨機森林。我們可以在隨機森林上調整超參數來優化模型的性能。
在用模型擬合之前,嘗試主成分分析(PCA)也是常見的做法。但是,為什么還要增加這一步呢?難道隨機森林的目的不是幫助我們更輕松地理解特征重要性嗎?
當我們分析隨機森林模型的「特征重要性」時,PCA 會使每個「特征」的解釋變得更加困難。但是 PCA 會進行降維操作,這可以減少隨機森林要處理的特征數量,因此 PCA 可能有助于加快隨機森林模型的訓練速度。
請注意,計算成本高是隨機森林的最大缺點之一(運行模型可能需要很長時間)。尤其是當你使用數百甚至上千個預測特征時,PCA 就變得非常重要。因此,如果只想簡單地擁有最佳性能的模型,并且可以犧牲解釋特征的重要性,那么 PCA 可能會很有用。
現在讓我們舉個例子。我們將使用 Scikit-learn 的「乳腺癌」數據集,并創建 3 個模型,比較它們的性能:
1. 隨機森林
2. 具有 PCA 降維的隨機森林
3. 具有 PCA 降維和超參數調整的隨機森林
導入數據
首先,我們加載數據并創建一個 DataFrame。這是 Scikit-learn 預先清理的「toy」數據集,因此我們可以繼續快速建模。但是,作為最佳實踐,我們應該執行以下操作:
- 使用 df.head()查看新的 DataFrame,以確保它符合預期。
- 使用 df.info()可以了解每一列中的數據類型和數據量。可能需要根據需要轉換數據類型。
- 使用 df.isna()確保沒有 NaN 值。可能需要根據需要處理缺失值或刪除行。
- 使用 df.describe()可以了解每列的最小值、最大值、均值、中位數、標準差和四分位數范圍。
名為「cancer」的列是我們要使用模型預測的目標變量。「0」表示「無癌癥」,「1」表示「癌癥」。
- import pandas as pd
- from sklearn.datasets import load_breast_cancercolumns = ['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness', 'mean compactness', 'mean concavity', 'mean concave points', 'mean symmetry', 'mean fractal dimension', 'radius error', 'texture error', 'perimeter error', 'area error', 'smoothness error', 'compactness error', 'concavity error', 'concave points error', 'symmetry error', 'fractal dimension error', 'worst radius', 'worst texture', 'worst perimeter', 'worst area', 'worst smoothness', 'worst compactness', 'worst concavity', 'worst concave points', 'worst symmetry', 'worst fractal dimension']dataset = load_breast_cancer()
- data = pd.DataFrame(dataset['data'], columns=columns)
- data['cancer'] = dataset['target']display(data.head())
- display(data.info())
- display(data.isna().sum())
- display(data.describe())
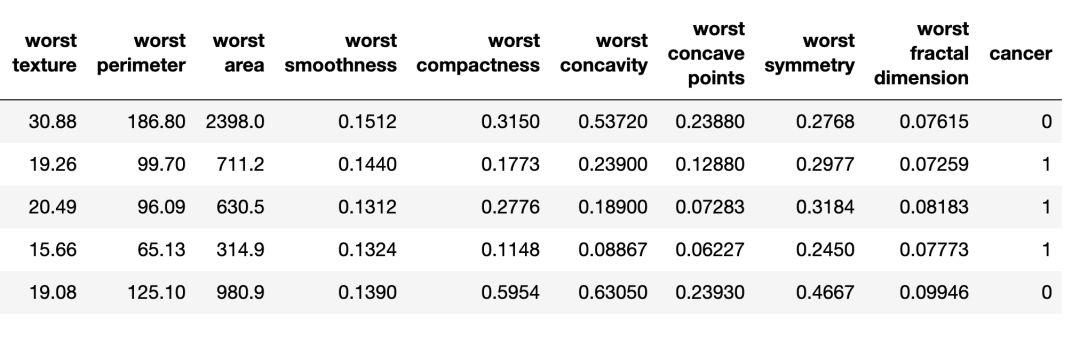
上圖是乳腺癌 DataFrame 的一部分。每行是一個患者的觀察結果。最后一列名為「cancer」是我們要預測的目標變量。0 表示「無癌癥」,1 表示「癌癥」。
訓練集/測試集分割
現在,我們使用 Scikit-learn 的「train_test_split」函數拆分數據。我們想讓模型有盡可能多的數據進行訓練。但是,我們也要確保有足夠的數據來測試模型。通常數據集中行數越多,我們可以提供給訓練集的數據越多。
例如,如果我們有數百萬行,那么我們可以將其中的 90%用作訓練,10%用作測試。但是,我們的數據集只有 569 行,數據量并不大。因此,為了匹配這種小型數據集,我們會將數據分為 50%的訓練和 50%的測試。我們設置 stratify = y 以確保訓練集和測試集與原始數據集的 0 和 1 的比例一致。
- from sklearn.model_selection import train_test_splitX = data.drop('cancer', axis=1)
- y = data['cancer']
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state = 2020, stratify=y)
規范化數據
在建模之前,我們需要先將數據「居中」和「標準化」,對不同的變量要在相同尺度進行測量。我們進行縮放以便決定預測變量的特征可以彼此「公平競爭」。我們還將「y_train」從 Pandas「Series」對象轉換為 NumPy 數組,以供模型稍后接收訓練數據。
- import numpy as np
- from sklearn.preprocessing import StandardScalerss = StandardScaler()
- X_train_scaled = ss.fit_transform(X_train)
- X_test_scaled = ss.transform(X_test)
- y_train = np.array(y_train)
擬合「基線」隨機森林模型
現在,我們創建一個「基線」隨機森林模型。該模型使用 Scikit-learn 隨機森林分類器文檔中定義的所有預測特征和默認設置。首先,我們實例化模型并使用規范化的數據擬合模型。我們可以通過訓練數據測量模型的準確性。
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.metrics import recall_scorerfc = RandomForestClassifier()
- rfc.fit(X_train_scaled, y_train)
- display(rfc.score(X_train_scaled, y_train))# 1.0
如果我們想知道哪些特征對隨機森林模型預測乳腺癌最重要,我們可以通過調用「feature_importances _」方法來可視化和量化這些重要特征:
- feats = {}
- for feature, importance in zip(data.columns, rfc_1.feature_importances_):
- feats[feature] = importanceimportances = pd.DataFrame.from_dict(feats, orient='index').rename(columns={0: 'Gini-Importance'})
- importances = importances.sort_values(by='Gini-Importance', ascending=False)
- importances = importances.reset_index()
- importances = importances.rename(columns={'index': 'Features'})sns.set(font_scale = 5)
- sns.set(style="whitegrid", color_codes=True, font_scale = 1.7)
- fig, ax = plt.subplots()
- fig.set_size_inches(30,15)
- sns.barplot(x=importances['Gini-Importance'], y=importances['Features'], data=importances, color='skyblue')
- plt.xlabel('Importance', fontsize=25, weight = 'bold')
- plt.ylabel('Features', fontsize=25, weight = 'bold')
- plt.title('Feature Importance', fontsize=25, weight = 'bold')display(plt.show())
- display(importances)
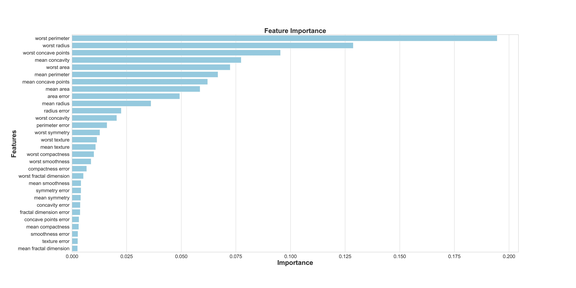
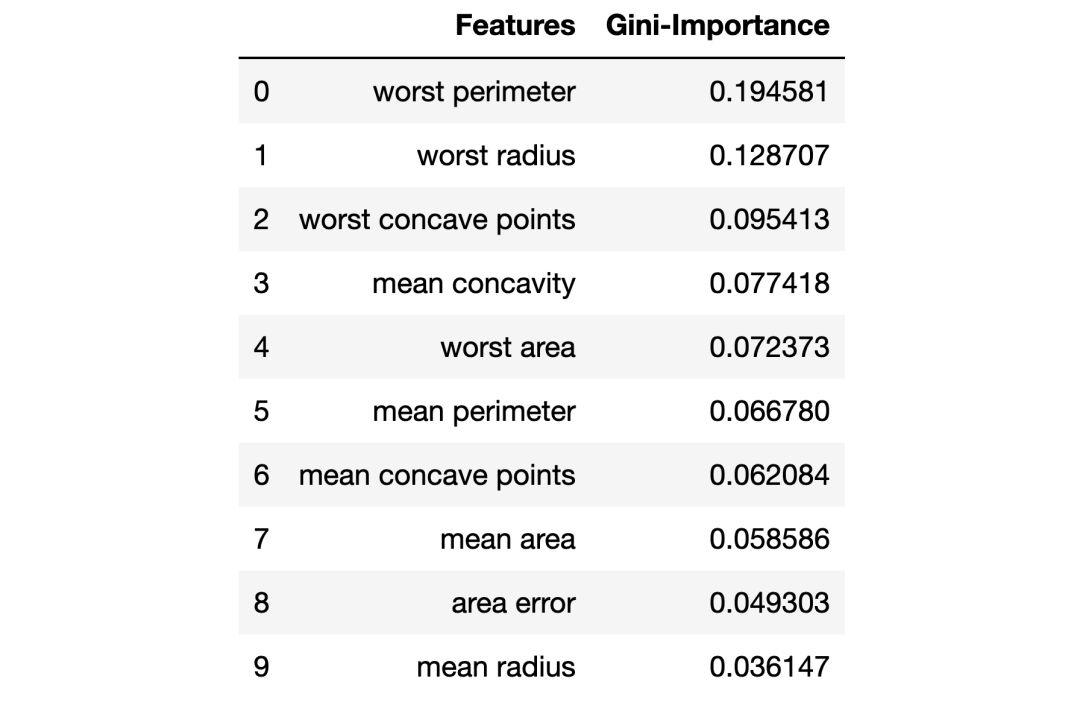
主成分分析(PCA)
現在,我們如何改進基線模型呢?使用降維,我們可以用更少的變量來擬合原始數據集,同時降低運行模型的計算花銷。使用 PCA,我們可以研究這些特征的累積方差比,以了解哪些特征代表數據中的最大方差。
我們實例化 PCA 函數并設置我們要考慮的成分(特征)數量。此處我們設置為 30,以查看所有生成成分的方差,并決定在何處切割。然后,我們將縮放后的 X_train 數據「擬合」到 PCA 函數中。
- import matplotlib.pyplot as plt
- import seaborn as sns
- from sklearn.decomposition import PCApca_test = PCA(n_components=30)
- pca_test.fit(X_train_scaled)sns.set(style='whitegrid')
- plt.plot(np.cumsum(pca_test.explained_variance_ratio_))
- plt.xlabel('number of components')
- plt.ylabel('cumulative explained variance')
- plt.axvline(linewidth=4, color='r', linestyle = '--', x=10, ymin=0, ymax=1)
- display(plt.show())evr = pca_test.explained_variance_ratio_
- cvr = np.cumsum(pca_test.explained_variance_ratio_)pca_df = pd.DataFrame()
- pca_df['Cumulative Variance Ratio'] = cvr
- pca_df['Explained Variance Ratio'] = evr
- display(pca_df.head(10))
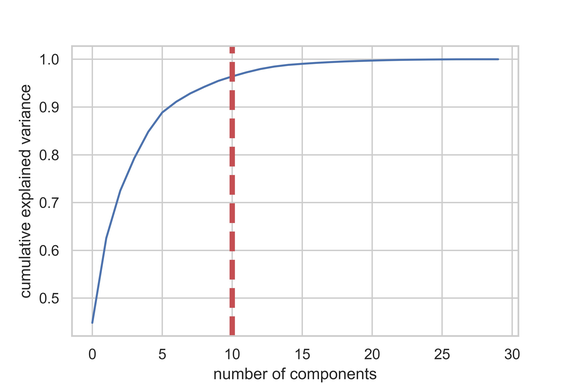
該圖顯示,在超過 10 個特征之后,我們并未獲得太多的解釋方差。此 DataFrame 顯示了累積方差比(解釋了數據的總方差)和解釋方差比(每個 PCA 成分說明了多少數據的總方差)。
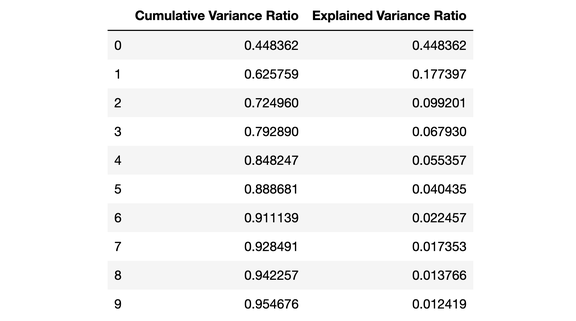
從上面的 DataFrame 可以看出,當我們使用 PCA 將 30 個預測變量減少到 10 個分量時,我們仍然可以解釋 95%以上的方差。其他 20 個分量僅解釋了不到 5%的方差,因此 我們可以減少他們的權重。按此邏輯,我們將使用 PCA 將 X_train 和 X_test 的成分數量從 30 個減少到 10 個。我們將這些重新創建的「降維」數據集分配給「X_train_scaled_pca」和「X_test_scaled_pca」。
- pca = PCA(n_components=10)
- pca.fit(X_train_scaled)X_train_scaled_pca = pca.transform(X_train_scaled)
- X_test_scaled_pca = pca.transform(X_test_scaled)
每個分量都是原始變量和相應「權重」的線性組合。通過創建一個 DataFrame,我們可以看到每個 PCA 成分的「權重」。
- pca_dims = []
- for x in range(0, len(pca_df)):
- pca_dims.append('PCA Component {}'.format(x))pca_test_df = pd.DataFrame(pca_test.components_, columns=columns, index=pca_dims)
- pca_test_df.head(10).T
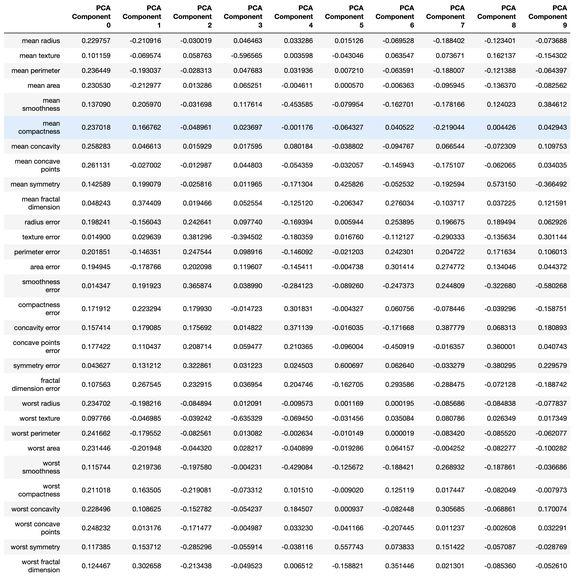
PCA 后擬合「基線」隨機森林模型
現在,我們可以將 X_train_scaled_pca 和 y_train 數據擬合到另一個「基線」隨機森林模型中,測試我們對該模型的預測是否有所改進。
- rfc = RandomForestClassifier()
- rfc.fit(X_train_scaled_pca, y_train)display(rfc.score(X_train_scaled_pca, y_train))# 1.0
第 1 輪超參數調優:RandomSearchCV
實現 PCA 之后,我們還可以通過一些超參數調優來調整我們的隨機森林以獲得更好的預測效果。超參數可以看作模型的「設置」。兩個不同數據集的理想設置并不相同,因此我們必須「調整」模型。
首先,我們可以從 RandomSearchCV 開始考慮更多的超參值。所有隨機森林的超參數都可以在 Scikit-learn 隨機森林分類器文檔中找到。
我們生成一個「param_dist」,其值的范圍適用于每個超參數。實例化 RandomSearchCV,首先傳入我們的隨機森林模型,然后傳入「param_dist」、測試迭代次數以及交叉驗證次數。
超參數「n_jobs」可以決定要使用多少處理器內核來運行模型。設置「n_jobs = -1」將使模型運行最快,因為它使用了所有計算機核心。
我們將調整這些超參數:
- n_estimators:隨機森林中「樹」的數量。
- max_features:每個分割處的特征數。
- max_depth:每棵樹可以擁有的最大「分裂」數。
- min_samples_split:在樹的節點分裂前所需的最少觀察數。
- min_samples_leaf:每棵樹末端的葉節點所需的最少觀察數。
- bootstrap:是否使用 bootstrapping 來為隨機林中的每棵樹提供數據。(bootstrapping 是從數據集中進行替換的隨機抽樣。)
- from sklearn.model_selection import RandomizedSearchCVn_estimators = [int(x) for x in np.linspace(start = 100, stop = 1000, num = 10)]max_features = ['log2', 'sqrt']max_depth = [int(x) for x in np.linspace(start = 1, stop = 15, num = 15)]min_samples_split = [int(x) for x in np.linspace(start = 2, stop = 50, num = 10)]min_samples_leaf = [int(x) for x in np.linspace(start = 2, stop = 50, num = 10)]bootstrap = [True, False]param_dist = {'n_estimators': n_estimators,
- 'max_features': max_features,
- 'max_depth': max_depth,
- 'min_samples_split': min_samples_split,
- 'min_samples_leaf': min_samples_leaf,
- 'bootstrap': bootstrap}rs = RandomizedSearchCV(rfc_2,
- param_dist,
- n_iter = 100,
- cv = 3,
- verbose = 1,
- n_jobs=-1,
- random_state=0)rs.fit(X_train_scaled_pca, y_train)
- rs.best_params_
- ————————————————————————————————————————————
- # {'n_estimators': 700,
- # 'min_samples_split': 2,
- # 'min_samples_leaf': 2,
- # 'max_features': 'log2',
- # 'max_depth': 11,
- # 'bootstrap': True}
在 n_iter = 100 且 cv = 3 的情況下,我們創建了 300 個隨機森林模型,對上面輸入的超參數進行隨機采樣組合。我們可以調用「best_params」以獲取性能最佳的模型參數(如上面代碼框底部所示)。
但是,現階段的「best_params」可能無法為我們提供最有效的信息,以獲取一系列參數來執行下一次超參數調整。為了在更大范圍內進行嘗試,我們可以輕松地獲得 RandomSearchCV 結果的 DataFrame。
- rs_df = pd.DataFrame(rs.cv_results_).sort_values('rank_test_score').reset_index(drop=True)
- rs_df = rs_df.drop([
- 'mean_fit_time',
- 'std_fit_time',
- 'mean_score_time',
- 'std_score_time',
- 'params',
- 'split0_test_score',
- 'split1_test_score',
- 'split2_test_score',
- 'std_test_score'],
- axis=1)
- rs_df.head(10)
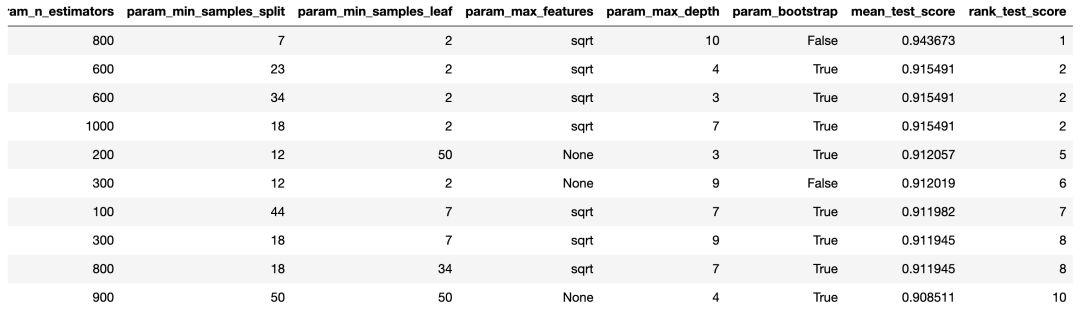
現在,讓我們在 x 軸上創建每個超參數的柱狀圖,并針對每個值制作模型的平均得分,查看平均而言最優的值:
- fig, axs = plt.subplots(ncols=3, nrows=2)
- sns.set(style="whitegrid", color_codes=True, font_scale = 2)
- fig.set_size_inches(30,25)sns.barplot(x='param_n_estimators', y='mean_test_score', data=rs_df, ax=axs[0,0], color='lightgrey')
- axs[0,0].set_ylim([.83,.93])axs[0,0].set_title(label = 'n_estimators', size=30, weight='bold')sns.barplot(x='param_min_samples_split', y='mean_test_score', data=rs_df, ax=axs[0,1], color='coral')
- axs[0,1].set_ylim([.85,.93])axs[0,1].set_title(label = 'min_samples_split', size=30, weight='bold')sns.barplot(x='param_min_samples_leaf', y='mean_test_score', data=rs_df, ax=axs[0,2], color='lightgreen')
- axs[0,2].set_ylim([.80,.93])axs[0,2].set_title(label = 'min_samples_leaf', size=30, weight='bold')sns.barplot(x='param_max_features', y='mean_test_score', data=rs_df, ax=axs[1,0], color='wheat')
- axs[1,0].set_ylim([.88,.92])axs[1,0].set_title(label = 'max_features', size=30, weight='bold')sns.barplot(x='param_max_depth', y='mean_test_score', data=rs_df, ax=axs[1,1], color='lightpink')
- axs[1,1].set_ylim([.80,.93])axs[1,1].set_title(label = 'max_depth', size=30, weight='bold')sns.barplot(x='param_bootstrap',y='mean_test_score', data=rs_df, ax=axs[1,2], color='skyblue')
- axs[1,2].set_ylim([.88,.92])
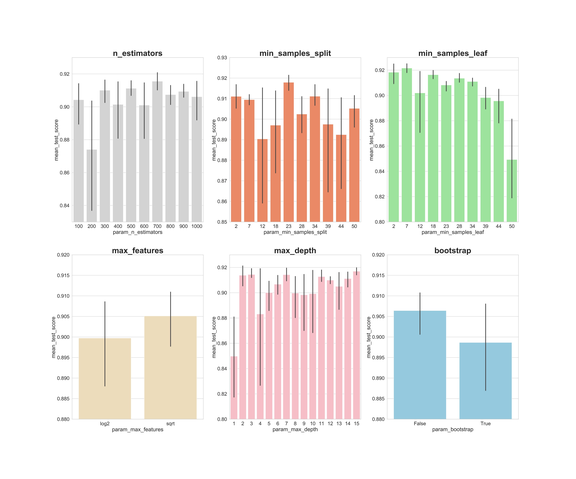
通過上面的圖,我們可以了解每個超參數的值的平均執行情況。
n_estimators:300、500、700 的平均分數幾乎最高;
min_samples_split:較小的值(如 2 和 7)得分較高。23 處得分也很高。我們可以嘗試一些大于 2 的值,以及 23 附近的值;
min_samples_leaf:較小的值可能得到更高的分,我們可以嘗試使用 2–7 之間的值;
max_features:「sqrt」具有最高平均分;
max_depth:沒有明確的結果,但是 2、3、7、11、15 的效果很好;
bootstrap:「False」具有最高平均分。
現在我們可以利用這些結論,進入第二輪超參數調整,以進一步縮小選擇范圍。
第 2 輪超參數調整:GridSearchCV
使用 RandomSearchCV 之后,我們可以使用 GridSearchCV 對目前最佳超參數執行更精細的搜索。超參數是相同的,但是現在我們使用 GridSearchCV 執行更「詳盡」的搜索。
在 GridSearchCV 中,我們嘗試每個超參數的單獨組合,這比 RandomSearchCV 所需的計算力要多得多,在這里我們可以直接控制要嘗試的迭代次數。例如,僅對 6 個參數搜索 10 個不同的參數值,具有 3 折交叉驗證,則需要擬合模型 3,000,000 次!這就是為什么我們在使用 RandomSearchCV 之后執行 GridSearchCV,這能幫助我們首先縮小搜索范圍。
因此,利用我們從 RandomizedSearchCV 中學到的知識,代入每個超參數的平均最佳執行范圍:
- from sklearn.model_selection import GridSearchCVn_estimators = [300,500,700]
- max_features = ['sqrt']
- max_depth = [2,3,7,11,15]
- min_samples_split = [2,3,4,22,23,24]
- min_samples_leaf = [2,3,4,5,6,7]
- bootstrap = [False]param_grid = {'n_estimators': n_estimators,
- 'max_features': max_features,
- 'max_depth': max_depth,
- 'min_samples_split': min_samples_split,
- 'min_samples_leaf': min_samples_leaf,
- 'bootstrap': bootstrap}gs = GridSearchCV(rfc_2, param_grid, cv = 3, verbose = 1, n_jobs=-1)
- gs.fit(X_train_scaled_pca, y_train)
- rfc_3 = gs.best_estimator_
- gs.best_params_
- ————————————————————————————————————————————
- # {'bootstrap': False,
- # 'max_depth': 7,
- # 'max_features': 'sqrt',
- # 'min_samples_leaf': 3,
- # 'min_samples_split': 2,
- # 'n_estimators': 500}
在這里我們將對 3x 1 x 5x 6 x 6 x 1 = 540 個模型進行 3 折交叉驗證,總共是 1,620 個模型!現在,在執行 RandomizedSearchCV 和 GridSearchCV 之后,我們 可以調用「best_params_」獲得一個最佳模型來預測我們的數據(如上面代碼框的底部所示)。
根據測試數據評估模型的性能
現在,我們可以在測試數據上評估我們建立的模型。我們會測試 3 個模型:
- 基線隨機森林
- 具有 PCA 降維的基線隨機森林
- 具有 PCA 降維和超參數調優的基線隨機森林
讓我們為每個模型生成預測結果:
- y_pred = rfc.predict(X_test_scaled)
- y_pred_pca = rfc.predict(X_test_scaled_pca)
- y_pred_gs = gs.best_estimator_.predict(X_test_scaled_pca)
然后,我們為每個模型創建混淆矩陣,查看每個模型對乳腺癌的預測能力:
- from sklearn.metrics import confusion_matrixconf_matrix_baseline = pd.DataFrame(confusion_matrix(y_test, y_pred), index = ['actual 0', 'actual 1'], columns = ['predicted 0', 'predicted 1'])conf_matrix_baseline_pca = pd.DataFrame(confusion_matrix(y_test, y_pred_pca), index = ['actual 0', 'actual 1'], columns = ['predicted 0', 'predicted 1'])conf_matrix_tuned_pca = pd.DataFrame(confusion_matrix(y_test, y_pred_gs), index = ['actual 0', 'actual 1'], columns = ['predicted 0', 'predicted 1'])display(conf_matrix_baseline)
- display('Baseline Random Forest recall score', recall_score(y_test, y_pred))
- display(conf_matrix_baseline_pca)
- display('Baseline Random Forest With PCA recall score', recall_score(y_test, y_pred_pca))
- display(conf_matrix_tuned_pca)
- display('Hyperparameter Tuned Random Forest With PCA Reduced Dimensionality recall score', recall_score(y_test, y_pred_gs))
下面是預測結果:
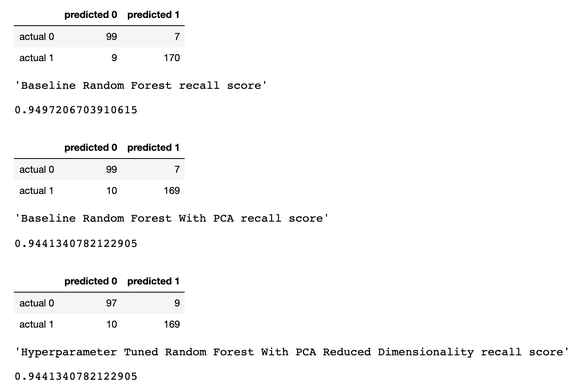
我們將召回率作為性能指標,因為我們處理的是癌癥診斷,我們最關心的是將模型中的假陰性預測誤差最小。
考慮到這一點,看起來我們的基線隨機森林模型表現最好,召回得分為 94.97%。根據我們的測試數據集,基線模型可以正確預測 179 名癌癥患者中的 170 名。
這個案例研究提出了一個重要的注意事項:有時,在 PCA 之后,甚至在進行大量的超參數調整之后,調整的模型性能可能不如普通的「原始」模型。但是嘗試很重要,你不嘗試,就永遠都不知道哪種模型最好。在預測癌癥方面,模型越好,可以挽救的生命就更多。

















