













「算法與數(shù)據(jù)結(jié)構(gòu)」Trie樹之美
前言
這次分享的Trie字典樹,是數(shù)據(jù)結(jié)構(gòu)專題中的一個(gè)分支,認(rèn)識(shí)了解Trie這種樹型數(shù)據(jù)結(jié)構(gòu),對(duì)構(gòu)建算法與數(shù)據(jù)結(jié)構(gòu)知識(shí)體系有一定的幫助。
我對(duì)Trie樹的理解:把字符串都串接起來,消滅不必要的存儲(chǔ),利用的就是字符串的公共前綴。
其實(shí)對(duì)于它的理解,你理解了這句話即可👇
利用字符串的公共前綴來減少查詢時(shí)間,最大限度的減少無謂的字符串比較,查詢效率比哈希樹高。
如果你還不了解什么是Trie數(shù)據(jù)結(jié)構(gòu)的話,或者知道一些,但是對(duì)于它具體是如何實(shí)現(xiàn)一個(gè)簡單Trie樹時(shí),那么這篇文章可能適合你閱讀。
那么圍繞以下幾個(gè)點(diǎn)來展開介紹Trie樹👇
- 基本概念
- 基本性質(zhì)
- 應(yīng)用場景
- 2個(gè)例題
基本概念
首先,我們對(duì)Trie樹得做一些基本的了解。Trie樹中文名叫字典樹,前綴樹等,接下來我就以字典樹稱呼。
我們來看下維基百科對(duì)它的描述吧⬇️
在計(jì)算機(jī)科學(xué)中,trie,又稱前綴樹或字典樹,是一種有序樹,用于保存關(guān)聯(lián)數(shù)組,其中的鍵通常是字符串。與二叉查找樹不同,鍵不是直接保存在節(jié)點(diǎn)中,而是由節(jié)點(diǎn)在樹中的位置決定。一個(gè)節(jié)點(diǎn)的所有子孫都有相同的前綴,也就是這個(gè)節(jié)點(diǎn)對(duì)應(yīng)的字符串,而根節(jié)點(diǎn)對(duì)應(yīng)空字符串。一般情況下,不是所有的節(jié)點(diǎn)都有對(duì)應(yīng)的值,只有葉子節(jié)點(diǎn)和部分內(nèi)部節(jié)點(diǎn)所對(duì)應(yīng)的鍵才有相關(guān)的值。
樸實(shí)無華的描述,其實(shí)我們看一張圖就能看明白了~,我在網(wǎng)上找了一張不錯(cuò)的圖,具體的出處,這里就不補(bǔ)充了,因?yàn)閷?shí)在找不到原作者~
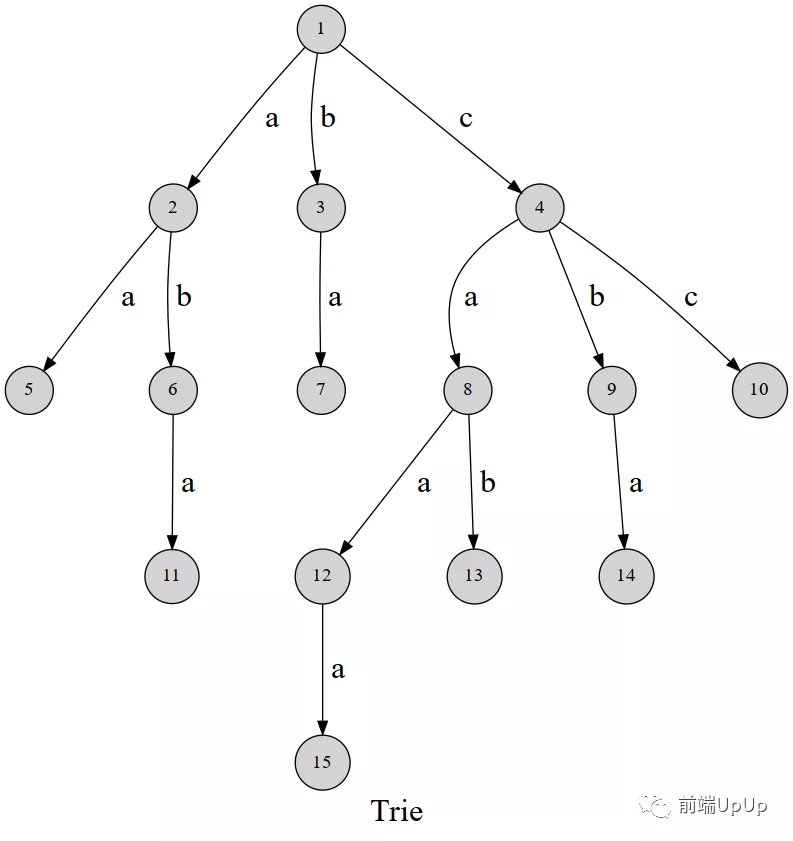
字典樹圖解1
這里需要說明的內(nèi)容就是,一般而言,應(yīng)該是用一個(gè)點(diǎn)來表示一個(gè)字符,這里為了更好的說明,所以我就是用邊來描述字符。
可以發(fā)現(xiàn),這棵字典樹用邊來代表字母,而從根結(jié)點(diǎn)到樹上某一結(jié)點(diǎn)的路徑就代表了一個(gè)字符串。舉個(gè)例子, 1→2→6表示的就是字符串 aba 。
再比如,1→4→8構(gòu)成的字符串是ca,那么如果在往下拓展的話,我們是不是有 caa,cab,那么他們都會(huì)經(jīng)過1→4→8,這些路徑,說明他們是有一段公共的前綴,這個(gè)前綴的內(nèi)容就是ca,說道這里,我們就知道字典樹利用的就是字符串的前綴來解決問題。
那么具體它有哪些性質(zhì)的話,我們下文介紹一下~
基本性質(zhì)
對(duì)于上述概念有了一定的理解后,我們接下來就看下Trie樹的基本性質(zhì)。
可以根據(jù)這個(gè),大體上分成三個(gè)點(diǎn)來說👇
- 根節(jié)點(diǎn)不包含字符,除根節(jié)點(diǎn)外,每個(gè)節(jié)點(diǎn)只包含一個(gè)字符。
- 從根節(jié)點(diǎn)到某一個(gè)節(jié)點(diǎn),路徑上經(jīng)過的字符連接起來,為該節(jié)點(diǎn)對(duì)應(yīng)的字符串。
- 每個(gè)節(jié)點(diǎn)的所有子節(jié)點(diǎn)包含的字符串不相同。
接下來我們可以稍微分析一下,可以結(jié)合一個(gè)圖來看看👇
我們通過拿how,hi,her,hello,so,see這6個(gè)字符串構(gòu)造出來的就是下面圖這個(gè)樣子。
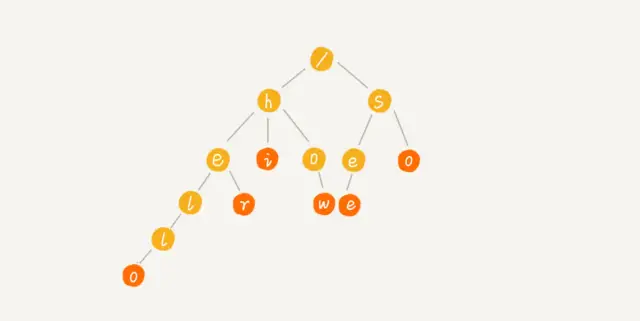
圖解Trie樹
第一個(gè)性質(zhì):
從圖中也可以看出,根節(jié)點(diǎn)是/, 代表的內(nèi)容也就是空,其他的節(jié)點(diǎn)比如,根節(jié)點(diǎn)下一個(gè)層級(jí),有 h和s,分別代表的是兩個(gè)字符。
第二個(gè)性質(zhì):
從根節(jié)點(diǎn)到某一個(gè)節(jié)點(diǎn),路徑上經(jīng)過的字符連接起來,為該節(jié)點(diǎn)對(duì)應(yīng)的字符串。
比如how表示的就是一個(gè)字符串,hi,也表示的是一個(gè)字符串,可是你會(huì)不會(huì)好奇,he和hel為什么不能表示一個(gè)字符串呢?
當(dāng)你想到這里的話,說明你已經(jīng)看得很仔細(xì),馬上就要掌握它了,確實(shí),從圖中看,我們會(huì)發(fā)現(xiàn)有些節(jié)點(diǎn)顏色不同,這是因?yàn)椋覀冾A(yù)定好以這個(gè)深色的節(jié)點(diǎn)代表當(dāng)前是一個(gè)字符串的結(jié)尾,想一想,這樣子的作用是啥?
那么實(shí)際代碼中,我們應(yīng)該如何去約定或者做個(gè)標(biāo)記呢,其實(shí)只要設(shè)置一個(gè)標(biāo)記位即可。
比如下面這樣子👇
- const TrieNode = function () {
- this.next = Object.create(null)
- this.isEnd = false
- };
當(dāng)前的isEnd變量就表示當(dāng)前的節(jié)點(diǎn)是不是結(jié)束串,當(dāng)isEnd為True時(shí),表示從根節(jié)點(diǎn)開始,到這個(gè)字符,所構(gòu)成的字符串是存在的,是一個(gè)完整的字符串。
第三個(gè)性質(zhì):
每個(gè)節(jié)點(diǎn)的所有子節(jié)點(diǎn)包含的字符串不相同。
很明顯,我們從根節(jié)點(diǎn)開始,依次往下走,會(huì)發(fā)現(xiàn),每個(gè)節(jié)點(diǎn)下面的節(jié)點(diǎn)是不相同的,所以依次組成的字符串不可能相同。
應(yīng)用場景
對(duì)Trie樹,有一定了解后,我們就可以看看它有哪些的實(shí)際應(yīng)用場景了。
這里參考的是網(wǎng)上所提供的幾個(gè)點(diǎn)👇
在搜索引擎中關(guān)鍵詞提示,引擎會(huì)自動(dòng)彈出匹配關(guān)鍵詞的下拉框,這種應(yīng)用場景大家應(yīng)該都很熟悉。
那么應(yīng)該如何利用一種高效的數(shù)據(jù)結(jié)構(gòu)存儲(chǔ)呢,這里就符合字典樹的性質(zhì),所以可以利用字典樹來構(gòu)造特定的數(shù)據(jù),達(dá)到一種更加快速檢索的效果。
字符串檢索
事先將已知的一些字符串(字典)的有關(guān)信息保存到trie樹里,查找另外一些未知字符串是否出現(xiàn)過或者出現(xiàn)頻率,可以舉例子說明情況👇
- 1000萬字符串,其中有些是重復(fù)的,需要把重復(fù)的全部去掉,保留沒有重復(fù)的字符串。
- 給出N 個(gè)單詞組成的熟詞表,以及一篇全用小寫英文書寫的文章,請(qǐng)你按最早出現(xiàn)的順序?qū)懗鏊胁辉谑煸~表中的生詞。
詞頻統(tǒng)計(jì)
給定很長的一個(gè)串,統(tǒng)計(jì)頻數(shù)出現(xiàn)次數(shù)最多情況,舉個(gè)例子👇
- 有一個(gè)1G大小的一個(gè)文件,里面每一行是一個(gè)詞,詞的大小不超過16字節(jié),內(nèi)存限制大小是1M。返回頻數(shù)最高的100個(gè)詞。
- 一個(gè)文本文件,大約有一萬行,每行一個(gè)詞,要求統(tǒng)計(jì)出其中最頻繁出現(xiàn)的前10個(gè)詞,請(qǐng)給出思想,給出時(shí)間復(fù)雜度分析。
字符串最長公共前綴
到現(xiàn)在,我們應(yīng)該知道,Trie樹利用多個(gè)字符串的公共前綴來節(jié)省存儲(chǔ)空間,當(dāng)我們把大量字符串存儲(chǔ)到一棵trie樹上時(shí),我們可以快速得到某些字符串的公共前綴,所以可以利用這個(gè)特點(diǎn)來解決一些前綴問題。
非要舉個(gè)例子的話,有個(gè)例子👇
- 給出N 個(gè)小寫英文字母串,以及Q 個(gè)詢問,即詢問某兩個(gè)串的最長公共前綴的長度是多少?
應(yīng)用場景還是有很多的,剩下的可以自行去探索,接下來,我們通過實(shí)際的題目來看看,如何構(gòu)造字典樹吧~
2個(gè)例子
接下來,我們通過二個(gè)題目作為例子,來看看字典樹在實(shí)際應(yīng)用可以解決哪些問題👇
詞典中最長的單詞⭐
鏈接:詞典中最長的單詞
給出一個(gè)字符串?dāng)?shù)組words組成的一本英語詞典。從中找出最長的一個(gè)單詞,該單詞是由words詞典中其他單詞逐步添加一個(gè)字母組成。若其中有多個(gè)可行的答案,則返回答案中字典序最小的單詞。
若無答案,則返回空字符串。
示例 1:
- 輸入:
- words = ["w","wo","wor","worl", "world"]
- 輸出:"world"
- 解釋:
- 單詞"world"可由"w", "wo", "wor", 和 "worl"添加一個(gè)字母組成。
示例 2:
- 輸入:
- words = ["a", "banana", "app", "appl", "ap", "apply", "apple"]
- 輸出:"apple"
- 解釋:
- "apply"和"apple"都能由詞典中的單詞組成。但是"apple"的字典序小于"apply"。
提示:
這題無非就是找到一個(gè)最長的單詞,可以拆分成words數(shù)組中某一部分,最暴力的思路就是去枚舉每一項(xiàng),但是這樣子的時(shí)間復(fù)雜度是巨大的, 這個(gè)時(shí)候,我們是不是可以思考一下,這個(gè)問題有哪些地方是共性的呢?
- 沒錯(cuò),就是前綴是相同的,從這點(diǎn)來看,是不是就可以利用這個(gè)前綴樹,把它數(shù)據(jù)存儲(chǔ)下來
- 然后遍歷一遍字典樹,只要這顆樹只有一個(gè)分支,則表示它有解,如果存在兩個(gè)分支以上的話,則無答案。
復(fù)雜度分析
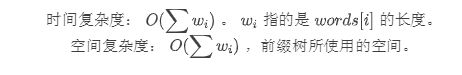
這點(diǎn)應(yīng)該很好理解,這里就跳過了。
這里的話,我的解法構(gòu)造字典樹,當(dāng)然了,也有其他的解法,這里就不展開了,可以看下我的代碼噢~
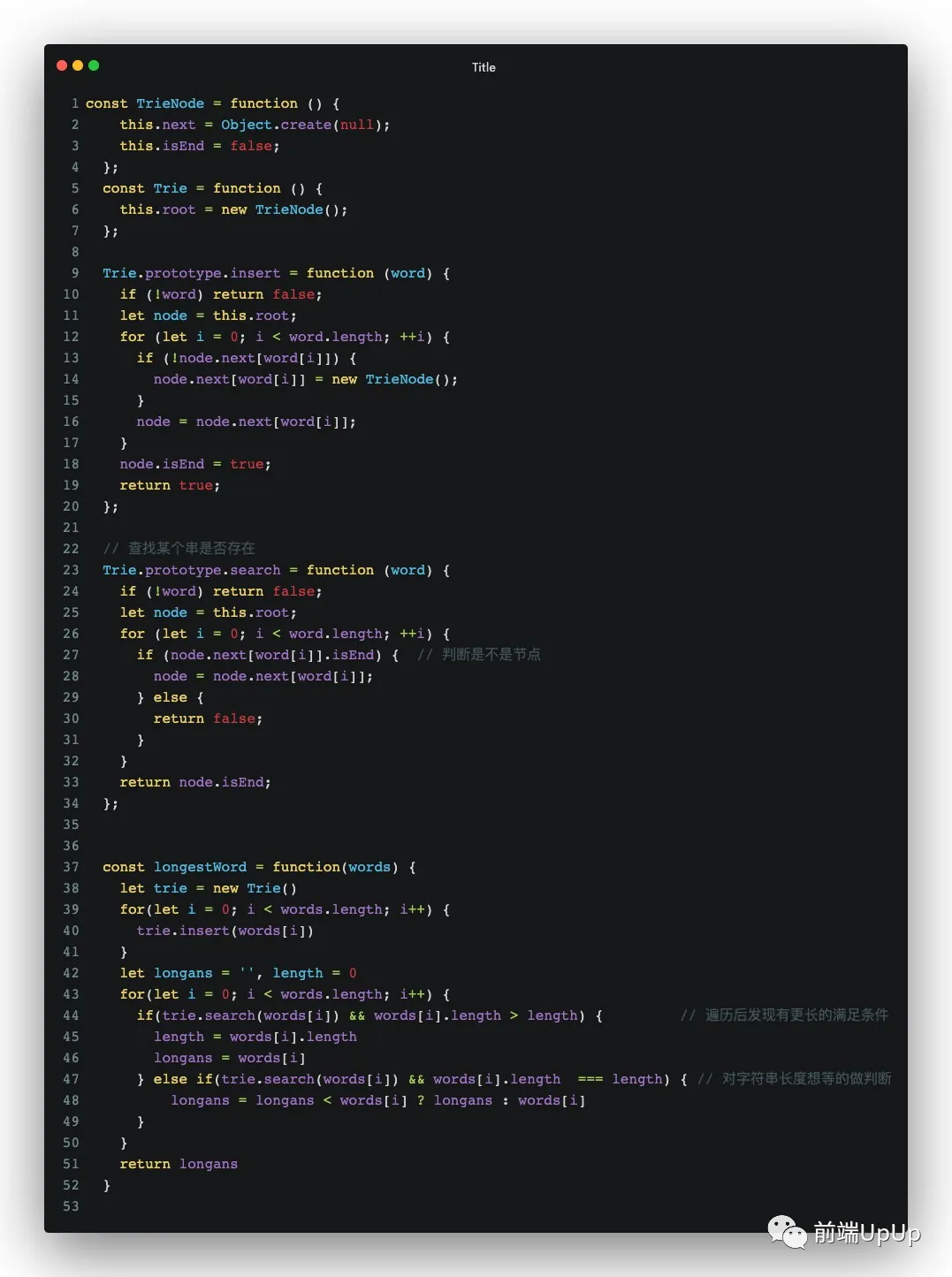
代碼點(diǎn)這里☑️
其實(shí)你會(huì)發(fā)現(xiàn),構(gòu)造一個(gè)Trie樹的話,是很消耗空間的,有點(diǎn)空間換時(shí)間的意思,所以具體得根據(jù)實(shí)際的題目來解決問題。
實(shí)現(xiàn)Trie(前綴樹)⭐⭐
鏈接:實(shí)現(xiàn) Trie (前綴樹)
實(shí)現(xiàn)一個(gè) Trie (前綴樹),包含 insert, search, 和 startsWith 這三個(gè)操作。
示例:
- Trie trie = new Trie();
- trie.insert("apple");
- trie.search("apple"); // 返回 true
- trie.search("app"); // 返回 false
- trie.startsWith("app"); // 返回 true
- trie.insert("app");
- trie.search("app"); // 返回 true
說明:
- 你可以假設(shè)所有的輸入都是由小寫字母 a-z 構(gòu)成的。
- 保證所有輸入均為非空字符串。
這個(gè)題目就是典型的寫Trie樹,對(duì)于第一次寫這個(gè)題目的話,如果沒有思路的話,可以嘗試先看看別人的代碼,看看基本的套路在哪里。
話不多說,可以參考這份代碼,可以看看如何構(gòu)造一顆字典樹👇
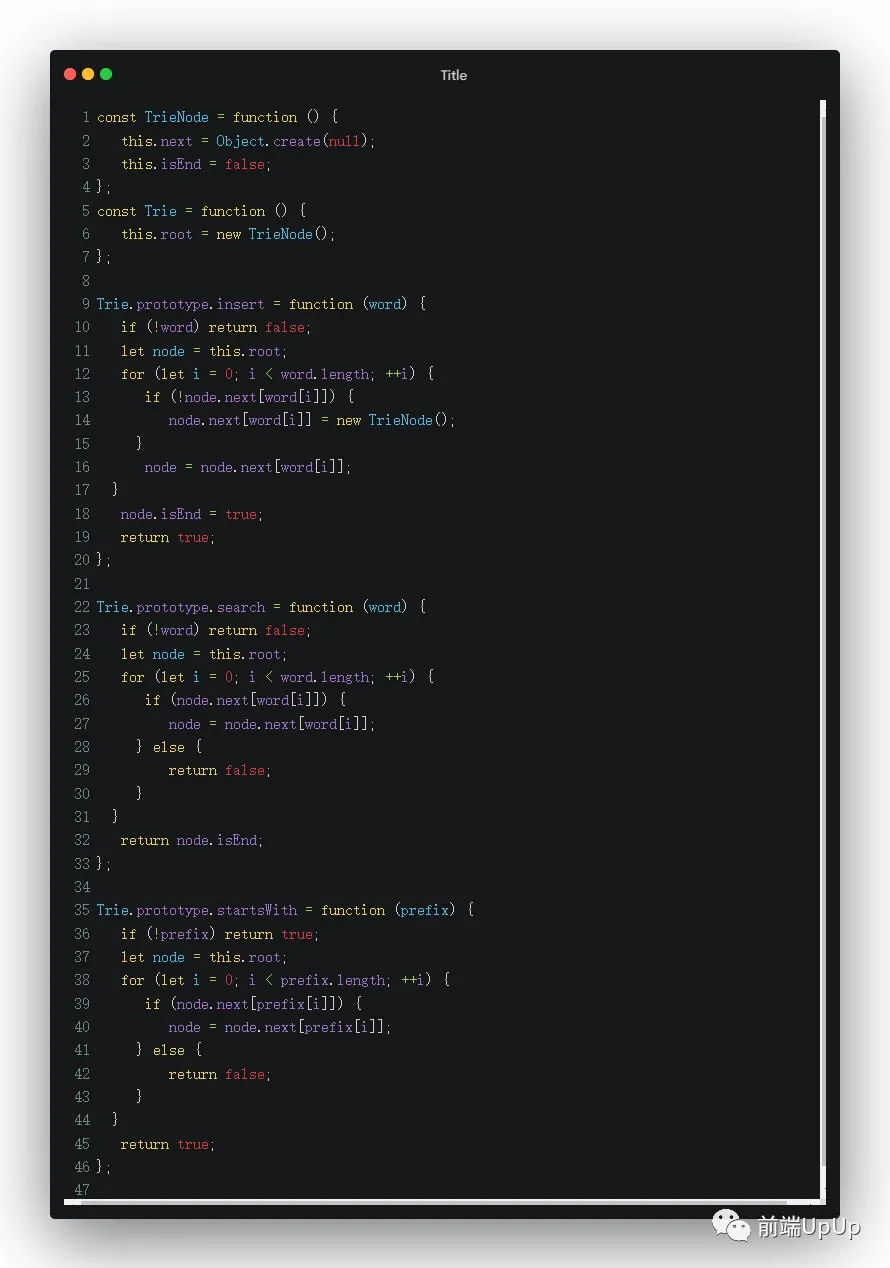
代碼點(diǎn)這里☑️
剩下的刪除操作,還有統(tǒng)計(jì)字符串出現(xiàn)的頻率,可以自己來實(shí)現(xiàn)一下,這個(gè)基本上不難,畫個(gè)圖,就知道如何實(shí)現(xiàn)啦~
題目是做不完的,做完這些題目后,希望你能對(duì)Trie字典樹有所認(rèn)識(shí),能對(duì)它有更加深入的理解~,接下來準(zhǔn)備了四道題集,希望對(duì)你們有幫助~
詞典中最長的單詞
實(shí)現(xiàn) Trie (前綴樹)
單詞搜索 II
Loading question


















