Apache Flink在bilibili的多元化探索與實踐
本文由 bilibili 大數據實時平臺負責人鄭志升分享,本次分享核心講解萬億級傳輸分發架構的落地,以及 AI 領域如何基于 Flink 打造一套完善的預處理實時 Pipeline。
本次分享主要圍繞以下四個方面:
一、B 站實時的前世與今生
二、Flink On Yarn 的增量化管道的方案
三、Flink 和 AI 方向的一些工程實踐
四、未來的發展與思考
一、B 站實時的前世與今生
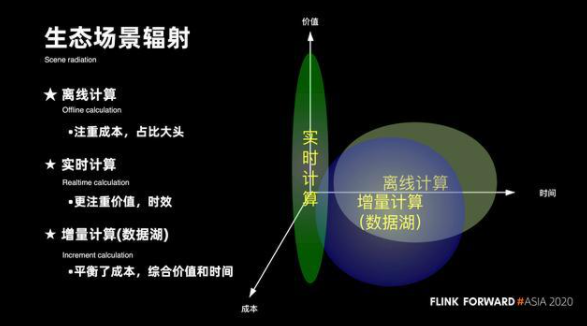
1. 生態場景輻射
說起實時計算的未來,關鍵詞就在于數據的實效性。首先從整個大數據發展的生態上,來看它的核心場景輻射:在大數據發展的初期,核心是以面向天為粒度的離線計算的場景。 那時候的數據實效性多數都是以運算以天為單位,它更加注重時間和成本的平衡。
隨著數據應用,數據分析以及數據倉庫的普及與完善,越來越多的人對數據的實效性提出了更高的要求。比如,當需要做一些數據的實時推薦時,數據的實效將決定它的價值。在這種情況下,整個實時計算的場景就普遍誕生。
但在實際的運作過程當中,也遇到了很多場景 ,其實并沒有對數據有非常高的實時性要求,在這種情況下必然會存在數據從毫秒,秒或者天的新的一些場景,實時場景數據更多是以分鐘為粒度的一些增量計算的場景。對于離線計算,它更加注重成本;對實時計算,它更加注重價值實效;而對于增量計算,它更加注重去平衡成本,以及綜合的價值和時間。
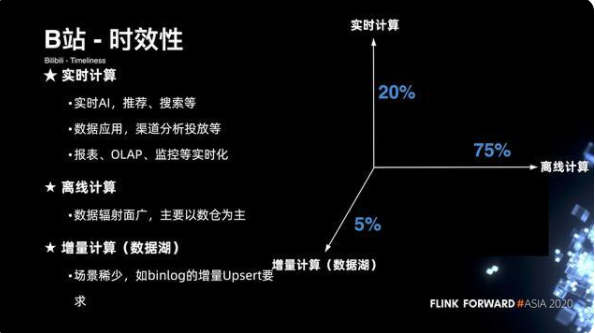
2. B 站的時效性
在三個維度上,B 站的劃分是怎樣的?對于 B 站而言 ,目前有 75% 的數據是通過離線計算來進行支撐的,另外還有 20% 的場景是通過實時計算, 5% 是通過增量計算。
對于實時計算的場景, 主要是應用在整個實時的機器學習、實時推薦、廣告搜索、數據應用、實時渠道分析投放、報表、olap、監控等;對于離線計算,數據輻射面廣,主要以數倉為主;對于增量計算,今年才啟動一些新的場景,比如說 binlog 的增量 Upsert 場景。
3. ETL 時效性差
對于實效性問題 ,其實早期遇到了很多痛點 ,核心集中在三個方面:
第一,傳輸管道缺乏計算能力。早期的方案,數據基本都是要按天落到 ODS ,DW 層是凌晨過后的第二天去掃描前一天所有 ODS 層的數據,也就是說,整體數據沒辦法前置清洗;第二,含有大量作業的資源集中爆發在凌晨之后,整個資源編排的壓力就會非常大;第三、實時和離線的 gap 是比較難滿足的,因為對于大部分的數據來說,純實時的成本過高,純離線的實效又太差。同時,MySQL 數據的入倉時效也不太夠。舉個例子,好比 B 站的彈幕數據 ,它的體量非常夸張,這種業務表的同步往往需要十幾個小時,而且非常的不穩定。

4. AI 實時工程復雜
除了實效性的問題 早期還遇到了 AI 實時工程比較復雜的問題:
第一,是整個特征工程計算效率的問題。同樣的實時特征的計算場景, 也需要在離線的場景上進行數據的回溯,計算邏輯就會重復開發;第二,整個實時鏈路比較長。一個完整的實時推薦鏈路, 涵蓋了 N 個實時和 M 個離線的十幾個作業組成,有時候遇到問題排查,整個鏈路的運維和管控成本都非常高;第三、隨著 AI 人員的增多,算法人員的投入,實驗迭代很難橫向擴展。

5. Flink 做了生態化的實踐
在這些關鍵痛點的背景下,我們集中針對 Flink 做了生態化的實踐,核心包括了整個實時數倉的應用以及整個增量化的 ETL 管道,還有面向 AI 的機器學習的一些場景。本次的分享會更加側重增量管道以及 AI 加 Flink 的方向上。下圖展示了整體的規模,目前,整個傳輸和計算的體量,在萬億級的消息規模有 30000+ 計算核數,1000+ job 數以及 100 多個用戶。

二、Flink On Yarn 的增量化管道的方案
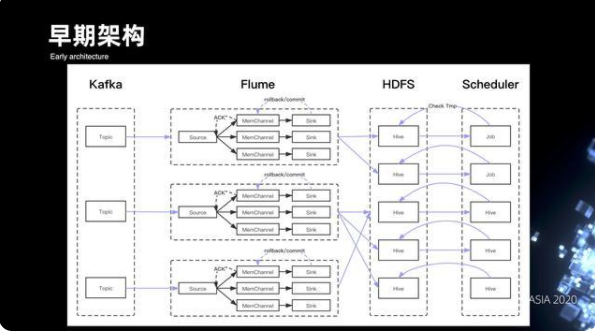
1. 早期的架構
先來看一下整個管道早期的架構,從下圖可以看出,數據其實主要是通過 Flume 來消費 Kafka 落到 HDFS。Flume 用它的事務機制,來確保數據從 Source 到 Channel, 再到 Sink 時候的一致性,最后數據落到 HDFS 之后,下游的 Scheduler 會通過掃描目錄下有沒有 tmp 文件,來判斷數據是否 Ready,以此來調度拉起下游的 ETL 離線作業。
2. 痛點
在早期遇到了不少痛點:
第一個比較關鍵的是數據質量。最先用的是 MemoryChannel,它會存在數據的丟失,之后也試過用 FileChannel 的模式,但性能上無法達到要求。此外在 HDFS 不太穩定的情況下,Flume 的事務機制就會導致數據會 rollback 回滾到 Channel,一定程度上會導致數據不斷的重復。在 HDFS 極度不穩定的情況下,最高的重復率會達到百分位的概率;Lzo 行存儲,早期的整個傳輸是通過分隔符的形式,這種分隔符的 Schema 是比較弱約束的,而且也不支持嵌套的格式。第二點是整個數據的時效,無法提供分鐘級的查詢,因為 Flume 不像 Flink 有 Checkpoint 斬斷的機制,更多是通過 idle 機制來控制文件的關閉;第三點是下游的 ETL 聯動。前文有提到,我們更多是通過掃描 tmp 目錄是否 ready 的方案,這種情況下 scheduler 會大量的和 NameNode 調用 hadoop list 的 api,這樣會導致 NameNode 的壓力比較大。

3. 穩定性相關的痛點
在穩定性上也遇到很多問題:
第一,Flume 是不帶狀態的,節點異常或者是重啟之后,tmp 沒法正常關閉;第二,早期沒有依附大數據的環境,是物理部署的模式,資源伸縮很難去把控,成本也會相對偏高;第三,Flume 和 HDFS 在通信上有問題。比如說當寫 HDFS 出現堵塞的情況,某一個節點的堵塞會反壓到 Channel,就會導致 Source 不會去 Kafka 消費數據,停止拉動 offset,一定程度上就會引發 Kafka 的 Rebalance,最后會導致全局 offset 不往前推進,從而導致數據的堆積。

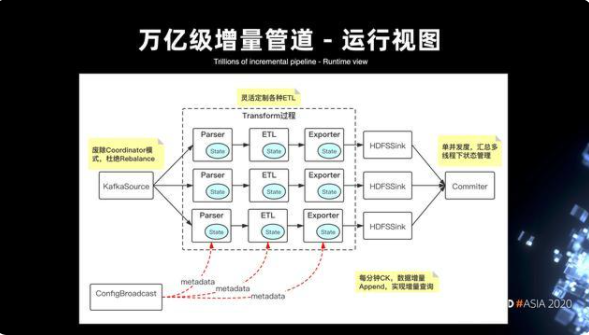
4. 萬億級的增量管道 DAG 視圖
在如上的痛點下,核心方案基于 Flink 構建了一套萬億級的增量管道,下圖是整個運行時的 DAG 視圖。
首先,在 Flink 架構下,KafkaSource 杜絕了 rebalance 的雪崩問題,即便整個 DAG 視圖中有某個并發度出現數據寫 HDFS 的堵塞,也不會導致全局所有 Kafka 分區的堵塞。此外的話,整個方案本質是通過 Transform 的模塊來實現可擴展的節點。
第一層節點是 Parser,它主要是做數據的解壓反序列化等的解析操作;第二層是引入提供給用戶的定制化 ETL 模塊,它可以實現數據在管道中的定制清洗;第三層是 Exporter 模塊,它支持將數據導出到不同的存儲介質。比如寫到 HDFS 時,會導出成 parquet;寫到 Kafka,會導出成 pb 格式。同時,在整個 DAG 的鏈路上引入了 ConfigBroadcast 的模塊來解決管道元數據實時更新、熱加載的問題。此外,在整個鏈路當中,每分鐘會進行一次 checkpoint,針對增量的實際數據進行 Append,這樣就可以提供分鐘級的查詢。
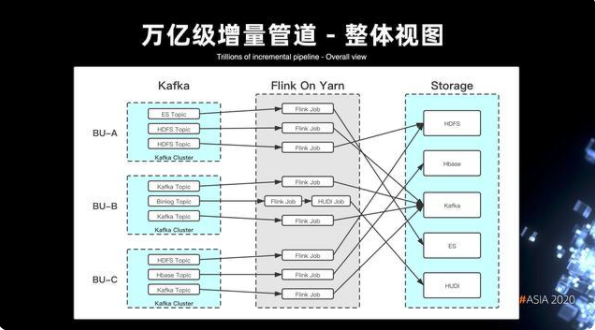
5. 萬億級的增量管道整體視圖
Flink On Yarn 的整體架構,可以看出其實整個管道視圖是劃分以 BU 為單位的。每個 Kafka 的 topic,都代表了某一種數據終端的分發,Flink 作業就會專門負責各種終端類型的寫入處理。視圖里面還可以看到,針對 blinlog 的數據,還實現了整個管道的組裝,可以由多個節點來實現管道的運作。
6. 技術亮點
接下來來看一下整個架構方案核心的一些技術亮點,前三個是實時功能層面的一些特色,后三個主要是在一些非功能性層面的一些優化。
對于數據模型來說,主要是通過 parquet,利用 Protobuf 到 parquet 的映射來實現格式收斂;分區通知主要是因為一條管道其實是處理多條流,核心解決的是多條流數據的分區 ready 的通知機制;CDC 管道更多是利用 binlog 和 HUDI 來實現 upsert 問題的解決;小文件主要是在運行時通過 DAG 拓撲的方式來解決文件合并的問題;HDFS 通信實際是在萬億級規模下的很多種關鍵問題的優化;最后是分區容錯的一些優化。

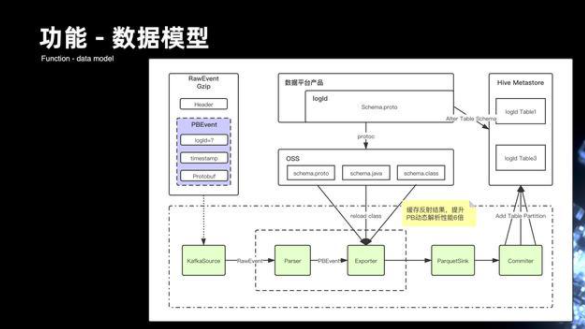
6.1 數據模型
業務的開發主要是通過拼裝字符串,來組裝數據的一條條記錄的上報。后期則是通過了模型的定義和管理,以及它的開發來組織的,主要是通過在平臺的入口提供給用戶去錄制每一條流、每個表,它的 Schema ,Schema 會將它生成 Protobuf 的文件,用戶可以在平臺上去下載 Protobuf 對應的 HDFS 模型文件,這樣,client 端的開發完全就可以通過強 Schema 方式從 pb 來進行約束。
來看一下運行時的過程,首先 Kafka 的 Source 會去消費實際上游傳過來的每一條 RawEvent 的記錄,RawEvent 里面會有 PBEvent 的對象,PBEvent 其實是一條條的 Protobuf 的記錄。數據從 Source 流到的 Parser 模塊,解析后會形成 PBEvent,PBEvent 會將用戶在平臺錄入的整個 Schema 模型,存儲在 OSS 對象系統上,Exporter 模塊會動態去加載模型的變更。然后通過 pb 文件去反射生成的具體事件對象,事件對象最后就可以映射落成 parquet 的格式。這里主要做了很多緩存反射的優化,使整個 pb 的動態解析性能達到六倍的提升。最后,我們會將數據會落地到 HDFS,形成 parquet 的格式。
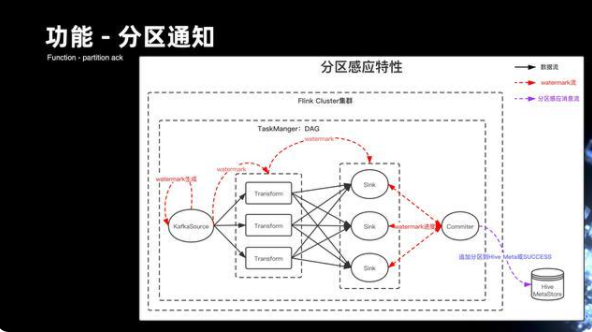
6.2 分區通知優化
前面提到管道會處理上百條流,早期 Flume 的架構,其實每個 Flume 節點,很難去感應它自己處理的進度。同時,Flume 也沒辦法做到全局進度的處理。但是基于 Flink,就可以通過 Watermark 的機制來解決。
首先在 Source 會基于消息當中的 Eventime 來生成 Watermark,Watermark 會經過每一層的處理傳遞到 Sink,最后會通過 Commiter 模塊,以單線程的方式來匯總所有 Watermark 消息的進度。當它發現全局 Watermark 已經推進到下個小時的分區的時候,它會下發一條消息到 Hive MetStore,或者是寫入到 Kafka, 來通知上小時分區數據 ready,從而可以讓下游的調度可以更快的通過消息驅動的方式來拉起作業的運行。
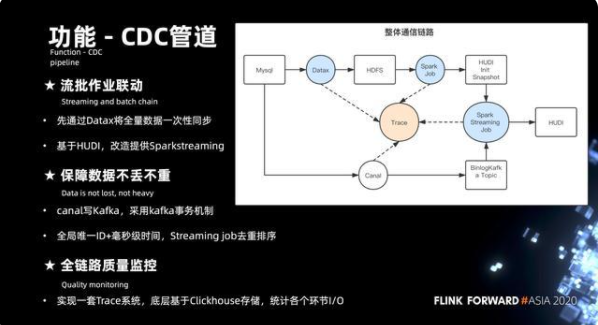
6.3 CDC管道上的優化
下圖右側其實是整個 cdc 管道完整的鏈路。要實現 MySQL 數據到 Hive 數據的完整映射,就需要解決流和批處理的問題。
首先是通過 Datax 將 MySQL 的數據全量一次性同步到的 HDFS。緊接著通過 spark 的 job,將數據初始化成 HUDI 的初始快照,接著通過 Canal 來實現將 Mysql 的 binlog 的數據拖到的 Kafka 的 topic,然后是通過 Flink 的 Job 將初始化快照的數據結合增量的數據進行增量更新,最后形成 HUDI 表。
整個鏈路是要解決數據的不丟不重,重點是針對 Canal 寫 Kafka 這塊,開了事務的機制,保證數據落 Kafka topic 的時候,可以做到數據在傳輸過程當中的不丟不重。另外,數據在傳輸的上層其實也有可能出現數據的重復和丟失,這時候更多是通過全局唯一 id 加毫秒級的時間戳。在整個流式 Job 中,針對全局 id 來做數據的去重,針對毫秒級時間來做數據的排序,這樣能保證數據能夠有序的更新到的 HUDI。
緊接著通過 Trace 的系統基于 Clickhouse 來做存儲,來統計各個節點數據的進出條數來做到數據的精確對比。
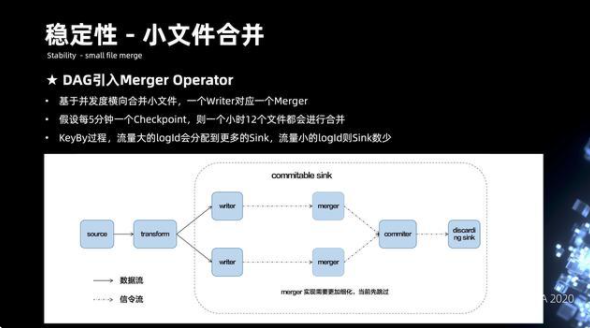
6.4 穩定性 - 小文件的合并
前面提到,改造成 Flink 之后,我們是做了每分鐘的 Checkpoint,文件數的放大非常嚴重。主要是在整個 DAG 當中去引入 merge 的 operater 來實現文件的合并,merge 的合并方式主要是基于并發度橫向合并,一個 writer 會對應一個 merge。這樣每五分鐘的 Checkpoint,1 小時的 12 個文件,都會進行合并。通過種方式的話,可以將文件數極大的控制在合理的范圍內。
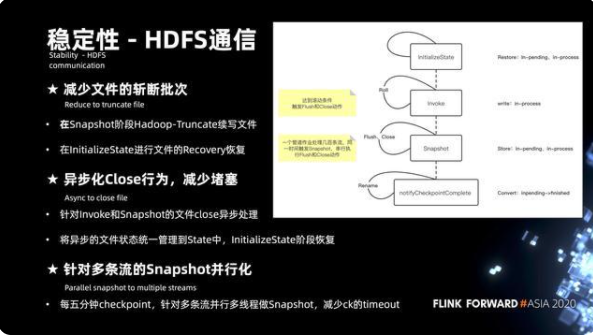
6.5 HDFS 通信
實際運作過程當中經常會遇到整個作業堆積比較嚴重的問題,實際分析其實主是和 HDFS 通信有很大的關系。
其實 HDFS 通訊,梳理了四個關鍵的步驟:初始化 state、Invoke、Snapshot 以及 Notify Checkpoint complete。
核心問題主要發生在 Invoke 階段,Invoke 會達到文件的滾動條件,這時候會觸發 flush 和 close。close 實際和 NameNode 通信的時候,會經常出現堵塞的情況。
Snapshot 階段同樣會遇到一個問題,一個管道上百條流一旦觸發 Snapshot,串行執行 flush 和 close 也會非常的慢。
核心優化集中在三個方面:
第一,減少了文件的斬斷,也就是 close 的頻次。在 Snapshot 階段,不會去 close 關閉文件,而更多的是通過文件續寫的方式。這樣,在初始化 state 的階段,就需要做文件的 Truncate 來做 Recovery 恢復。第二,是異步化 close 的改進,可以說是 close 的動作不會去堵塞整個總鏈路的處理,針對 Invoke 和 Snapshot 的 close,會將狀態管理到 state 當中,通過初始化 state 來進行文件的恢復。第三,針對多條流,Snapshot 還做了并行化的處理,每 5 分鐘的 Checkpoint, 多條流其實就是多個 bucket,會通過循環來進行串行的處理,那么通過多線程的方式來改造,就可以減少 Checkpoint timeout 的發生。
6.6 分區容錯的一些優化
實際在管道多條流的情況下,有些流的數據并不是每個小時都是連續的。
這種情況會帶來分區,它的 Watermark 沒有辦法正常推進,引發空分區的問題。所以我們在管道的運行過程當中,引入 PartitionRecover 模塊,它會根據 Watermark 來推進分區的通知。針對有些流的 Watermark,如果在 ideltimeout 還沒有更新的情況下,Recover 模塊來進行分區的追加。它會在每個分區的末尾到達的時候,加上 delay time 來掃描所有流的 Watermark,由此來進行兜底。
在傳輸過程當中,當 Flink 作業重啟的時候,會遇到一波僵尸的文件,我們是通過在 DAG 的 commit 的節點,去做整個分區通知前的僵尸文件的清理刪除,來實現整個僵尸文件的清理,這些都屬于非功能性層面的一些優化。

三、Flink 和 AI 方向的一些工程實踐
1. 架構演進時間表
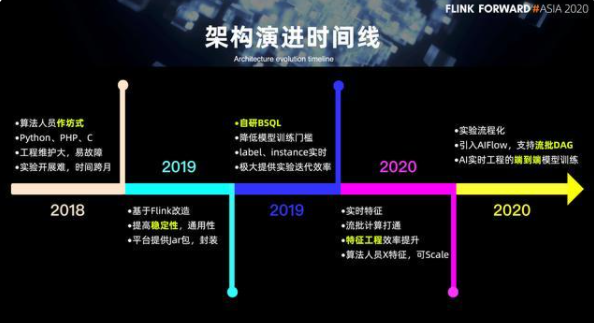
下圖是 AI 方向在實時架構完整的時間線。
早在 2018 年,很多算法人員的實驗開發都是作坊式的。每個算法人員會根據自己熟悉的語言,比如說 Python,php 或 c++ 來選擇不同的語言來開發不同的實驗工程。它的維護成本非常大,而且容易出現故障;2019 年上半年,主要是基于 Flink 提供了 jar 包的模式來面向整個算法做一些工程的支持,可以說在整個上半年的初期,其實更多是圍繞穩定性,通用性來做一些支持;2019 年的下半年,是通過自研的 BSQL,大大降低了模型訓練的門檻,解決 label 以及 instance 的實時化來提高整個實驗迭代的效率;2020 年上半年,更多是圍繞整個特征的計算,流批計算打通以及特征工程效率的提升,來做一些改進;到2020 年的下半年,更多是圍繞整個實驗的流程化以及引入 AIFlow,方便的去做流批 DAG。
2. AI 工程架構回顧
回顧一下整個 AI 工程,它的早期的架構圖其實體現的是整個 AI 在 2019 年初的架構視圖,其本質是通過一些 single task 的方式,各種混合語言來組成的一些計算節點,來支撐著整個模型訓練的鏈路拉起。經過 2019 年的迭代,將整個近線的訓練完全的替換成用 BSQL 的模式來進行開發和迭代。

3. 現狀痛點
在 2019 年底,其實又遇到了一些新的問題,這些問題主要集中在功能和非功能兩個維度上。
在功能層面:首先從 label 轉到產生 instance 流,以及到模型訓練,到線上預測,乃至真正的實驗效果,整個鏈路非常的長且復雜;第二,整個實時的特征、離線特征、以及流批的一體,涉及到非常多的作業組成,整個鏈路很復雜。同時實驗和 online 都要做特征的計算,結果不一致會導致最終的效果出現問題。此外,特征存在哪里也不好找,沒辦法去追溯。

在非功能性層面,算法的同學經常會遇到,不知道 Checkpoint 是什么,要不要開,有啥配置。此外,線上出問題的時候也不好排查,整個鏈路都非常的長。所以第三點就是,完整的實驗進度需要涉及的資源是非常多的,但是對算法來說它根本就不知道這些資源是什么以及需要多少,這些問題其實都都對算法產生很大的困惑。
4. 痛點歸結
歸根結底,集中在三個方面:
第一是一致性的問題。從數據的預處理,到模型訓練,再到預測,各個環節其實是斷層的。當中包括數據的不一致,也包括計算邏輯的不一致;第二,整個實驗迭代非常慢。一個完整的實驗鏈路,其實對算法同學來說,他需要掌握東西非常多。同時實驗背后的物料沒辦法進行共享。比如說有些特征,每個實驗背后都要重復開發;第三,是運維和管控的成本比較高。
完整的實驗鏈路,背后其實是包含實時的一條工程加離線的一條工程鏈路組成,線上的問題很難去排查。

5. 實時 AI 工程的雛形
在這樣的一些痛點下,在 20 年主要是集中在 AI 方向上去打造實時工程的雛形。核心是通過下面三個方面來進行突破。
第一是在 BSQL 的一些能力上,對于算法,希望通過面向 SQL 來開發以此降低工程投入;第二是特征工程,會通過核心解決特征計算的一些問題來滿足特征的一些支持;第三是整個實驗的協作,算法的目的其實在于實驗,希望去打造一套端到端的實驗協作,最終希望做到面向算法能夠“一鍵實驗”。

6. 特征工程-難點
我們在特征工程中遇到了一些難點。
第一是在實時特征計算上,因為它需要將結果利用到整個線上的預測服務,所以它對延遲以及穩定性的要求都非常的高;第二是整個實時和離線的計算邏輯一致,我們經常遇到一個實時特征,它需要去回溯過去 30 天到到 60 天的離線數據,怎么做到實時特征的計算邏輯能同樣在離線特征的計算上去復用;第三是整個離線特征的流批一體比較難打通。實時特征的計算邏輯經常會帶有窗口時序等等一些流式的概念,但是離線特征是沒有這些語義的。

7. 實時特征
這里看一下我們怎么去做實時特征,圖中的右側是最典型的一些場景。比如說我要實時統計用戶最近一分鐘、6 小時、12 小時、24 小時,對各個 UP 主相關視頻的播放次數。針對這樣場景,其實里面有兩個點:
第一、它需要用到滑動窗口來做整個用戶過去歷史的計算。此外,數據在滑動計算過程當中,它還需要去關聯 UP 主的一些基礎的信息維表,來獲取 UP 主的一些視頻來統計他的播放次數。歸根結底,其實遇到了兩個比較大的痛。用 Flink 原生的滑動窗口,分鐘級的滑動,會導致窗口比較多,性能會損耗比較大。同時細粒度的窗口也會導致定時器過多,清理效率比較差。第二是維表查詢,會遇到是多個 key 要去查詢 HBASE 的多個對應的 value,這種情況需要去支持數組的并發查詢。
在兩個痛點下,針對滑動窗口,主要是改造成為 Group By 的模式,加上 agg 的 UDF 的模式,將整個一小時、六小時、十二小時、二十四小時的一些窗口數據,存放到整個 Rocksdb 當中。這樣通過 UDF 模式,整個數據觸發機制就可以基于 Group By 實現記錄級的觸發,整個語義、時效性都會提升的比較大。同時在整個 AGG 的 UDF 函數當中,通過 Rocksdb 來做 state,在 UDF 當中來維護數據的生命周期。此外還擴展了整個 SQL 實現了數組級別的維表查詢。最后的整個效果其實可以在實時特征的方向上,通過超大窗口的模式來支持各種計算場景。

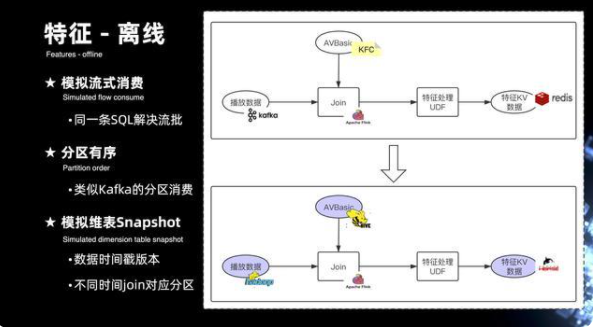
8. 特征-離線
接下來看一下離線,左側視圖上半部分是完整的實時特征的計算鏈路,可以看出要解決同樣的一條 SQL,在離線的計算上也能夠復用,那就需要去解決相應的一些計算的 IO 都能夠復用的問題。比如在流式上是通過 Kafka 來進行數據的輸入,在離線上需要通過 HDFS 來做數據的輸入。在流式上是通過 KFC 或者 AVBase 等等的一些 kv 引擎來支持,在離線上就需要通過 hive 引擎來解決,歸根結底,其實需要去解決三個方面的問題:
第一,需要去模擬整個流式消費的能力,能夠支持在離線的場景下去消費 HDFS 數據;第二,需要解決 HDFS 數據在消費過程當中的分區有序的問題,類似 Kafka 的分區消費;第三,需要去模擬 kv 引擎維表化的消費,實現基于 hive 的維表消費。還需要解決一個問題,當從 HDFS 拉取的每一條記錄,每一條記錄其實消費 hive 表的時候都有對應的 Snapshot,就相當于是每一條數據的時間戳,要消費對應數據時間戳的分區。
9. 優化
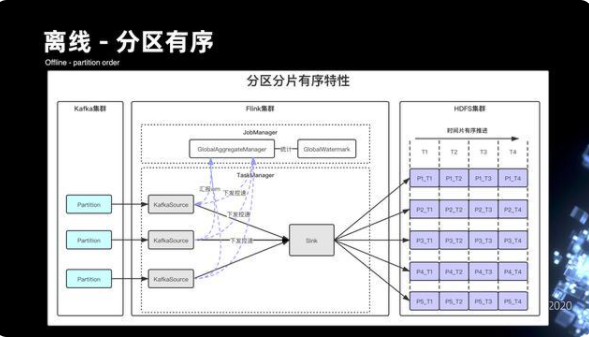
9.1 離線-分區有序
分區有序的方案其實主要是基于數據在落 HDFS 時候,前置做了一些改造。首先數據在落 HDFS 之前,是傳輸的管道,通過 Kafka 消費數據。在 Flink 的作業從 Kafka 拉取數據之后,通過 Eventtime 去提取數據的 watermark,每一個 Kafka Source 的并發度會將 watermark 匯報到 JobManager 當中的 GlobalWatermark 模塊,GlobalAgg 會匯總來自每一個并發度 Watermark 推進的進度,從而去統計 GlobalWatermark 的進展。根據 GlobalWatermark 的進展來計算出當中有哪些并發度的 Watermark 計算過快的問題,從而通過 GlobalAgg 下發給 Kafka Source 控制信息,Kafka Source 有些并發度過快的情況下,它的整個分區推進就降低速度。這樣,在 HDFS Sink 模塊,在同時間片上收到的數據記錄的整個 Event time 基本上有序的,最終落到 HDFS 還會在文件名上去標識它相應的分區以及相應的時間片范圍。最后在 HDFS 分區目錄下,就可以實現數據分區的有序目錄。
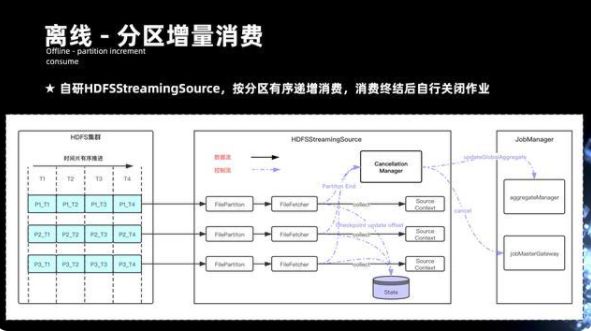
9.2 離線-分區增量消費
數據在 HDFS 增量有序之后,實現了 HDFStreamingSource,它會針對文件做 Fecher 分區,針對每個文件都有 Fecher 的線程,且每個 Fecher 線程會統計每一個文件。它 offset 處理了游標的進度,會將狀態根據 Checkpoint 的過程,將它更新到的 State 當中。
這樣就可以實現整個文件消費的有序推進。在回溯歷史數據的時候,離線作業就會涉及到整個作業的停止。實際是在整個 FileFetcher 的模塊當中去引入一個分區結束的標識,且會在每一個線程去統計每一個分區的時候,去感應它分區的結束,分區結束后的狀態最后匯總到的 cancellationManager,并進一步會匯總到 Job Manager 去更新全局分區的進度,當全局所有的分區都到了末尾的游標時候,會將整個 Flink 作業進行 cancel 關閉掉。
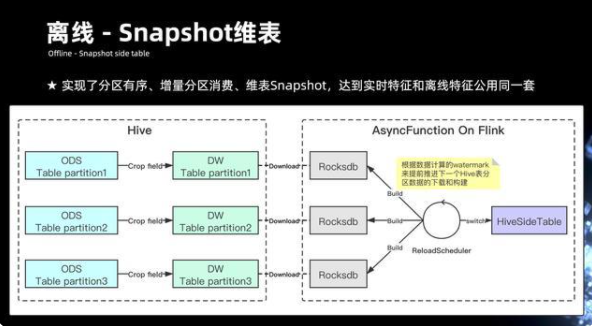
9.3 離線 - Snapshot 維表
前面講到整個離線數據,其實數據都在 hive 上,hive 的 HDFS 表數據的整個表字段信息會非常的多,但實際做離線特征的時候,需要的信息其實是很少的,因此需要在 hive 的過程先做離線字段裁剪,將一張 ODS 的表清洗成 DW 的表,DW 的表會最后通過 Flink 運行 Job,內部會有個 reload 的 scheduler,它會定期的去根據數據當前推進的 Watermark 的分區,去拉取在 hive 當中每一個分區對應的表信息。通過去下載某 HDFS 的 hive 目錄當中的一些數據,最后會在整個內存當中 reload 成 Rocksdb 的文件,Rocksdb 其實就是最后用來提供維表 KV 查詢的組件。
組件里面會包含多個 Rocksdb 的 build 構建過程,主要是取決于整個數據流動的過程當中的 Eventtime,如果發現 Eventtime 推進已經快到小時分區結束的末尾時候,會通過懶加載的模式去主動 reload,構建下一個小時 Rocksdb 的分區,通過這種方式,來切換整個 Rocksdb 的讀取。
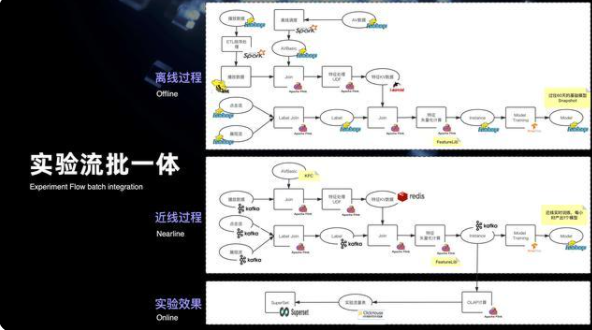
10. 實驗流批一體
在上面三個優化,也就是分區有序增量,類 Kafka 分區 Fetch 消費,以及維表 Snapshot 的基礎下,最終是實現了實時特征和離線特征,共用一套 SQL 的方案,打通了特征的流批計算。緊接著來看一下整個實驗,完整的流批一體的鏈路,從圖中可以看出最上面的粒度是整個離線的完整的計算過程。第二是整個近線的過程,離線過程其實所用計算的語義都是和近線過程用實時消費的語義是完全一致的,都是用 Flink 來提供 SQL 計算的。
來看一下近線,其實 Label join 用的是 Kafka 的一條點擊流以及展現流,到了整個離線的計算鏈路,則用的一條 HDFS 點擊的目錄和 HDFS 展現目錄。特征數據處理也是一樣的,實時用的是 Kafka 的播放數據,以及 Hbase 的一些稿件數據。對于離線來說,用的是 hive 的稿件數據,以及 hive 的播放數據。除了整個離線和近線的流批打通,還將整個近線產生的實時的數據效果匯總到 OLAP 引擎上,通過 superset 來提供整個實時的指標可視化。其實從圖可以看出完整的復雜流批一體的計算鏈路,當中包含的計算節點是非常的復雜和龐多的。
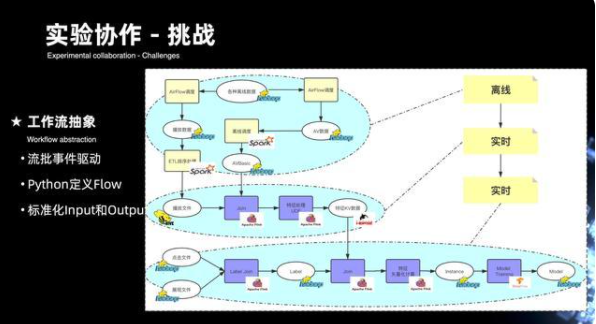
11. 實驗協作 - 挑戰
下階段挑戰更多是在實驗協作上,下圖是將前面整個鏈路進行簡化后的抽象。從圖中可以看出,三個虛線的區域框內,分別是離線的鏈路加兩個實時的鏈路,三個完整的鏈路構成作業的流批,實際上就是一個工作流最基本的過程。里面需要去完成工作流完整的抽象,包括了流批事件的驅動機制,以及,對于算法在 AI 領域上更多希望用 Python 來定義完整的 flow,此外還將整個輸入,輸出以及它的整個計算趨于模板化,這樣可以做到方便整個實驗的克隆。
12. 引入 AIFlow
整個工作流上在下半年更多是和社區合作,引入了 AIFlow 的整套方案。
右側其實是整個 AIFlow 完整鏈路的DAG視圖,可以看出整個節點,其實它支持的類型是沒有任何限制的,可以是流式節點,也可以是離線節點。此外的話,整個節點與節點之間通信的邊是可以支持數據驅動以及事件驅動的。引入 AIFlow 的好處主要在于,AIFlow 提供基于 Python 語義來方便去定義完整的 AIFlow 的工作流,同時還包括整個工作流的進度的調度。
在節點的邊上,相比原生的業界的一些 Flow 方案,他還支持基于事件驅動的整個機制。好處是可以幫助在兩個 Flink 作業之間,通過 Flink 當中 watermark 處理數據分區的進度去下發一條事件驅動的消息來拉起下一個離線或者實時的作業。
此外還支持周邊的一些配套服務,包括通知的一些消息模塊服務,還有元數據的服務,以及在 AI 領域一些模型中心的服務。
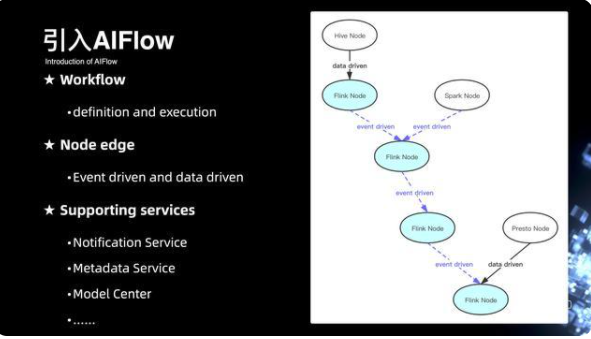
13. Python 定義 Flow
來看一下基于 AIFlow 是如何最終定義成 Python 的工作流。右邊的視圖是一個線上項目的完整工作流的定義。第一、是整個是 Spark job 的定義,當中通過配置 dependence 來描述整個下游的依賴關系,它會下發一條事件驅動的消息來拉起下面的 Flink 流式作業。流式作業也同樣可以通過消息驅動的方式來拉起下面的 Spark 作業。整個語義的定義非常的簡單,只需要四個步驟,配置每節點的 confg 的信息,以及定義每節點的 operation 的行為,還有它的 dependency 的依賴,最后去運行整個 flow 的拓撲視圖。

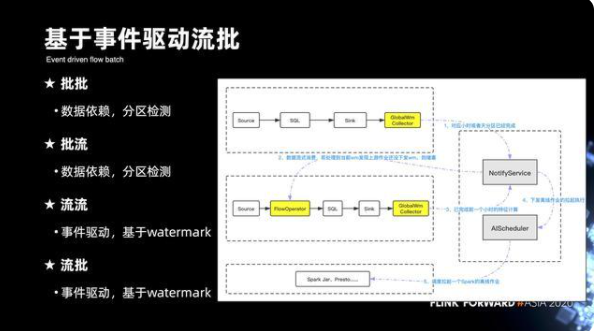
14. 基于事件驅動流批
接下來看一下完整的流批調度的驅動機制,下圖右側是完整的三個工作節點的驅動視圖。第一個是從 Source 到 SQL 到 Sink。引入的黃色方框是擴展的 supervisor,他可以收集全局的 watermark 進度。當整個流式作業發現 watermark 可以推進到下一個小時的分區的時候,它會下發一條消息,去給到 NotifyService。NotifyService 拿到這條消息之后,它會去下發給到下一個作業,下一個作業主要會在整個 Flink 的 DAG 當中去引入 flow 的 operator,operator 在沒有收到上個作業下發了消息之前,它會堵塞整個作業的運行。直到收到消息驅動之后,就代表上游其實上一個小時分區已經完成了,這時下個 flow 節點就可以驅動拉起來運作。同樣,下個工作流節點也引入了 GlobalWatermark Collector 的模塊來匯總收集它的處理的進度。當上一個小時分區完成之后,它也會下發一條消息到 NotifyService,NotifyService 會將這條消息去驅動調用 AIScheduler 的模塊,從而去拉起 spark 離線作業來做 spark 離線的收尾。從里你們可以看出,整個鏈路其實是支持批到批,批到流以及流到流,以及流到批的四個場景。
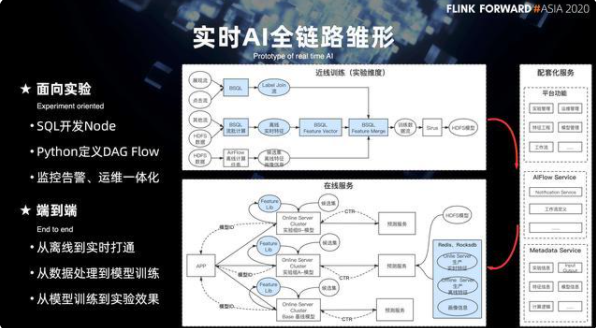
15. 實時 AI 全鏈路的雛形
在流和批的整個 flow 定義和調度的基礎上,在 2020 年初步構建出來了實時 AI 全鏈路的雛形,核心是面向實驗。算法同學也可以基于 SQL 來開發的 Node 的節點,Python 是可以定義完整的 DAG 工作流。監控,告警以及運維是一體化的。
同時,支持從離線到實時的打通,從數據處理到模型訓練,從模型訓練到實驗效果的打通,以及面向端到端的打通。右側是整個近線實驗的鏈路。下面是將整個實驗鏈路產出的物料數據提供給在線的預測訓練的服務。整體會有三個方面的配套:
一是基礎的一些平臺功能,包括實驗管理,模型管理,特征管理等等;其次也包括整個 AIFlow 底層的一些 service 的服務;再有是一些平臺級的 metadata 的元數據服務。
四、未來的一些展望
在未來的一年,我們還會更加集中在兩個方面的一些工作。
第一是數據湖的方向上,會集中在 ODS 到 DW 層的一些增量計算場景,以及 DW 到 ADS 層的一些場景的突破,核心會結合 Flink 加 Iceberg 以及 HUDI 來作為該方向的落地。在實時 AI 平臺上,會進一步去面向實驗來提供一套實時的 AI 協作平臺,核心是希望打造高效,能夠提煉簡化算法人員的工程平臺。