Hologres 揭秘:高性能原生加速 MaxCompute 核心原理
Hologres(中文名交互式分析)是阿里云自研的一站式實時數倉,這個云原生系統融合了實時服務和分析大數據的場景,全面兼容PostgreSQL協議并與大數據生態無縫打通,能用同一套數據架構同時支持實時寫入實時查詢以及實時離線聯邦分析。它的出現簡化了業務的架構,與此同時為業務提供實時決策的能力,讓大數據發揮出更大的商業價值。從阿里集團誕生到云上商業化,隨著業務的發展和技術的演進,Hologres也在持續不斷優化核心技術競爭力,為了讓大家更加了解Hologres,我們計劃持續推出Hologres底層技術原理揭秘系列,從高性能存儲引擎到高效率查詢引擎,高吞吐寫入到高QPS查詢等,全方位解讀Hologres,請大家持續關注!
本期我們將帶來Hologres高性能原生加速查詢MaxCompute的技術原理解析。
隨著數據收集手段不斷豐富,行業數據大量積累,數據規模已增長到了傳統軟件行業無法承載的海量數據(TB、PB、EB)級別,MaxCompute(原名ODPS)也因此應運而生,致力于批量結構化數據的存儲和計算,提供海量數據倉庫的解決方案及分析建模服務,是一種快速、完全托管的EB級數據倉庫解決方案。
Hologres在離線大數據場景上與MaxCompute天然無縫融合,無需數據導入導出就能實現加速查詢MaxCompute,全兼容訪問各種MaxCompute文件格式,實現對PB級離線數據的毫秒級交互式分析。而這一切的背后,都離不開Hologres背后的執行器SQE(S Query Engine),通過SQE實現對MaxCompute的Native訪問,然后再結合Hologres高性能分布式執行引擎HQE的處理,達到極致性能。
Hologres加速查詢MaxCompute主要有以下幾個優勢:
高性能:可以直接對MaxCompute數據加速查詢,具有亞秒級響應的查詢性能,在OLAP場景可以直接即席查詢,滿足絕大多數報表等分析場景。
低成本:MaxCompute經過數年的發展,用戶在MaxCompute上存儲了大量數據,不需要冗余一份存儲可直接進行訪問;另一方面用戶可以只需將部分高性能場景的數據遷移到SSD上,報表等分析場景的數據可以存儲在MaxCompute進一步降低成本。
更高效:實現對MaxCompute的Native訪問,無需遷移和導入數據,就可以高性能和全兼容的訪問各種MaxCompute文件格式,以及Hash/Range Clustered Table等復雜表,降低用戶的使用成本。
SQE 架構介紹
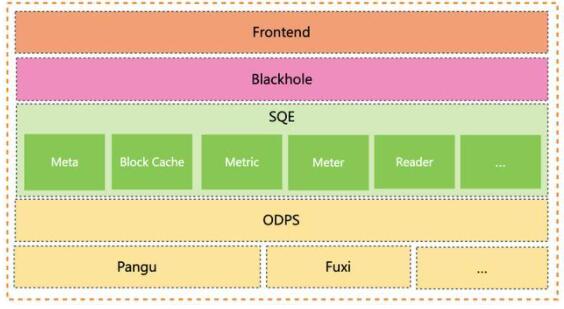
如上圖所示是SQE的整體架構,可以看出整個架構也是非常簡單。MaxCompute的數據統一存儲在Pangu,當Hologres執行一條Query去加速查詢MaxCompute的數據時,在Hologres端:
Hologres Frontend通過RPC向SQE Master請求獲取Meta等相關信息。
Hologres Blackhole 通過 RPC 向 SQE Executor 請求獲取具體的數據相關信息。
SQE由兩種角色的進程組成:
SQE Master負責處理Meta相關的請求,主要負責獲取表、分區元數據、鑒權以及文件分片等功能。
SQE Executor作為SQE的核心,負責具體讀取數據請求,涉及Block Cache、預讀取、UDF 處理、表達式下推處理、索引處理、Metric、Meter等等功能。
MaxCompute外表引擎核心技術創新
基于SQE的架構,能做到對MaxCompute的數據高性能加速查詢,主要是基于以下技術創新優勢:
1)抽象分布式外表
結合MaxCompute的分布式特性,Hologres抽象了一個分布式的外表,來支持訪問MaxCompute分布式數據。目前可支持訪問跨集群的MaxCompute分布式盤古文件,并按MaxCompute計算集群就近讀取。
2)和 MaxCompute Meta無縫互通,支持帶版本的元數據緩存
SQE和MaxCompute 的 Meta 無縫互通,可以做到 Meta 和 Data 實時獲取,支持通過Import Foreign Schema命令,自動同步MaxCompute的元數據到Hologres的外表,實現外表的自動創建,結構自動更新。
3)支持UDF/表達式下推
SQE 通過支持 UDF/表達式下推,來實現用戶自定義的UDF計算;將表達式下推可以減少無用的數據傳輸帶來的開銷,進一步提升性能。
4)異步ORC Reader,異步prefetch
目前MaxCompute大部分數據為ORC格式,在Hologres V0.10及以上版本,Hologres更新了執行引擎,使用異步 Reader 進行更高效的異步讀取,還支持異步prefetch,進一步降低讀取延遲;此外Hologres支持了 IO 合并、LazyRead、Lazy Decoding 等一些列的優化技術手段,來降低在 IO 在整個查詢上的延遲,以帶來極致性能。
5)支持Block Cache
為了避免每次讀數據都用IO到文件中取,SQE同樣使用BlockCache把常用和最近用的數據放在內存中,減少不必要的IO,加快讀的性能。在同一個節點內,通過一致性Hash實現將相同訪問的數據共享一個Block Cache。 比如在Scan 場景可帶來2倍以上的性能提升,大大提升查詢性能。
6)常駐進程,減少調度開銷
傳統的進程模型等架構需要動態實時的創建進程等調度操作,帶來了較大的調度開銷。SQE 采用常駐進程模式,避免不必要的調度開銷,此外還可以大大提升Block Cache的命中率和有效使用率。
7)Network Shuffle,減少落盤開銷
Network Shuffle需要提供一種快速且穩定的容錯機制。由于Network Shuffle必須保證發送端和接收端進程同時alive才能完成數據shuffle。同樣的,如果采用傳統落盤的方式來進行Network Shuffle的Retry,雖然能夠保證穩定性,但是可能會在Retry過程中由于磁盤IO引入比較大的性能overhead。為了解決這個問題,我們優化了分階段調度來解決快速穩定的容錯問題。
MaxCompute外表引擎升級到HQE
上面提到了我們通過SQE進行加速查詢MaxCompute外表,通過SQE查詢時性能可以做到很好,但是和Hologres交互時中間會有一層RPC 交互,在數據量較大時網絡會存在一定瓶頸。
因此我們基于Hologres已有的能力,在Hologres V0.10及以上版本我們對執行引擎進行了優化,支持Hologres HQE查詢引擎直讀MaxCompute 表,在性能上得到進一步的提升,較SQE方式讀取有 30%以上的性能提升。
這主要得益于以下幾個方面:
1) 節省了 SQE 和 Hologres中間 RPC 的交互,相當于節省一次數據的序列化和反序列化,在性能上得到進一步的提升。
2) 可以復用Hologres的Block Cache,這樣第二次查詢時無需訪問存儲,避免存儲IO,直接從內存訪問數據,更好的加速查詢。
3) 可以復用已有的Filter 下推能力,減少需要處理的數據量。
4) 在底層的IO層實現了預讀和Cache,更進一步加速Scan時的性能。
以下是某客戶某實際在線業務查詢的性能數據:
執行817個SQL,總體性能提升70%,其中長 Query 提升80%以上。
說明:該優化目前已在Hologres V0.10上線,歡迎點擊查看文檔使用。
MaxCompute加速場景選擇
在Hologres中加速查詢MaxCompute有兩種方式:
1)創建外表(數據還是存儲在MaxCompute中),性能相比在MaxCompute中查詢會有2-5倍的提升
2)導入內表,性能相比外表約有10-100倍的提升
創建外表的方式其原理就是PostgreSQL中的Foreign Data Wrappers,通過外部訪問接口,來訪問存儲在外部的數據。建議您使用更方便的IMPORT FOREIGN SCHEMA 方式來創建外表,可以更好的簡化元數據的同步,無需關注字段類型映射等。
直接建外表并的方式實際上是利用查詢引擎的優化能力來提高效率的,但是沒有利用到Hologres的索引能力。所以當把外表導到內表的時候,可以根據查詢的方式指定內表的索引結構,通過這些索引能力帶來更高的查詢性能。這就是外表導入內表,內表的性能更好的原因,可以充分發揮數倉的索引優化能力。
目前這兩種方式主要對比如下:
從上面對比可以看出:
如果您是數據量很大、對性能有很高的要求時(比如100ms內等),對查詢延遲敏感,對查詢有SLA要求時,建議您將數據導入Hologres內表,進行查詢訪問。
如果是臨時性的探索性分析,或者對延遲不敏感的內部業務,可以使用MaxCompute外表方式,減少數據移動。
除上述場景外,您可以根據具體業務情況選擇合適的使用場景。
MaxCompute與Hologres的組合關系
上面介紹了很多Hologres外表查詢引擎如何加速查詢MaxCompute的場景,但并不是說所有類型的查詢都適合在Hologres的外表引擎上執行。
Hologres是針對交互式分析場景設計的同步的查詢引擎,面向的是大數據進,小數據出的場景,典型用在Serving和Analytics的場景。而MaxCompute是針對海量數據加工處理處理場景設計的異步的數據加工引擎,面向的是大數據進,大數據出的場景,典型用在ETL的場景。在ETL的場景,作業異步提交,IO接口針對Scan優化,計算過程需要節點的冗余設計支撐高可用,需要計算狀態落盤從而可以在失敗時自動重試,而這些都是Hologres不具備的能力。因此MaxCompute+Hologres組合在一起,形成了數據加工+服務的一站式體驗,減少了數據的隔離和冗余,可以為大數據數倉提供合理的解決方案架構,支撐實時離線一體化的開發體驗。
總結
Hologres通過SQE與MaxCompute深度整合,充分利用Hologres和MaxCompute的優勢,以極致性能為目標,直接就能加速查詢MaxCompute數據,讓用戶更方便高效的進行交互式分析,同時也降低了極大的分析成本,實現離線數倉服務一體化。