可觀察性:如何讓集成開發環境(IDE)進行調試
譯文
【51CTO.com快譯】新冠疫情為許多企業帶來了更大的推動力,以擴展云原生和分布式環境的運營。為了生存和發展,企業現在必須認真研究易于使用的云原生技術(例如API管理和集成解決方案、云原生產品、集成平臺即服務以及低代碼平臺),加快上市時間,并實現重復使用和共享。然而由于具有的分布式特性,這些云原生應用程序在管理方面更加復雜,并且隨著它們的擴展而增加。
將可觀察性構建到應用程序中允許企業的團隊自動收集和分析數據,以優化應用程序,并解決可能影響用戶的潛在問題。此外,它顯著減少了應用程序在運行時出現問題的調試時間。這使開發人員可以更多地專注于生產任務,例如開發新功能。
可觀察性具有三個關鍵組件:日志、度量、跟蹤。為了全面了解系統的行為,有必要收集這三個組件,而只有一兩個組件不足以調試應用程序的復雜行為。
本文將討論可觀察性的重要性,還將研究Choreo(用于云原生工程的集成平臺即服務)如何使開發人員能夠使用深度可觀察性功能來觀察應用程序的性能、識別異常和解決問題。
1.自動可觀察性
如果想在生產中收集日志、度量、跟蹤的數據而不影響應用程序性能,那么在應用程序中構建可觀察性需要付出巨大的努力。確保可觀察性對性能的影響達到最小是開發可觀察性框架時面臨的主要挑戰之一。如果要跟蹤所有請求,那么就會帶來很大的性能開銷。
為了使應用程序具有可觀察性,開發人員需要編寫性能優化的可觀察性代碼,并使用自適應采樣等算法,這些算法可以在不同的流量條件下動態控制性能開銷。不幸的是,許多應用程序開發人員沒有實現收集所有三個可觀察性支柱的代碼。
這有兩個原因:首先,許多開發人員不具備所需的專業知識水平。其次,所需的工作量很大,使其成為一項代價高昂的工作。
而將可觀察性集成到應用程序中需要多輪優化和廣泛的測試,以確保沒有顯著的性能開銷。
2.Choreo如何提供幫助
Choreo的設計方式使開發人員不必自己開發具有可觀察性的應用程序。Ballerina是Choreo的底層編程語言,具有強大的可觀察性框架,使用Ballerina編寫的程序可以實現完全的可觀察性。Choreo使用Ballerina的可觀察性框架為其服務收集可觀察性數據。
由于Ballerina的可觀察性框架經過精心設計以確保最小的性能開銷,因此Choreo應用程序可以在打開可觀察性的情況下在生產環境中運行。可觀察性數據以各種形式的可視化呈現給用戶。用戶可以使用這些可視化功能來優化應用程序,然后識別和解決可能對用戶體驗產生不利影響的問題。圖1顯示了Choreo應用程序的主要可觀察性頁面。

圖1 Choreo中的可觀察性的主頁
(1)使用平均值調試高響應時間
響應時間是一個關鍵的性能指標,對用戶體驗有著直接影響。高響應時間可能會導致用戶體驗不佳,從而導致用戶流失。不幸的是,開發人員在開發應用程序時并沒有過多關注應用程序的響應時間(延遲)。只有在生產中部署應用程序之后,他們才會發現此類問題。
即使在開發人員優化響應時間的情況下,工作負載條件也會隨時間變化,從而導致響應時間異常。Choreo在不同點收集應用程序的延遲,這使用戶能夠立即識別其代碼中的瓶頸。響應時間過長可能是由于代碼中的問題,或者可能與調用外部端點的延遲有關。而在Choreo中,開發人員可以識別并解決這些問題,而無需花費大量時間進行調試。圖2顯示了在Choreo中開發的應用程序的延遲細分情況。需要注意的是,不同的外部(連接器)調用將如何影響總延遲。
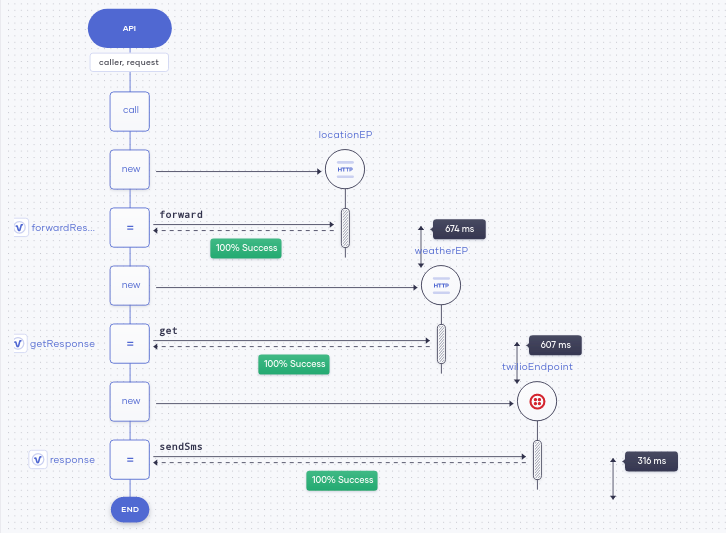
圖2在Choreo中開發的應用程序的延遲細分情況
(2)調試單個請求延遲
雖然可以使用指標調試某些延遲行為,但與延遲相關的更復雜問題無法使用圖2顯示的平均延遲值進行調試。此類問題的示例包括響應時間的逐漸增加、平均響應時間的突然下降或峰值(稱為水平偏移),以及在隨機時間點出現的延遲峰值等。
Choreo允許開發人員更精細地挖掘數據以檢測此類問題。例如,Choreo可觀察性收集的跟蹤數據允許開發人員通過調查單個請求的延遲細分來調試延遲峰值。圖3顯示了在Choreo中開發的應用程序的吞吐量和延遲行為。

圖3在Choreo中開發的應用程序的吞吐量和延遲行為
在此假設用戶了解特定請求的延遲。可以通過點擊圖表中的特定點來實現。當單擊一個點時,就可以獲得單個請求的延遲和延遲細分(Choeo顯示請求在請求路徑中花費時間最多的位置)。圖4對此進行了說明。
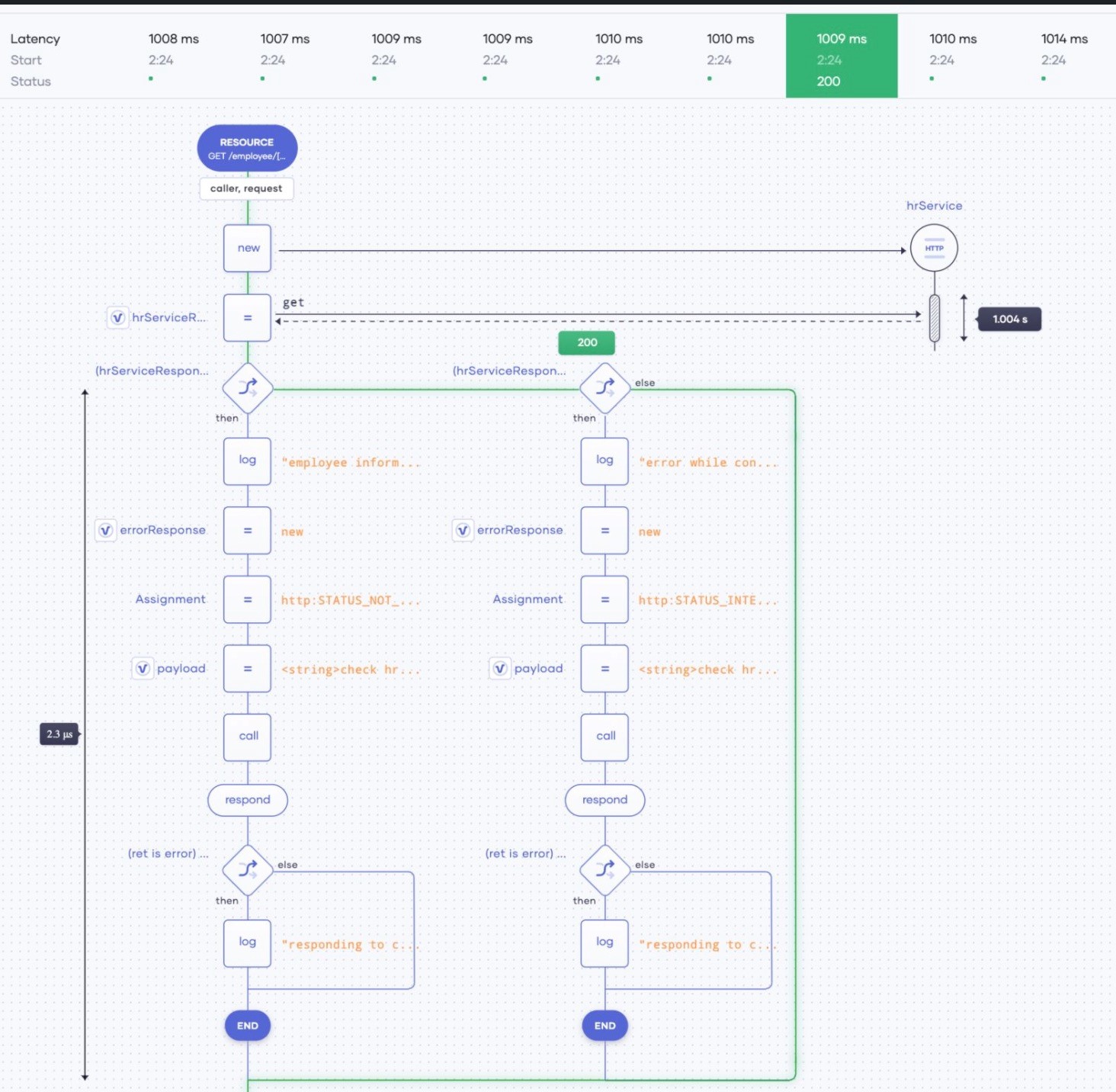
圖4 查看請求在請求路徑中花費時間最多的位置
(3)調試復雜問題
雖然可以通過分析延遲數據來解決大量問題(例如后端緩慢),但有些問題需要更詳細的分析。此類分析要求在統一視圖中查看多個指標和日志。這些指標包括系統指標(例如CPU和內存)和應用指標(例如吞吐量、延遲和錯誤率)。Choreo的診斷視圖有助于實現這一點。它允許開發人員深入和調試諸如高CPU使用率之類的行為,并將高CPU使用率與另一個性能指標的變化(例如延遲的增加)聯系起來。圖5顯示了Choreo可觀察性的診斷視圖。
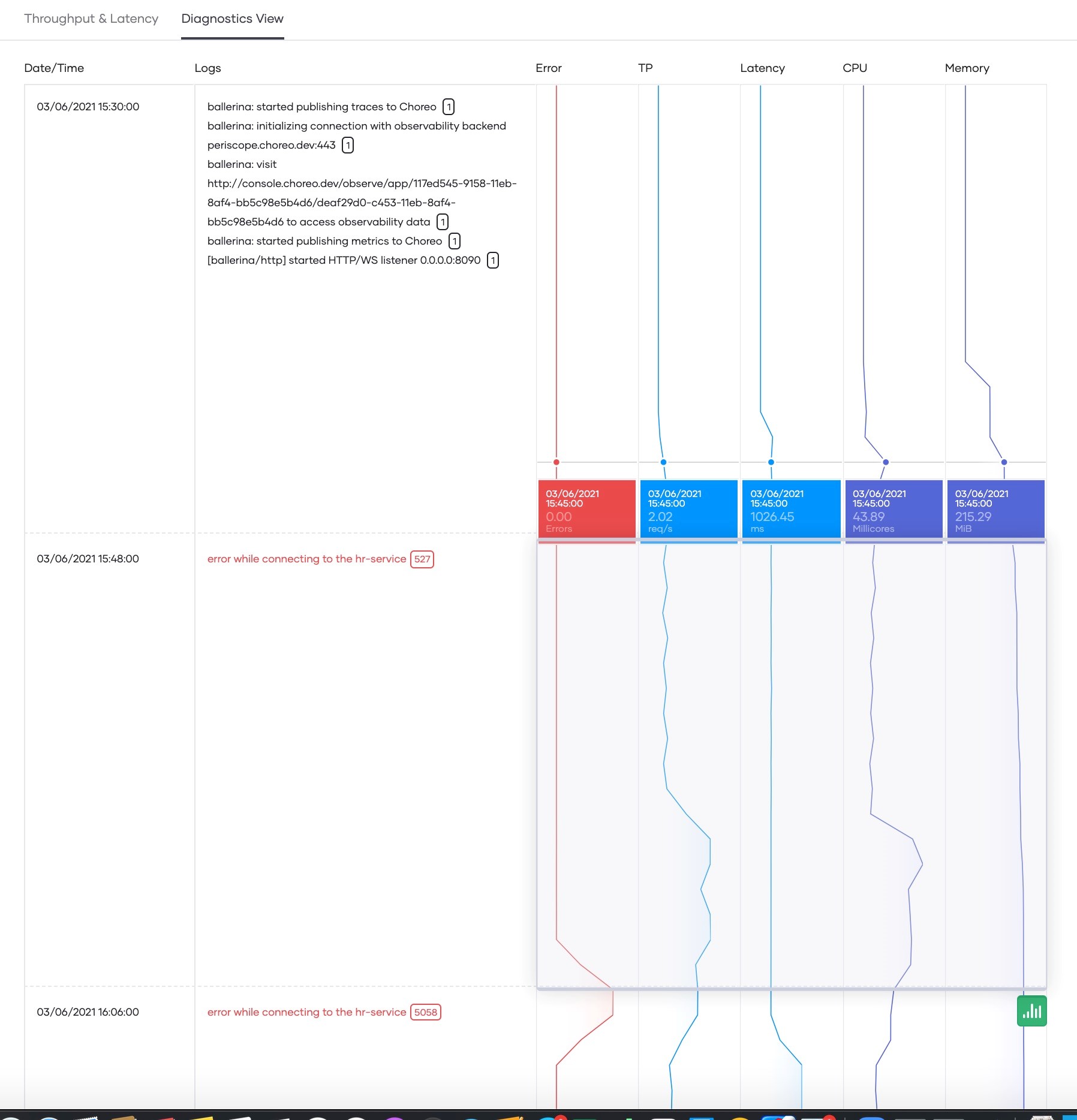
圖5 Choreo可觀察性的診斷視圖
(4)在配置較低環境中調試
由于引入新功能和錯誤修復等各種原因,開發人員經常需要編寫新代碼或修改現有代碼。在發生這種情況時,可能會將與性能相關的錯誤引入應用程序。Choreo允許在配置較低的環境中及早發現此類問題。開發人員可以在配置較低的環境中測試他們的應用程序,并將其性能行為與以前版本的性能行為進行比較。如果發現問題,可以在新版本部署到生產中之前解決這些問題。即使是全新的應用程序,開發者仍然可以通過提供示例的測試數據/案例在配置較低的環境中測試應用程序。
(5)性能異常警報
持續監控可觀察性儀表板以識別應用程序中的異常行為是不切實際的。因此,很多系統都有自動檢測性能異常并提醒相關方的方法。許多警報系統使用基于閾值的方法向用戶發送警報。例如,如果CPU利用率高于80%,則會生成并發出警報。基于閾值的方法具有已知的局限性。首先,它們在確定閾值時需要人工配置和專業知識。其次,基于閾值的方法由于無法檢測應用程序中的復雜異常模式而具有較低的準確性。
Choreo擁有復雜的異常檢測框架,該框架使用先進的機器學習和異常檢測算法來檢測Choreo用戶應用程序中的性能異常。它使用從以前的應用程序收集的可觀察性數據來訓練這些機器學習模型。
結語
雖然服務網格試圖通過收集服務可觀察性數據的Sidecar微服務提供可觀察性的解決方案,但默認情況下通過這些Sidecar收集的數據不足以執行云原生應用程序的深度調試。這種調試需要在服務內更細粒度的級別收集數據(例如,在服務內的不同點對特定請求的延遲進行細分)。
Choreo擁有一個強大的可觀察性框架,可以解決服務網格中的問題。Choreo還收集了其應用程序的所有三個可觀察性支柱,而對應用程序性能的影響最小。它以一種可以輕松調試和檢測應用程序性能異常的形式向用戶呈現這些數據。此外,Choreo擁有先進的基于機器學習的異常檢測技術,可以準確檢測Choreo應用程序的性能異常。
原文標題:Observability: Let Your IDE Debug for You,作者:Malith Jayasinghe
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】