













1.2萬億參數:谷歌通用稀疏語言模型GLaM,小樣本學習打敗GPT-3
近幾年,我們已經看到模型規模越來越大,例如 2018 年誕生的 GPT 具有 1.17 億參數,時隔一年,2019 年 GPT-2 參數量達到 15 億,2020 年更是將其擴展到 1750 億參數的 GPT-3。據了解,OpenAI 打造的超級計算機擁有 285000 個 CPU 核以及 10000 個 GPU,供 OpenAI 在上面訓練所有的 AI 模型。
大型語言模型雖然訓練昂貴,但也有其重要的一面,例如可以在各種任務中執行小樣本學習,包括閱讀理解、問答。雖然這些模型可以通過簡單地使用更多參數來獲得更好的性能。但是有沒有方法可以更有效地訓練和使用這些模型呢?
為了回答這個問題,谷歌推出了具有萬億權重的通用語言模型 (Generalist Language Model,GLaM),該模型的一大特點就是具有稀疏性,可以高效地進行訓練和服務(在計算和資源使用方面),并在多個小樣本學習任務上取得有競爭力的性能。
我們來看一下 GLaM 模型的具體情況。
數據集
谷歌首先構建了一個高質量的、具有 1.6 萬億 token 的數據集,該無標簽數據集很大一部分來自 Web 頁面,其范圍從專業寫作到低質量的評論和論壇頁面。此外,谷歌還開發了一個文本質量過濾器,該過濾器是在維基百科和書籍文本數據集上訓練而成,由于過濾器訓練的數據集質量很高,所以谷歌將其過濾 Web 網頁內容的質量。最后,谷歌應用這個過濾器來生成 Web 網頁的最終子集,并將其與書籍和維基百科數據相結合來創建最終的訓練數據集。
GLaM 模型架構
GLaM 是混合專家模型 (MoE) ,這種模型可以被認為具有不同的子模型(或專家),每個子模型都專門用于不同的輸入。每一層的專家由一個門控網絡控制,該門控網絡根據輸入數據激活專家。對于每個 token(通常是一個詞或詞的一部分),門控網絡選擇兩個最合適的專家來處理數據。完整的 GLaM 總共有 1.2T 參數,每個 MoE 包含 64 個專家,總共 32 個 MoE 層,但在推理期間,模型只會激活 97B 的參數,占總參數的 8%。
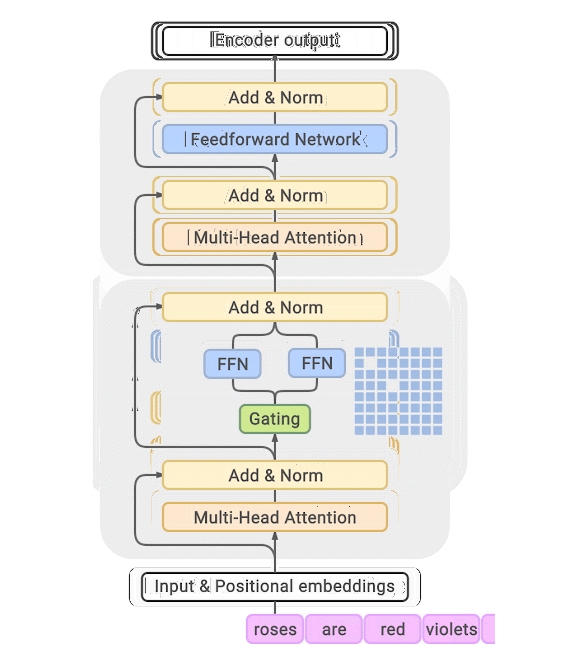
GLaM 的體系架構,每個輸入 token 都被動態路由到從 64 個專家網絡中選擇的兩個專家網絡中進行預測。
與 GShard MoE Transformer 類似,谷歌用 MoE 層替換其他 transformer 層的單個前饋網絡(人工神經網絡最簡單的一層,如上圖藍色方框中的 Feedforward 或 FFN)。MoE 層有多個專家,每個專家都是具有相同架構但不同權重參數的前饋網絡。
盡管 MoE 層有很多參數,但專家是稀疏激活的,這意味著對于給定的輸入 token,只使用兩個專家,這樣做的優勢是在限制計算的同時給模型提供更多的容量。在訓練期間,每個 MoE 層門控網絡都經過訓練,使用它的輸入來激活每個 token 的最佳兩位專家,然后將其用于推理。對于 MoE 層的 E 專家來說,這本質上提供了 E×(E-1) 個不同前饋網絡組合的集合,而不是經典 Transformer 中的一個組合,從而帶來更大的計算靈活性。
最終學習到的 token 表示來自兩個專家輸出的加權組合,這使得不同的專家可以激活不同類型的輸入。為了能夠擴展到更大的模型,GLaM 架構中的每個專家都可以跨越多個計算設備。谷歌使用 GSPMD 編譯器后端來解決擴展專家的挑戰,并訓練了多個變體(基于專家規模和專家數量)來了解稀疏激活語言模型的擴展效果。
評估設置
谷歌使用 zero-shot 和 one-shot 兩種設置,其中訓練中使用的是未見過的任務。評估基準包括如下:
- 完形填空和完成任務;
- 開放域問答;
- Winograd-style 任務;
- 常識推理;
- 上下文閱讀理解;
- SuperGLUE 任務;
- 自然語言推理。
谷歌一共使用了 8 項自然語言生成(NLG)任務,其中生成的短語基于真值目標進行評估(以 Exact Match 和 F1 measure 為指標),以及 21 項自然語言理解(NLU)任務,其中幾個 options 中的預測通過條件對數似然來選擇。
實驗結果
當每個 MoE 層只有一個專家時,GLaM 縮減為一個基于 Transformer 的基礎密集模型架構。在所有試驗中,谷歌使用「基礎密集模型大小 / 每個 MoE 層的專家數量」來描述 GLaM 模型。比如,1B/64E 表示是 1B 參數的密集模型架構,每隔一層由 64 個專家 MoE 層代替。
谷歌測試了 GLaM 的性能和擴展屬性,包括在相同數據集上訓練的基線密集模型。與最近微軟聯合英偉達推出的 Megatron-Turing 相比,GLaM 使用 5% margin 時在 7 項不同的任務上實現了不相上下的性能,同時推理過程中使用的算力減少了 4/5。
此外,在推理過程中使用算力更少的情況下,1.2T 參數的稀疏激活模型(GLaM)在更多任務上實現了比 1.75B 參數的密集 GPT-3 模型更好的平均結果。
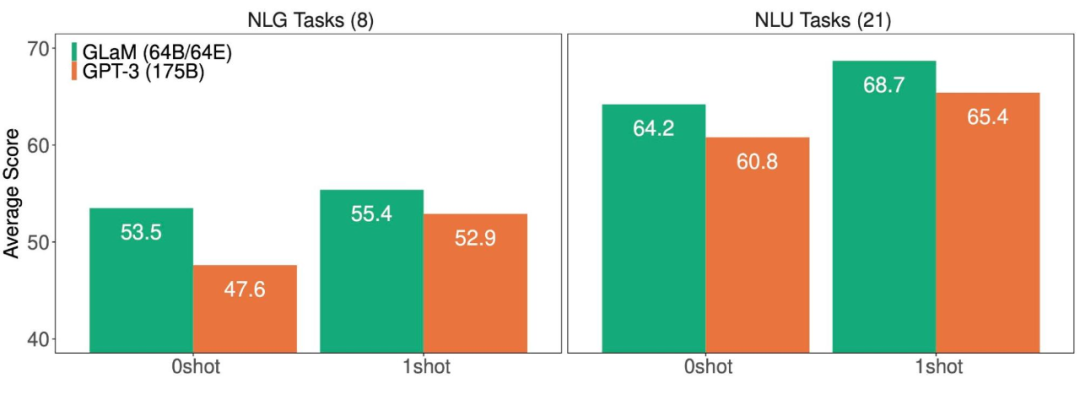
NLG(左)和 NLU(右)任務上,GLaM 和 GPT-3 的平均得分(越高越好)。
谷歌總結了 29 個基準上,GLaM 與 GPT-3 的性能比較結果。結果顯示,GLaM 在 80% 左右的 zero-shot 任務和 90% 左右的 one-shot 任務上超越或持平 GPT-3 的性能。
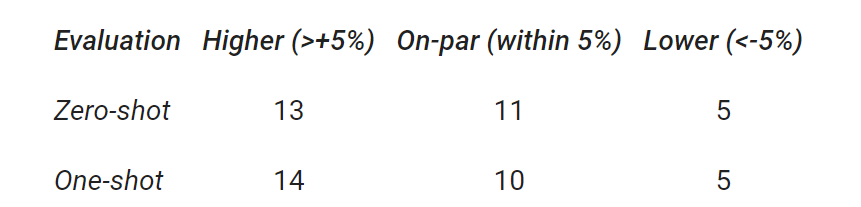
此外,雖然完整版 GLaM 有 1.2T 的總參數,但在推理過程中每個 token 僅激活 97B 參數(1.2T 的 8%)的子網。

擴展
GLaM 有兩種擴展方式:1) 擴展每層的專家數量,其中每個專家都托管在一個計算設備中;2) 擴展每個專家的大小以超出單個設備的限制。為了評估擴展屬性,該研究在推理時比較每個 token 的 FLOPS 相似的相應密集模型。
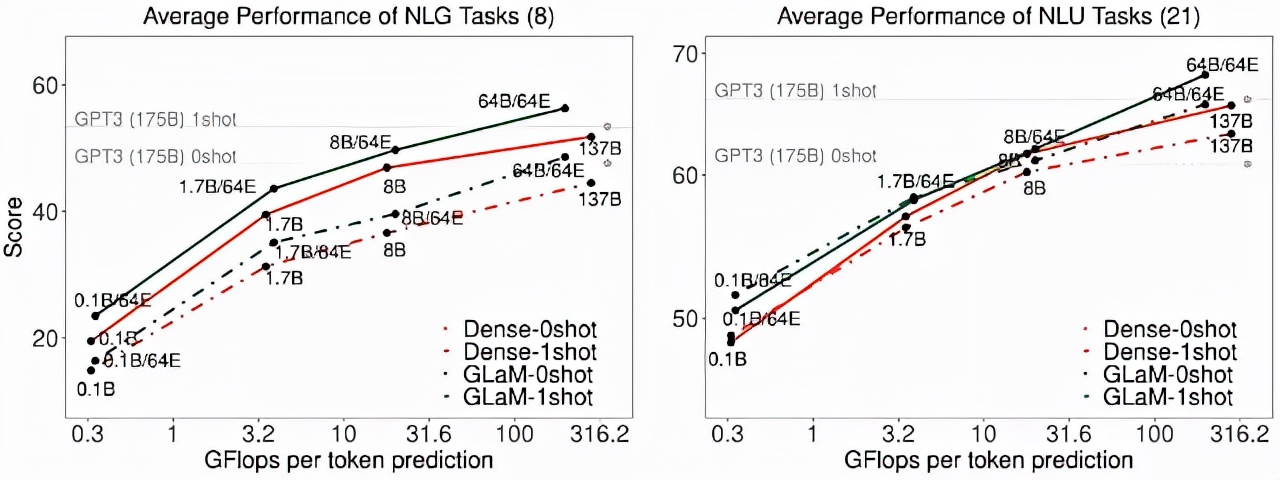
通過增加每個專家的大小,zero-shot 和 one-shot 的平均性能。隨著專家大小的增長,推理時每個 token 預測的 FLOPS 也會增加。
如上圖所示,跨任務的性能與專家的大小成比例。在生成任務的推理過程中,GLaM 稀疏激活模型的性能也優于 FLOP 類似的密集模型。對于理解任務,研究者觀察到它們在較小的規模上性能相似,但稀疏激活模型在較大的規模上性能更好。
數據效率
訓練大型語言模型計算密集,因此提高效率有助于降低能耗。該研究展示了完整版 GLaM 的計算成本。
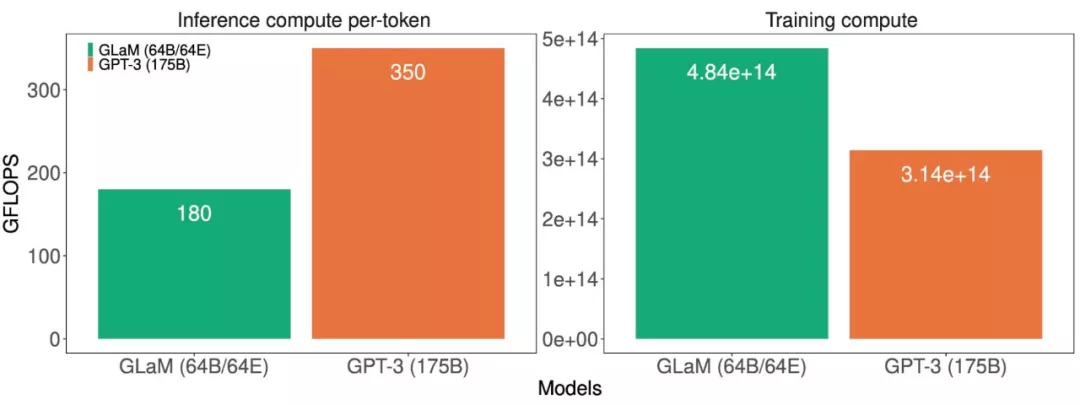
模型推理(左)和訓練(右)的計算成本(GFLOPS)。
這些計算成本表明 GLaM 在訓練期間使用了更多的計算,因為它在更多的 token 上訓練,但在推理期間使用的計算卻少得多。下圖展示了使用不同數量的 token 進行訓練的比較結果,并評估了該模型的學習曲線。
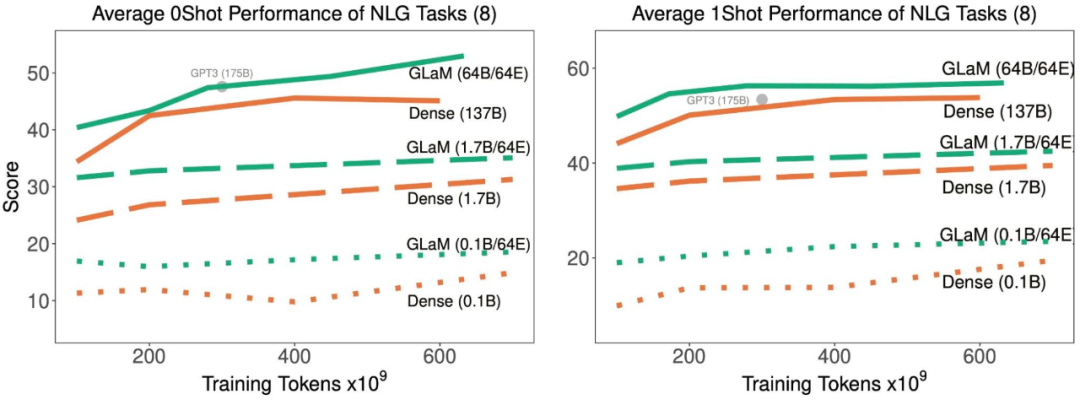
隨著訓練中處理了更多的 token,稀疏激活型和密集模型在 8 項生成任務上的平均 zero-shot 和 one-shot 性能。
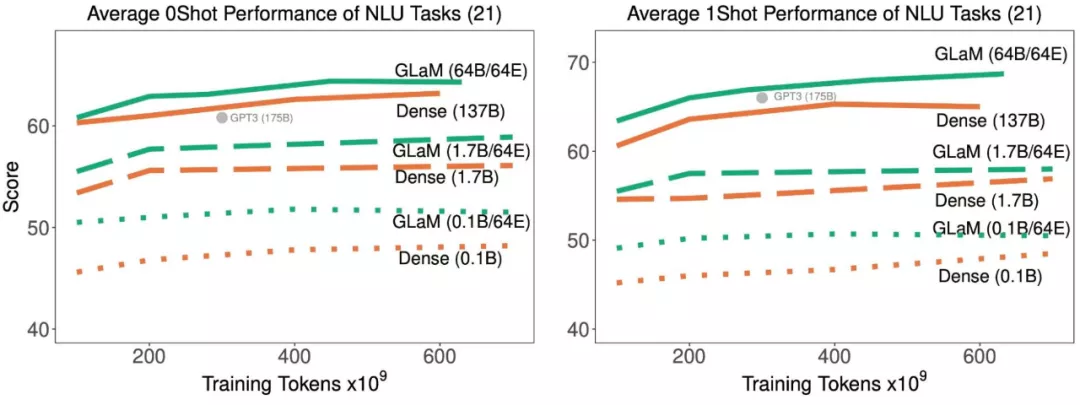
隨著訓練中處理了更多的 token,稀疏激活型和密集模型在 21 項理解任務上的平均 zero-shot 和 one-shot 性能。
結果表明,稀疏激活模型在達到與密集模型相似的 zero-shot 和 one-shot 性能時,訓練時使用的數據顯著減少。并且,如果適用的數據量相同,稀疏型模型的表現明顯更好。
最后,谷歌對 GLam 的能效進行了評估:
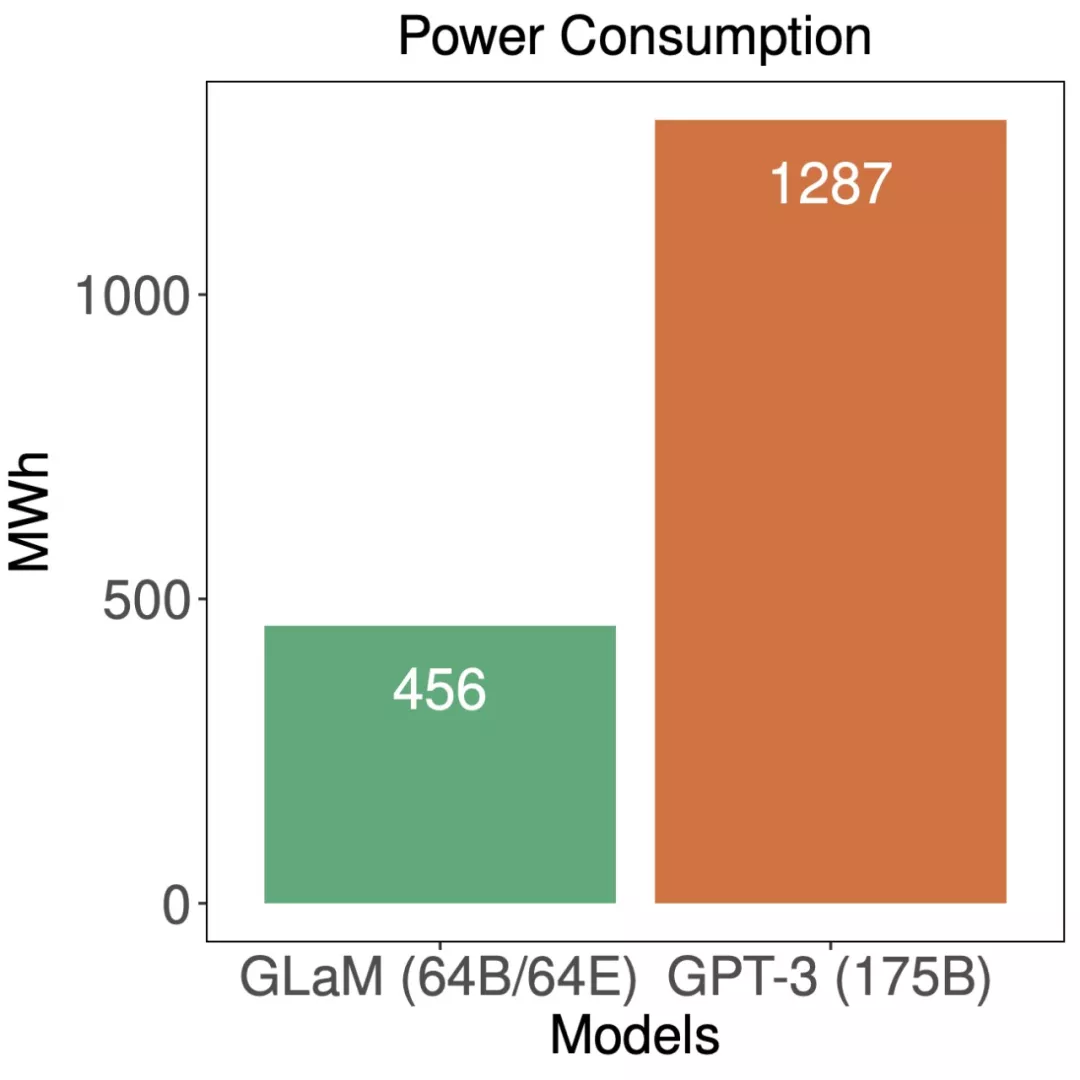
訓練期間,GLaM 與 GPT-3 的能耗比較。
雖然 GLaM 在訓練期間使用了更多算力,但得益于 GSPMD(谷歌 5 月推出的用于常見機器學習計算圖的基于編譯器的自動化并行系統)賦能的更高效軟件實現和 TPUv4 的優勢,它在訓練時耗能要少于其他模型。


























