16萬視頻對、28萬對片段,螞蟻開源視頻侵權(quán)檢測超大數(shù)據(jù)集
?傳統(tǒng)的版權(quán)保護(hù)行業(yè)費(fèi)時(shí)、費(fèi)力、成本高,海量內(nèi)容難以全量保護(hù),內(nèi)容分發(fā)難以掌控傳播的安全問題。區(qū)塊鏈技術(shù)具有不可篡改、追根溯源、分布式共識等特點(diǎn),和數(shù)字版權(quán)保護(hù)具有天然契合之處,將區(qū)塊鏈技術(shù)與 AI 多媒體侵權(quán)檢測技術(shù)相結(jié)合,極大降低了版權(quán)維權(quán)成本,提升版權(quán)保護(hù)效率,同時(shí)也為網(wǎng)絡(luò)版權(quán)的存證、交易、維權(quán)提供了新的途徑。因此,螞蟻集團(tuán) - 數(shù)字科技線推出了一站式數(shù)字內(nèi)容原創(chuàng)保護(hù)平臺 「鵲鑿」,圖片視頻等內(nèi)容一鍵上鏈,快速完成版權(quán)存證,在司法機(jī)關(guān)和公證機(jī)構(gòu)的共同見證下,成為“盜版維權(quán)” 的鐵證。
相關(guān)的產(chǎn)品介紹可見于官網(wǎng):https://www.mydcs.com/pages/index
在版權(quán)保護(hù)中,視頻侵權(quán)檢測能力是極為重要的一部分。現(xiàn)如今,盜版視頻的猖獗不僅讓視頻網(wǎng)站損失慘重,同時(shí)給內(nèi)容創(chuàng)作者帶來經(jīng)濟(jì)和精神上的損失更是不可估量。2021 年 4 月,中宣部版權(quán)局提出,加大對視頻侵權(quán)行為的打擊力度。近些年,包括二次創(chuàng)作、視頻剪輯在內(nèi)的侵權(quán)手段層出不窮,盜版視頻的侵權(quán)樣例也不僅局限在簡單的盜攝或者加水印等容易被識別的方式。因此面向版權(quán)保護(hù)的視頻侵權(quán)檢測方法就變得尤為重要,針對這一系列問題,基于 AI 的多媒體比對算法技術(shù),能夠顯著地節(jié)省人工審核的成本,提高侵權(quán)取證的效率,實(shí)現(xiàn)在大范圍檢索情況下做出精確的識別,是解決視頻侵權(quán)問題的有效方案。
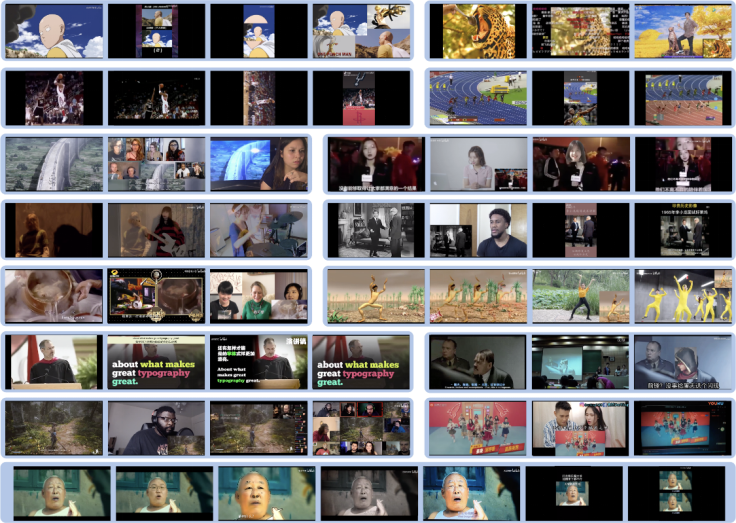
圖 1. 螞蟻構(gòu)建大規(guī)模視頻侵權(quán)數(shù)據(jù)集(VCSL)中的典型侵權(quán)樣例
但是目前針對版權(quán)侵權(quán)檢測,尤其是視頻侵權(quán)這一領(lǐng)域在學(xué)術(shù)界和產(chǎn)業(yè)界都存在著一些瓶頸問題,主要體現(xiàn)在下面三點(diǎn):
- 數(shù)據(jù)集,目前學(xué)術(shù)界已經(jīng)開源的數(shù)據(jù)集大部分都是只有視頻級別的標(biāo)注(Trecvid[1], SVD[2], FIVR[3]),即視頻對之間只標(biāo)注了是否侵權(quán),而并未標(biāo)注兩個(gè)視頻之間實(shí)際侵權(quán)的時(shí)間片段(即侵權(quán)起始時(shí)間位置和結(jié)束時(shí)間位置)。目前開源的擁有片段級別標(biāo)注的數(shù)據(jù)集僅有 2014 年 ECCV 上開源的 VCDB 數(shù)據(jù)集[4],但這個(gè)數(shù)據(jù)集規(guī)模比較小,僅有 6k 對實(shí)際侵權(quán)的視頻對,這也會(huì)在后面的章節(jié)進(jìn)行介紹。
- 算法評價(jià)指標(biāo),在學(xué)術(shù)界中,視頻級別的拷貝檢測評價(jià)指標(biāo)比較成熟,但是片段粒度的拷貝檢測準(zhǔn)確度的評價(jià)指標(biāo)仍然存在著比較多的問題。之前 VCDB 論文中提出的評價(jià)指標(biāo)在實(shí)際的實(shí)驗(yàn)測試中出現(xiàn)了一系列指標(biāo)上的偏差以及應(yīng)用上的問題。
- 侵權(quán)定位算法,侵權(quán)定位算法,在這里侵權(quán)定位(Temporal Alignment)算法指的是在提取出兩段視頻的時(shí)序特征后,需要輸出兩段視頻侵權(quán)的時(shí)間片段。大部分侵權(quán)定位的算法都是不開源的,因此學(xué)術(shù)界也無法形成一個(gè)完善的 benchmark,視頻拷貝檢測和侵權(quán)定位這個(gè)領(lǐng)域也相對較為停滯。
針對以上三個(gè)主要問題,該研究做了大量的視頻拷貝檢測和侵權(quán)定位相關(guān)的研究工作,包括了:
- 提出了目前最大規(guī)模(超過現(xiàn)有其他數(shù)據(jù)集 2 個(gè)數(shù)量級規(guī)模)的視頻侵權(quán)定位數(shù)據(jù)集,包括了超過 16 萬對侵權(quán)視頻對,28 萬對侵權(quán)片段,并且涵蓋了大量的視頻領(lǐng)域和視頻時(shí)長。
- 提出了全新的視頻片段拷貝檢測的評價(jià)指標(biāo),該評價(jià)指標(biāo)充分考慮到了視頻拷貝檢測這個(gè)任務(wù)的特殊性,并且在實(shí)際場景下體現(xiàn)出了更好的適應(yīng)性。
- 提出了關(guān)鍵幀和侵權(quán)定位端到端的模型 SSAN 并達(dá)到了現(xiàn)階段最高指標(biāo),并且將現(xiàn)階段學(xué)術(shù)界的常見侵權(quán)定位算法進(jìn)行復(fù)現(xiàn)并且開源,形成了完善全面的視頻侵權(quán)定位 benchmark。
上面的成果已經(jīng)分別被計(jì)算機(jī)視覺頂會(huì) CVPR 和多媒體頂會(huì) ACM MM 成功錄用和發(fā)表。

- CVPR 2022 VCSL 論文:https://arxiv.org/abs/2203.02654
- VCSL 數(shù)據(jù)集和評測以及算法代碼:https://github.com/alipay/VCSL
大規(guī)模視頻片段拷貝檢測數(shù)據(jù)集 VCSL針對上一節(jié)提出的現(xiàn)有數(shù)據(jù)集問題,該研究希望提出一個(gè)全面的數(shù)據(jù)集,滿足下面的要求:
- 視頻拷貝的類型必須要盡可能的全面,但是要避免過度變換使得侵權(quán)的視頻基本不具備觀賞性。
- 視頻類型必須覆蓋常見的視頻種類,比如電影、電視劇、動(dòng)畫、體育等不同場景。
- 視頻時(shí)長分布盡可能廣泛,不要局限于只是短視頻或者只是長視頻。
基于以上三個(gè)要求,該研究打標(biāo)完成了 VCSL(Video Copy Segment Localization)數(shù)據(jù)集。研究者從 Youtube 和 Bilibili 上選取了 122 個(gè)種子視頻,每個(gè)種子視頻也與關(guān)鍵詞相關(guān)聯(lián)。在打標(biāo)過程中,研究者模擬了真實(shí)情況,讓打標(biāo)同學(xué)進(jìn)行搜索找到可能侵權(quán)的視頻然后再進(jìn)行打標(biāo)比對,濾除不相干的視頻并標(biāo)注出實(shí)際侵權(quán)的時(shí)間片段。
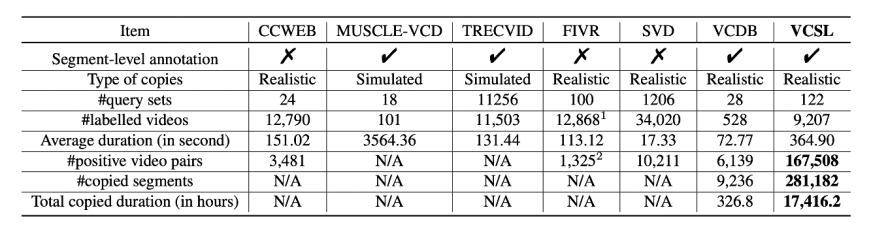
表 1. VCSL 與其他學(xué)術(shù)界現(xiàn)有數(shù)據(jù)集的比較
VCSL 數(shù)據(jù)集與學(xué)術(shù)界其他數(shù)據(jù)集的對比由表 1 所示,可以看到 VCSL 在侵權(quán)視頻對數(shù)量和侵權(quán)片段數(shù)量上都比現(xiàn)有學(xué)術(shù)界數(shù)據(jù)集高出兩個(gè)數(shù)量級。并且在視頻時(shí)長、侵權(quán)片段時(shí)長、視頻種類的分布上更加廣泛。
視頻片段拷貝檢測的新評價(jià)指標(biāo)
學(xué)術(shù)界范圍內(nèi),之前在 Muscle-VCD[5]和 VCDB[4]中提出過片段級別拷貝檢測的評價(jià)指標(biāo),這幾年比較常見的學(xué)術(shù)界工作主要用了 VCDB[4]中定義的片段的準(zhǔn)確率和召回率:

準(zhǔn)確率和召回率的分子均為正確被檢測到的片段,其中正確檢測到的片段定義為只要與實(shí)際的侵權(quán)片段有一幀的重合即定義為正確檢測。準(zhǔn)確率的分母為所有被檢測到的片段數(shù)量,召回率的分母為實(shí)際打標(biāo)真實(shí)拷貝的片段數(shù)量。另外,VCDB 論文中還定義了幀的準(zhǔn)確率和召回率:

與片段粒度類似,只不過統(tǒng)計(jì)維度是在幀粒度。
上述提到的片段準(zhǔn)確率 / 召回率和幀準(zhǔn)確率 / 召回率都有其局限性。最重要的一點(diǎn)是,該評價(jià)指標(biāo)只適合于片段和視頻的拷貝檢測,即需要打標(biāo)好的被侵權(quán)片段與可能侵權(quán)的視頻作為輸入,而不是兩段完整的視頻作為輸入,這種評價(jià)方式在實(shí)際場景下是不現(xiàn)實(shí)的。同時(shí),對于片段準(zhǔn)確率 / 召回率,檢測到的片段只要和實(shí)際的打標(biāo)片段有一幀重疊就認(rèn)為是正確的計(jì)算方式,會(huì)導(dǎo)致評價(jià)指標(biāo)對侵權(quán)定位的準(zhǔn)確度的感知比較差。另外,這些指標(biāo)沒有考慮到視頻拷貝的一些重要特性,即下面提到的切分等效性。
之前的評價(jià)指標(biāo)需要將標(biāo)注好的片段和視頻比較,這個(gè)并不適合于實(shí)際的應(yīng)用。在該研究提出的評價(jià)指標(biāo)中,他們用兩個(gè)完整的視頻作為輸入來檢測這兩個(gè)視頻中可能存在的拷貝片段。另外,該研究在觀察視頻拷貝的標(biāo)注數(shù)據(jù)中發(fā)現(xiàn)了視頻拷貝一個(gè)特性,即片段切分等效特性。這種特性是由于在某些情況下,很難確定拷貝片段的邊界,如下圖所示,視頻部分的中間幀被修改以及短暫插入其他視頻幀,如下圖 2(a)所示,另外圖 2(b)這種混剪的情況也類似,該研究認(rèn)為在這些情況下,將拷貝視頻片段標(biāo)注為一整段和多段連續(xù)的片段都是合理的。因此該研究在設(shè)計(jì)新的評價(jià)指標(biāo)時(shí),需要將這種片段切分等效特性考慮進(jìn)去,使得評價(jià)指標(biāo)對這種切分是魯棒的。

圖 2. 視頻侵權(quán)案例,(a),(b)圖左側(cè)為按時(shí)間排布的視頻畫面幀,右側(cè)為視頻幀序列相似圖,橫軸和縱軸分別代表著兩個(gè)視頻的時(shí)間軸,黑框內(nèi)表示實(shí)際標(biāo)注的侵權(quán)事件片段,詳細(xì)解釋圖也可見于后文圖 6 右側(cè)。
這個(gè)評價(jià)指標(biāo)的表示可以通過視頻幀相似圖進(jìn)行表示,如下圖所示。拷貝片段對在相似圖上表現(xiàn)為一個(gè)檢測框,而這個(gè)拷貝片段,可以表現(xiàn)為在相似圖上的一條直線,這表示了幀的順序?qū)?yīng)。而橘黃色框表示實(shí)際打標(biāo)的 GT 拷貝片段,藍(lán)色框表示算法輸出的預(yù)測拷貝片段。
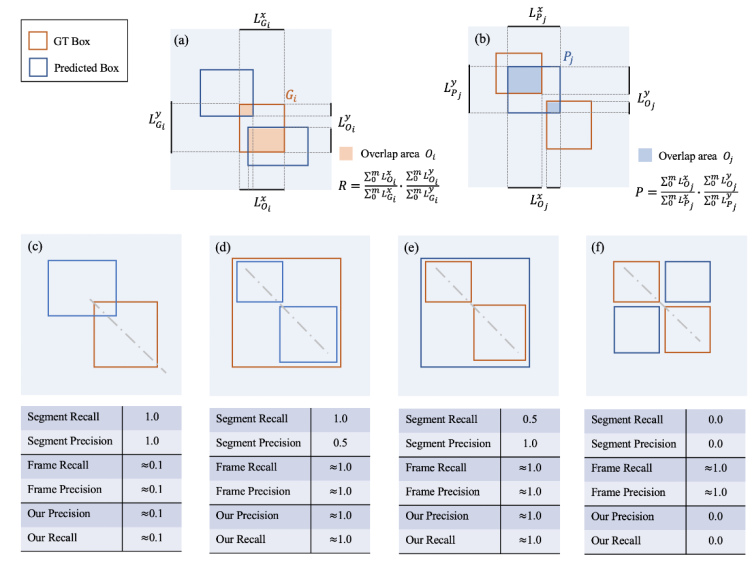
圖 3. (a-b)描述了該研究提出的算法計(jì)算過程,(c-f)描述了四種對比該研究提出的評價(jià)指標(biāo)和之前指標(biāo)對比的簡化情況。虛線表示侵權(quán)幀在時(shí)域上的位置,同時(shí)也會(huì)有其他更復(fù)雜的侵權(quán)情況表現(xiàn)為更復(fù)雜的 pattern。
具體來說,首先該研究找到每個(gè) GT 框與所有的預(yù)測框的交際區(qū)域,如上圖 (a) 所示,接下來計(jì)算這個(gè)交疊區(qū)域在 x 軸和 y 軸上的并集長度。同時(shí)計(jì)算出每個(gè) GT 框的長度和寬度,最后分子為交疊區(qū)域的并集長度相加,分母為 GT 框的長度相加,即可得到 recall,如上圖 (a) 所示。類似的,首先該研究找到每個(gè)預(yù)測框與所有 GT 框的交際區(qū)域,如上圖 (b) 所示,接下來計(jì)算這個(gè)交疊區(qū)域在 x 軸和 y 軸上的并集長度。同時(shí)計(jì)算出每個(gè)預(yù)測框的長度和寬度,最后分子為交疊區(qū)域的并集長度相加,分母為預(yù)測框的長度相加,即可得到 precision,如上圖 (b) 所示。
值得注意的是,該研究并沒有用學(xué)術(shù)界常用的面積,而是采用了 x y 軸的投影進(jìn)行計(jì)算,這是為了評價(jià)指標(biāo)對片段切分更加魯棒。最后,將 recall 和 precision 結(jié)合,得到 F-score,作為評價(jià)參數(shù)。
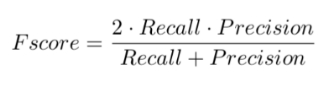

視頻片段拷貝檢測算法 benchmark
首先將視頻拷貝檢測算法的處理流程分為三個(gè)部分:視頻預(yù)處理,視頻特征提取和視頻侵權(quán)定位,如下圖所示。
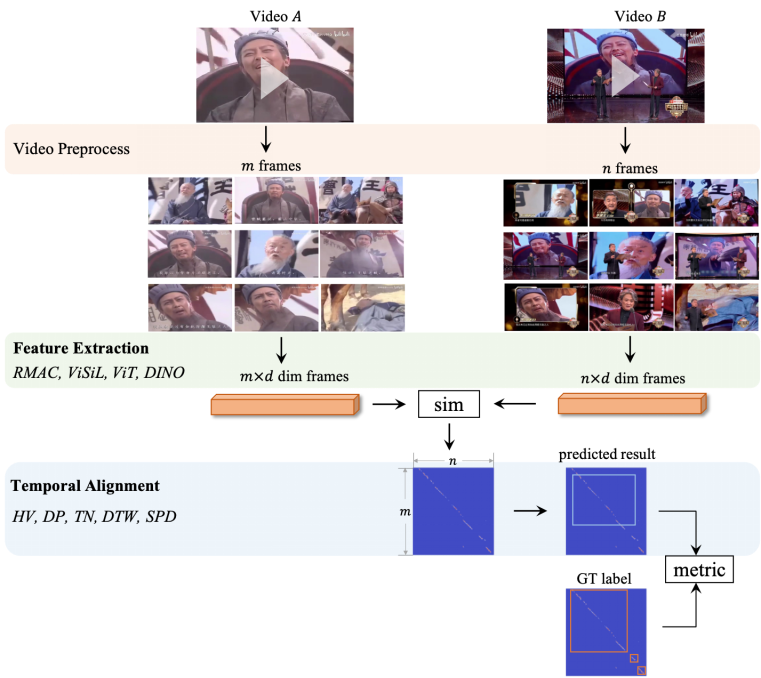
圖 4. 視頻拷貝檢測算法處理流程。
基于 VCSL 數(shù)據(jù)集和新的評價(jià)指標(biāo),該研究首先復(fù)現(xiàn)了目前常見的侵權(quán)定位算法,包括霍夫投票(Hough Voting)、時(shí)域網(wǎng)絡(luò)(Temporal Network)、動(dòng)態(tài)規(guī)劃(Dynamic Programming)、動(dòng)態(tài)時(shí)間扭曲(Dynamic Time Warping),并結(jié)合常見的開源幀特征算法,得到如下圖所示的 benchmark。
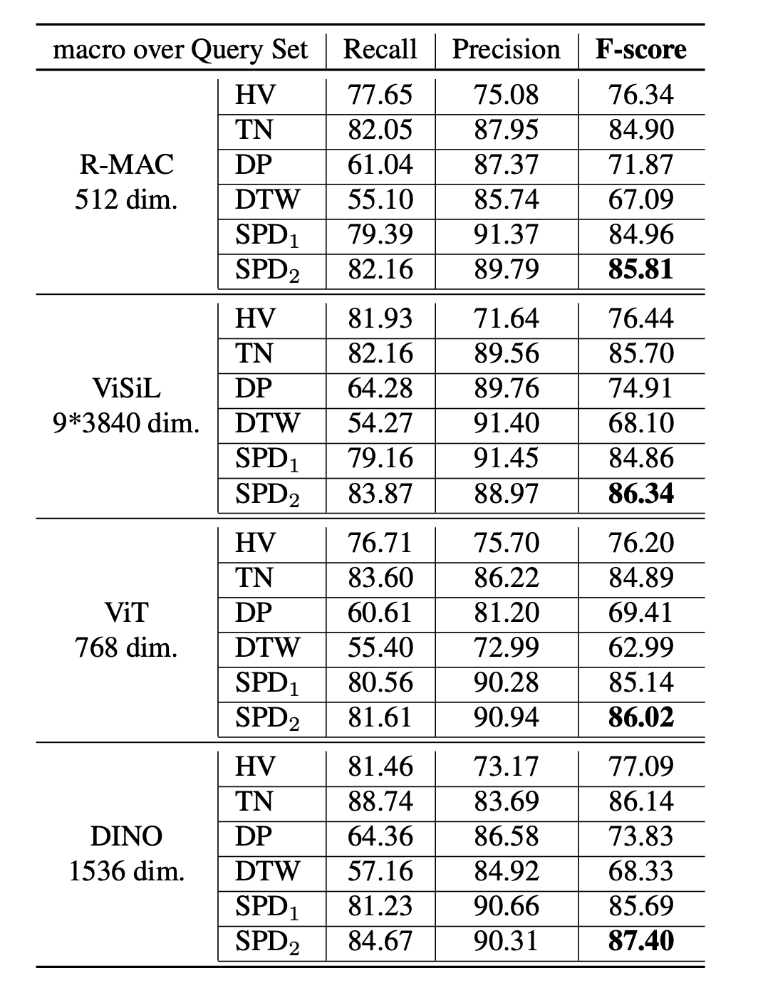
其中 SPD 是該研究團(tuán)隊(duì)在去年 ACM MM21 中提出的侵權(quán)定位算法,也是當(dāng)前視頻侵權(quán)定位效果最好的算法。其中 SPD 下劃線 1 表示在之前開源數(shù)據(jù)集 VCDB 上訓(xùn)練的效果,下劃線 2 表示在 VCSL 數(shù)據(jù)集上訓(xùn)練的效果。可以看到后者效果好于前者,這也說明了大規(guī)模數(shù)據(jù)集的重要性。
這里也簡單介紹下該研究在 ACM MM21 上發(fā)表的論文《Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval》,他們提出了一種視頻片段相似度和定位網(wǎng)絡(luò)(Segment Similarity and Alignment Network,SSAN),主要由兩個(gè)部分組成:自監(jiān)督關(guān)鍵幀檢測 (Self-supervised Keyframe Extraction,SKE) 和相似圖侵權(quán)定位檢測(Similarity Pattern Detection,SPD)。關(guān)鍵幀檢測(SKE)主要用于提取魯棒且有代表性的關(guān)鍵幀,去除相似冗余幀;相似圖侵權(quán)定位檢測(SPD)主要用于視頻相似片段定位。整個(gè) SSAN 可以端到端進(jìn)行訓(xùn)練,得到現(xiàn)階段最好的片段級別侵權(quán)定位效果。
論文地址:https://dl.acm.org/doi/abs/10.1145/3474085.3475301
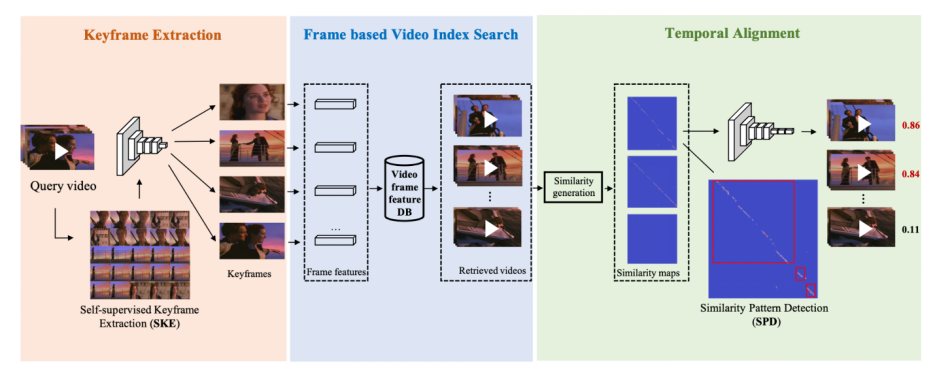
圖 5. SSAN 算法結(jié)構(gòu),包括了關(guān)鍵幀抽取模塊,基于幀的視頻檢索和時(shí)域侵權(quán)定位模塊
在相似圖侵權(quán)定位檢測(SPD)這個(gè)模塊中,該研究巧妙地將侵權(quán)定位問題轉(zhuǎn)變成一個(gè)目標(biāo)檢測問題,如下圖所示,這樣就只需要極少的運(yùn)算量就可以得到侵權(quán)定位的結(jié)果,并且具有多段侵權(quán)檢測能力。
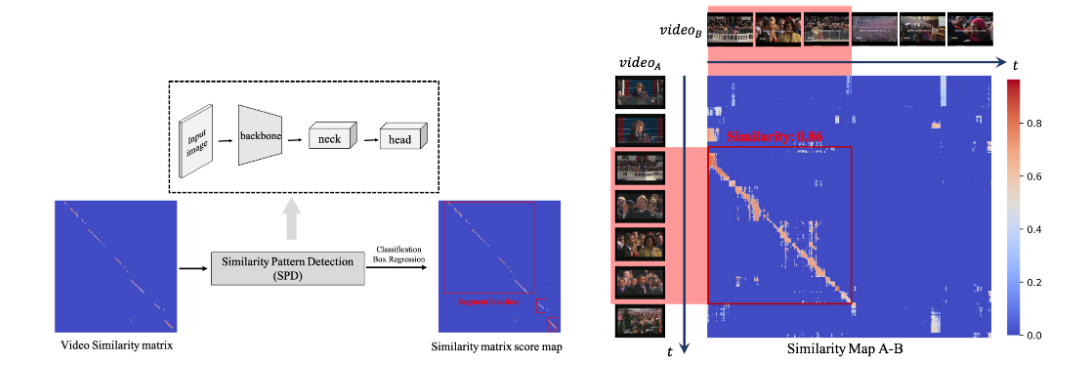
圖 6. 左圖,時(shí)域侵權(quán)定位 SPD 算法示意圖,右圖,相似圖生成與原視頻對示意圖