端到端的自動駕駛離我們還有多遠?
端到端自動駕駛是一種很有前途的模式,因為它避開了與模塊化系統相關的缺點,比如較高的系統復雜性。自動駕駛超越了傳統的交通模式,提前主動識別關鍵事件,確保乘客的安全,并提供舒適的交通環境,特別是在高度隨機和可變的交通環境中。本文全面回顧了端到端自動駕駛技術。
首先闡述了自動駕駛任務的分類,包含端到端神經網絡的使用,涵蓋了從感知到控制的整個駕駛過程,同時解決了現實世界應用中遇到的關鍵挑戰。分析了端到端自動駕駛的最新發展,并根據基本原理、方法和核心功能對研究進行了分類。這些類別包括感知輸入、主要輸出和輔助輸出、從模仿到強化學習的學習方法以及模型評估技術。本文還調查了包括對可解釋性和安全性方面的詳細討論。最后評估了最先進的技術,確定了挑戰,并探索了未來的可能性。
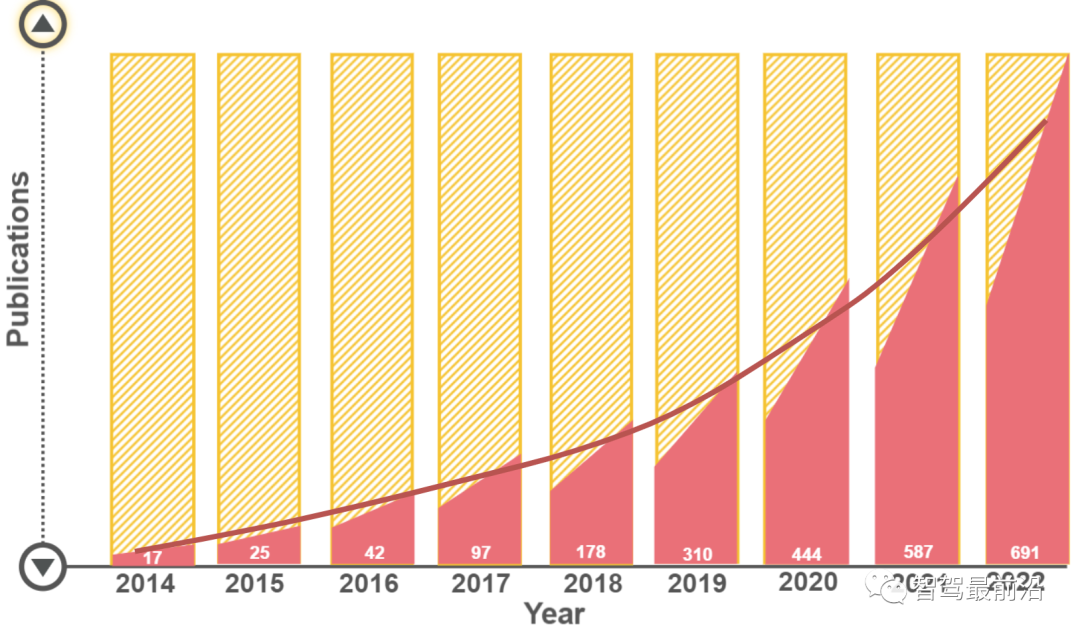
Fig. 1: The number of articles in the Web of Science databasecontaining the keywords ‘End-to-End’ and ‘Autonomous Driving’ from 2014 to 2022 illustrates the increasing trend in the research community.
總結來說本文的主要貢獻如下:
- 這是第一篇專門探討使用深度學習的端到端自動駕駛的綜述論文。我們對基本原理、方法和功能進行了全面分析,深入研究了該領域的最新技術進步;
- 我們提出了一個詳細的分類(圖2),基于輸入模式、輸出模式和基本的學習方法。此外還對安全性和可解釋性方面進行了全面檢查,以識別和解決特定領域的挑戰;
- 我們提出了一個基于開環和閉環評估的評估框架。此外還總結了一份公開可用的數據集和仿真的匯總列表。最后評估了最近的方法,并探索了有趣的未來可能性。
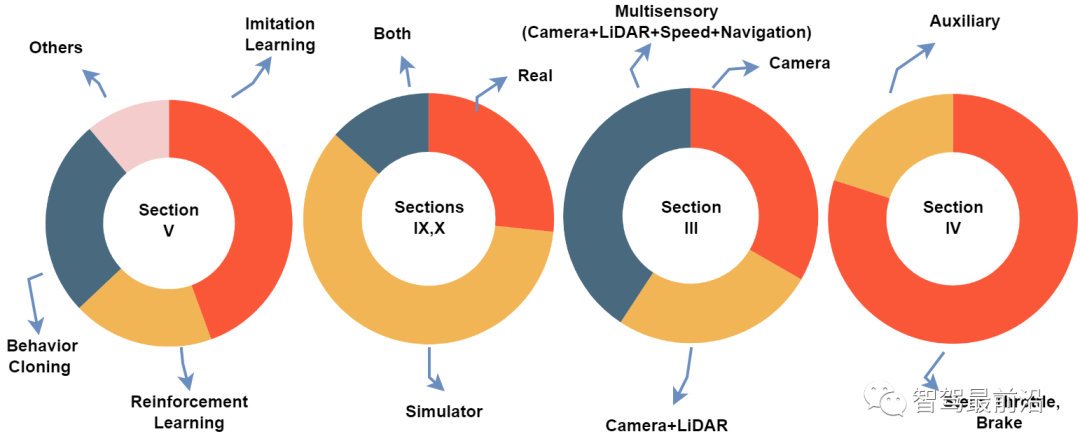
Fig. 2: The charts illustrate statistics of the papers included in this survey according to learning approaches (section V),environment being utilized for training (sections IX, X), input modality (section III), and output modality (section IV)
01 端到端系統體系結構
通常,模塊化系統被稱為中間范式,并被構建為離散組件的管道(圖3),連接傳感器輸入和運動輸出。模塊化系統的核心過程包括感知、定位、建圖、規劃和車輛控制。模塊化流水線首先將原始傳感器數據輸入到感知模塊,用于障礙物檢測,并通過定位模塊進行定位。隨后進行規劃和預測,以確定車輛的最佳和安全行程。最后控制器生成安全操縱的命令。模塊化系統的詳細概述可在補充材料中找到。

Fig. 3: Comparison between End-to-End and modular pipelines. End-to-End is a single pipeline that generates the control signal directly from perception input, whereas a modular pipeline consists of various sub-modules, each with taskspecific functionalities.
另一方面,直接感知或端到端驅動直接從傳感器輸入輸出自車運動。它優化了駕駛管道(圖3),繞過了與感知和規劃相關的子任務,允許像人類一樣不斷學習感知和行動。Pomerleau Alvinn首次嘗試了端到端駕駛,該公司訓練了一個三層傳感器運動全連接網絡來輸出汽車的方向。端到端駕駛基于傳感器輸入輸出自車運動,這種運動可以是各種形式的。然而,最突出的是相機、LiDAR、導航命令、和車輛動力學,如速度。這種感知信息被用作主干模型的輸入,主干模型負責生成控制信號。自車運動可以包含不同類型的運動,如加速、轉彎、轉向和蹬踏。此外,許多模型還輸出附加信息,例如安全機動的成本圖、可解釋的輸出或其他輔助輸出。
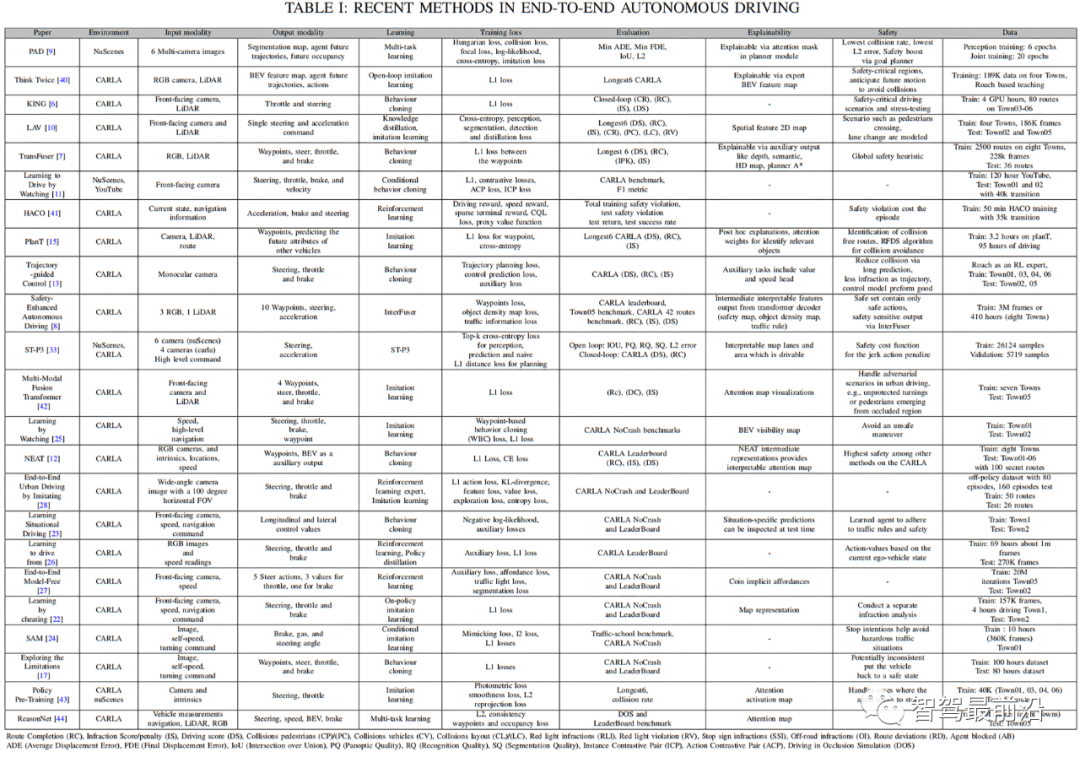
端到端駕駛有兩種主要方法:要么通過強化學習(RL)探索和改進駕駛模型,要么使用模仿學習(IL)以監督的方式訓練駕駛模型,以模仿人類駕駛行為。監督學習范式旨在從專家演示中學習駕駛風格,作為模型的訓練示例。然而,擴展基于IL的自動駕駛系統具有挑戰性,因為不可能覆蓋學習階段的每個實例。另一方面,RL的工作原理是通過與環境的互動,隨著時間的推移最大化累積獎勵,網絡根據其行為做出駕駛決策以獲得獎勵或處罰。雖然RL模型訓練是在線進行的,并且可以在訓練過程中探索環境,但與模仿學習相比,它在利用數據方面的效果較差。表I總結了端到端駕駛的最新方法。
02 輸入模態
1)相機:基于相機的方法在端到端驅動中顯示出了有希望的結果。例如,Toromanoff等通過在城市環境中使用基于視覺的方法贏得 CARLA 2019自動駕駛挑戰賽。使用單目和雙目是圖像到控制端到端駕駛的自然輸入方式。
2)激光雷達:自動駕駛的另一個重要輸入源是LiDAR傳感器。LiDAR能夠抵抗光照條件,并提供準確的距離估計。相比其他感知傳感器,激光雷達數據最豐富,提供的空間信息最全面。它利用激光來檢測距離并生成點云,點云是空間的3D表示,其中每個點都包含反射傳感器激光束的表面的(x,y,z)坐標。在定位車輛時,生成里程測量結果至關重要。許多技術利用LiDAR在鳥瞰圖 (BEV)、高清 (HD)地圖和SLAM中進行特征映射。這些定位技術可以分為基于配準的方法、基于特征的方法和基于學習的方法。
3)多模態:多模態在關鍵感知任務中優于單模態,并且特別適合自動駕駛應用,因為它結合了多傳感器數據。根據何時組合多傳感器信息,信息利用可分為三大類。在早期融合中,傳感器數據先進行組合,然后再將其輸入可學習的端到端系統。在中期融合中,信息融合是在一些預處理階段或一些特征提取之后完成的。在后期融合中,輸入被單獨處理,它們的輸出被融合并由另一層進一步處理。
4)語義表示:端到端模型也可以將語義表示作為輸入。這種表示側重于學習車輛及其環境的幾何和語義信息。
它通常涉及將各種感知傳感器的幾何特征投影到圖像空間,例如鳥瞰圖和范圍視圖。雖然原始RGB圖像包含所有可用信息,但事實證明,顯式合并預定義的表示并將其用作附加輸入可以增強模型的彈性。Chen等在學習的語義圖上采用循環注意力機制來預測車輛控制。此外,一些研究利用語義分割作為導航目的的附加表示。
5)導航輸入:端到端駕駛模型可以包含高級導航指令或專注于特定的導航子任務,例如車道維護和縱向控制。導航輸入可以源自路徑規劃器或導航命令。路徑是由全局規劃器提供的全球定位系統(GPS)坐標中的一系列離散端點位置定義的。TCP模型接收相關的導航指令,例如留在車道上、左/右轉和目標,以生成控制動作,如圖4(c)所示。FlowDriveNet考慮了全局規劃器的離散導航命令和導航目標的坐標。除了上述輸入之外,端到端模型還包含車輛動力學,例如自車輛速度。圖4(b)說明了NEAT如何利用速度特征來生成航路點。

Fig. 4: The input-output representation of various End-to-End models: (a) Considered RGB image and LiDAR BEV representations as inputs to the multi-modal fusion transformer [7] and predicts the differential ego-vehicle waypoints. (b) NEAT [12] inputs the image patch and velocity features to obtain a waypoint for each time-step used by PID controllers for driving. (c) TCP [13] takes input image i, navigation information g, current speed v, to generate the control actions guided by the trajectory branch and control branch. (d) LAV [10] uses an image-only input and predicts multi-modal future trajectories used for braking and handling traffic signs and obstacles. (e) UniAD [9] generates attention mask visualization which shows how much attention is paid to the goal lane as well as the critical agents that are yielding to the ego-vehicle. (f) ST-P3 [33] outputs the sub cost map from the prediction module (darker color indicates a smaller cost value). By incorporating the occupancy probability field and leveraging pre-existing knowledge, the cost function effectively balances safety considerations for the final trajectory.
03 輸出模態
通常端到端自動駕駛系統輸出控制命令、航跡點或軌跡。此外,它還可能產生額外的表示,例如成本圖和輔助輸出。圖4說明了一些輸出模式。
a) 航跡點:預測未來航跡點是一種更高級別的輸出模式。幾位作者使用自回歸路點網絡來預測差分路點。軌跡也可以表示坐標系中的航路點序列。使用模型預測控制(MPC)和比例積分微分(PID)將網絡的輸出航路點轉換為低級轉向和加速度。縱向控制器考慮連續時間步路點之間矢量的加權平均值的大小,而橫向控制器考慮它們的方向。理想的航跡點取決于所需的速度、位置和旋轉。橫向距離和角度必須最小化,以最大化獎勵(或最小化偏差)。利用航跡點作為輸出的好處是它們不受車輛幾何形狀的影響。此外,控制器更容易分析航跡點以獲取轉向等控制命令。連續形式的航跡點可以轉化為特定的軌跡。
b) 懲罰函數:為了車輛的安全操縱,許多軌跡和航跡點都是可能的。成本用于在可能性中選擇最佳的一種。它根據最終用戶定義的參數(例如安全性、行駛距離、舒適度等)為每個軌跡分配權重(正分或負分)。Zeng等采用神經運動規劃器,使用成本量來預測未來的軌跡。Hu等采用了一種成本函數,該函數利用學習到的占用概率場(由分割圖(圖4(f))表示)和交通規則等先驗知識來選擇成本最小的軌跡。
c)直接控制和加速:大多數端到端模型在特定時間戳提供轉向角和速度作為輸出。輸出控制需要根據車輛的動力學進行校準,確定適當的轉彎轉向角度以及在可測量距離處停止所需的制動。
d) 輔助輸出:輔助輸出可以為模型的運行和駕駛動作的確定提供附加信息。幾種類型的輔助輸出包括分割圖、BEV圖、車輛的未來占用率以及可解釋的特征圖。如圖 4(e) 和 (f) 所示,這些輸出為端到端管道提供了附加功能,并幫助模型學習更好的表示。輔助輸出還有助于解釋模型的行為,因為人們可以理解信息并推斷模型決策背后的原因。
04 學習方法
以下是端到端駕駛的不同學習方式。
模仿學習
模仿學習(IL)基于從專家演示中學習的原則,通常由人類執行。這些演示訓練系統模仿專家在各種場景(例如車輛控制)中的行為。大規模的專家駕駛數據集很容易獲得,可以通過模仿學習利用這些數據集來訓練按照類人標準執行的模型(見圖 5)。Alvinn 是模仿學習在端到端自動駕駛車輛系統中的第一個應用,展示了以高達55英里/小時的速度駕駛汽車的能力。它經過訓練,可以使用從人類駕駛員收集的實時訓練數據來預測轉向角。行為克隆(BC)、直接策略學習(DPL)和逆強化學習(IRL)是模仿學習在自動駕駛領域的延伸。
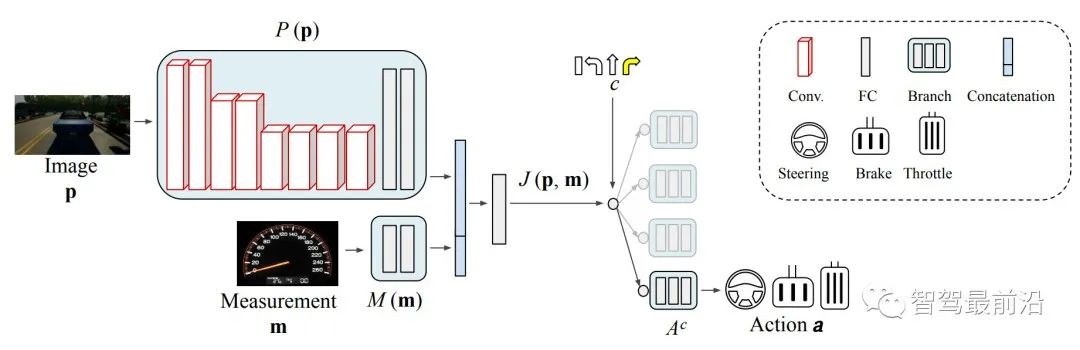
Fig. 5: Vehicle maneuvers, represented by a triplet of steering angle, throttle, and brake, depend on a high-level route navigation command (e.g., turn-left, turn-right, go-straight, continue), as well as perception data (e.g., RGB image) and vehicle state measurements (e.g., speed). These inputs guide the specific actions taken by the vehicle, enabling it to navigate the environment effectively through conditional imitation learning [32].
模仿學習的主要目標是訓練一個策略,將每個給定狀態映射到相應的動作(圖 5),盡可能接近給定的專家策略,給定具有狀態動作對的專家數據集:

1)行為克隆:行為克隆是監督模仿學習任務,其目標是將專家分布中的每個狀態-動作組合視為獨立同分布(IID)示例,并最大限度地減少訓練策略的模仿損失:
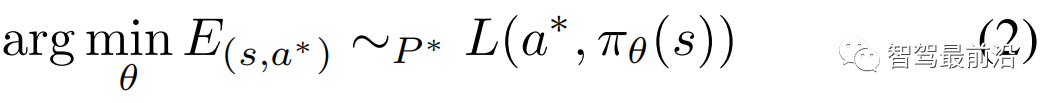
行為克隆假設專家的行為可以通過觀察得到充分解釋,因為它訓練模型根據訓練數據集直接從輸入數據映射到輸出數據(圖6)。然而在現實場景中,有許多潛在變量影響和控制駕駛代理。因此有效地學習這些變量至關重要。

Fig. 6: Behavior cloning [23] is a perception-to-action driving model that learns behavior reflex for various driving scenarios. The agent acquires the ability to integrate expert policies in a context-dependent and task-optimized manner, allowing it to drive confidently
2)直接策略學習:與將傳感器輸入映射到控制命令的模仿學習相反,直接策略學習旨在直接學習將輸入映射到駕駛行為的最優策略。它使智能體能夠探索周圍環境并發現新穎且高效的駕駛策略。相比之下,行為克隆受到訓練數據集的限制,僅包含特定行為,在新場景上可能表現不佳。在線模仿學習算法DAGGER提供了針對級聯錯誤的魯棒性并提高了泛化性。然而,直接策略學習的主要缺點是在培訓過程中持續需要專家的參與,這既昂貴又低效。
3)逆強化學習:逆強化學習(IRL)旨在通過獎勵函數推斷潛在的特定行為。基于特征的IRL教授高速公路場景中的不同駕駛方式。人類提供的示例用于學習不同的獎勵函數以及與道路使用者交互的能力。最大熵(MaxEnt)逆強化學習是基于最大熵原理的基于特征的IRL的擴展。該范例有力地解決了獎勵模糊性并處理次優化。主要缺點是 IRL 算法的運行成本昂貴。它們對計算的要求也很高,在訓練過程中不穩定,并且可能需要更長的時間才能收斂到較小的數據集。需要更高效的計算方法來獲得獎勵函數。
強化學習
強化學習(RL)是解決分布轉移問題的一種有前途的方法。它的目標是通過與環境交互來隨著時間的推移最大化累積獎勵,并且網絡根據其行為做出駕駛決策以獲得獎勵或懲罰。IL無法處理與訓練數據集顯著不同的新情況。然而,強化學習對于這個問題很魯邦,因為它在訓練期間探索了所有相關場景。強化學習涵蓋各種模型,包括基于價值的模型,例如深度Q網絡(DQN),基于actor-critic的模型,例如深度確定性策略梯度(DDPG)和異步優勢行動者批評家(A3C),最大熵模型,例如Soft Actor Critic(SAC),以及基于策略的優化方法,例如信任區域策略優化(TRPO)和近端策略優化(PPO)。
Liang展示了第一個有效的基于視覺的驅動管道的強化學習方法,其性能優于當時的模塊化管道。他們的方法基于深度確定性策略梯度(DDPG),這是actor-critic算法的擴展版本。

最近,人機循環(HITL)方法在文獻中引起了關注。這些方法的前提是專家論證為實現高回報政策提供了寶貴的指導。一些研究的重點是將人類專業知識融入到傳統強化學習或IL 范式的訓練過程中。EGPO就是一個這樣的例子,它旨在開發一種專家指導的策略優化技術,其中專家策略監督學習代理。

Fig. 7: RL-based learning method for training the agent to drive optimally: (a) Illustrating the reinforcement learning expert [28] that maps the BEV to the low-level driving actions; the expert can also provide supervision to the imitation learning agent. (b) Human-in-the-loop learning [41] allows the agent to explore the environment, and in danger scenarios, the human expert takes over the control and provides the safe demonstration.
HACO允許智能體探索危險環境,同時確保訓練安全。在這種方法中,人類專家可以干預并指導代理避免潛在的有害情況或不相關的行為(見圖7(b))。一般來說,專家可以為模仿學習或強化學習提供高級別的監督。最初可以使用模仿學習來教授策略,然后使用強化學習來完善策略,這有助于減少強化學習所需的大量訓練時間。
其他學習方法
明確設計具有部分組件的端到端系統的學習方法涵蓋各種方法,包括多任務學習、面向目標的學習和SP-T3等特定技術。此外,像PPGeo這樣的自監督學習框架利用未標記的駕駛視頻來建模駕駛策略。這些方法旨在訓練能夠有效處理多個任務的模型,針對特定目標進行優化,并結合專門的技術來增強端到端系統的性能和功能。
05 學習從模擬器到真實的域適應
可以在虛擬引擎中構建大規模虛擬場景,從而更輕松地收集大量數據。然而,虛擬數據和現實世界數據之間仍然存在顯著的領域差異,這給創建和實現虛擬數據集帶來了挑戰。通過利用領域適應原理,我們可以直接從模擬器中提取關鍵特征,并將從源領域學到的知識轉移到由準確的現實世界數據組成的目標領域。
H-Divergence 框架通過對抗學習域分類器和檢測器來解決視覺和實例級別的域差距。Zhang提出了一種模擬器-真實交互策略,利用源域和目標域之間的差異。作者創建了兩個組件來協調全球和本地層面的差異,并確保它們之間的整體一致性。隨后逼真的合成圖像可用于訓練端到端模型。
一些工作利用虛擬LiDAR數據。Sallab對來自CARLA的虛擬LiDAR點云進行學習,并利用CycleGAN將樣式從虛擬域轉移到真實的KITTI數據集。關于規劃和決策差異,Pan提出了在具有現實框架的模擬環境中學習駕駛策略,然后再將其應用于現實世界。
06 安全性
確保端到端自動駕駛系統的安全是一項復雜的挑戰。雖然這些系統具有高性能潛力,但為了維護整個管道的安全,一些考慮因素和方法至關重要。首先使用涵蓋廣泛場景(包括罕見和危急情況)的多樣化、高質量數據來訓練系統。[23]表明,針對關鍵場景的培訓有助于系統學習穩健且安全的行為,并為其應對環境條件和潛在危險做好準備。這些場景包括十字路口處無保護的轉彎、行人從遮擋區域出現、激進的變道以及其他安全啟發法,如圖 8(b) 和 (c) 所示。

Fig. 8: Demonstration of safe driving methods: (a) InterFuser [8] processes multisensorial information to detect adversarial events, which are then used by the controller to constrain driving actions within safe sets. (b) KING [6] improves collision avoidance using scenario generation. The image shows the ego vehicle (shown in red) maintaining a safe distance during a lane merge in the presence of an adversarial agent (shown in blue). (c) In the same context, the image illustrates the vehicle slowing down to avoid collision.
將安全約束和規則集成到端到端系統中是另一個重要方面。系統可以通過在學習或后處理系統輸出期間納入安全考慮因素來優先考慮安全行為。安全約束包括安全成本函數、避免不安全的操作和避免碰撞策略。Zeng等明確負責安全規劃的成本量。為了避免不安全的操作,Zhang等消除不安全的航點,Shao等引入InterFuser(圖8(a)),它僅約束安全集中的動作,并僅引導最安全的動作。上述約束確保系統在預定義的安全邊界內運行。
實施額外的安全模塊和測試機制(表 II、表 III)可增強系統的安全性。對系統行為的實時監控可以檢測異常或安全操作偏差。Wu等提出了一種軌跡+控制模型,可以預測長范圍內的安全軌跡。Hu等還采用目標規劃器來確保安全。這些機制確保系統能夠檢測并響應異常或意外情況,從而降低發生事故或不安全行為的風險。
如表二所示,對抗打擊方法被用于端到端駕駛測試,以評估輸出控制信號的正確性。這些測試方法旨在識別漏洞并評估針對對手的穩健性。端到端測試表 (III) 確定給定場景內的正確控制決策。變質測試通過驗證不同天氣和照明條件下轉向角度的一致性來解決預言機問題。它提供了一種可靠的方法來確保轉向角保持穩定且不受這些因素的影響。差異測試通過比較同一場景的推理結果,揭示了不同 DNN 模型之間的不一致。如果模型產生不同的結果,則表明系統中存在意外行為和潛在問題。基于模型的預言機采用經過訓練的概率模型來評估和預測真實場景中的潛在風險。通過監視環境,它可以識別系統可能無法充分處理的情況。


安全指標提供了評估自動駕駛系統性能的定量措施,并評估系統在安全方面的功能。碰撞時間 (TTC)、沖突指數 (CI)、碰撞潛在指數 (CPI)、反應時間 (TTR) 等一些指標可以提供各種方法的安全性能之間的額外客觀比較并識別區域 需要改進的地方。安全指標對于監控和開發安全可靠的駕駛解決方案至關重要。表IV 提供了這些指標的詳細描述。

07 可解釋性
可解釋性是指理解代理邏輯的能力,重點關注用戶如何解釋模型輸入和輸出之間的關系。它包含兩個主要概念:可解釋性,涉及解釋的可理解性;完整性,涉及通過解釋詳盡地定義模型的行為。Cui等區分了對自動駕駛汽車的三種信心:透明度,指的是人預見和理解車輛操作的能力;技術能力,與了解車輛性能有關;情況管理,其中涉及用戶可以隨時重新獲得車輛控制權的概念。根據哈斯皮爾等人的說法,當人類參與時,解釋起著至關重要的作用,因為解釋自動駕駛汽車行為的能力會顯著影響消費者的信任,而這對于廣泛接受這項技術至關重要。
關于模仿和強化學習方法正在進行大量研究,重點是提供模型行為解釋的解釋能力。為了描述事后解釋方法,已經確定了兩類(圖 9):局部方法(VIII-A),它解釋對特定動作實例的預測;全局方法(VIII-B),它解釋 模型作為一個整體。

Fig. 9: Categorization of Explainability Approaches.
Local explanations
1)Post-hoc顯著性方法:事后顯著性技術試圖解釋像素的哪些部分對模型的輸出影響最大。這些方法提供了一個顯著性圖,說明模型做出最重要決策的位置。
Post-hoc顯著性方法主要關注駕駛架構的感知組件。這些局部預測被用作視覺注意力圖,并使用線性組合與學習參數相結合來做出最終決策。雖然基于注意力的方法通常被認為可以提高神經網絡的透明度,但應該注意的是,學習到的注意力權重可能與多個特征表現出弱相關性。在測量駕駛過程中的不同輸入特征時,注意力權重可以提供準確的預測。總體而言,評估注意力機制的事后有效性具有挑戰性,并且通常依賴于主觀的人類評估。

Fig. 10: Explainability Methods: (a) PlanT [15] visualization showing the attention given to the agent in various scenarios. (b) Using InterFuser [8], failure cases can be visualized by integrating three RGB views and a predicted object density map. The orange boxes indicate objects that pose a collision risk to the ego-vehicle. The object density map offers predictions for the current traffic scene (t0) and future traffic scenes at 1-second (t1) and 2-second (t2) intervals.
2)反事實解釋:顯著性方法側重于回答“哪里”的問題,識別對模型決策有影響的輸入位置。相比之下,反事實解釋通過尋找輸入中改變模型預測的微小變化來解決“什么”問題。
由于輸入空間由語義維度組成并且是可修改的,因此評估輸入組件的因果關系很簡單。Li等最近提出了一種用于識別風險對象的因果推理技術。語義輸入提供了高級對象表示,使其比像素級表示更易于解釋。
在端到端驅動中,轉向、油門和制動驅動輸出可以通過提供反事實解釋的輔助輸出來補充。Chitta等提出使用 A* 規劃器的可解釋的輔助輸出。Shao等設計了一個系統,如圖10(b)所示,它生成一個安全思維導圖,在中間對象密度圖的幫助下推斷潛在的故障。
Global explanations
全局解釋旨在通過描述模型所擁有的知識來提供對模型行為的整體理解。它們分為模型翻譯(VIII-B1)和表示解釋技術(VIII-B2),用于分析全局解釋。
1)模型翻譯:模型翻譯的目標是將信息從原始模型轉移到本質上可解釋的不同模型。這涉及訓練一個可解釋的模型來模擬輸入輸出關系。最近的研究探索了將深度學習模型轉化為決策樹、基于規則的模型或因果模型。然而,這種方法的一個局限性是可解釋的翻譯模型與原始自動駕駛模型之間可能存在差異。
2)解釋表示:解釋表示旨在解釋模型結構在不同尺度上捕獲的信息。神經元的激活可以通過檢查最大化其活動的輸入模式來理解。例如,可以使用梯度上升或生成網絡對輸入進行采樣。
08 評估
End-to-End系統的評估分為開環評估和閉環評估。使用真實世界的基準數據集(例如KITTI和 nuScenes)評估開環。它將系統的駕駛行為與專家的行為進行比較并測量偏差 MinADE、MinFDE、L2 誤差和沖突率 [58] 等指標是表I中列出的一些評估指標。相比之下,閉環評估直接評估受控現實世界或受控現實世界中的系統。通過允許其獨立駕駛并學習安全駕駛操作來模擬設置。
在端到端駕駛系統的開環評估中,系統的輸入(例如相機圖像或激光雷達數據)被提供給系統。所產生的輸出(例如轉向命令和車輛速度)將根據預定義的駕駛行為進行評估。開環評估中常用的評估指標包括衡量系統遵循期望軌跡或駕駛行為的能力,例如預測軌跡和實際軌跡之間的均方誤差或系統保持在該軌跡內的時間百分比 所需軌跡的一定距離。其他評估指標也可用于評估系統在特定駕駛場景中的性能,例如系統導航交叉路口、處理障礙物或執行車道變換的能力。
最近的大多數端到端系統都是在閉環設置中進行評估的,例如LEADERBOARD和NOCRASH [79]。表V比較了 CARLA 公共排行榜上所有最先進的方法。CARLA 排行榜分析意環境中的自動駕駛系統。車輛的任務是完成一組指定的路線,其中包括意外穿越行人或突然變道等危險場景。排行榜衡量車輛在規定時間內在給定城鎮路線上成功行駛的距離以及發生違規的次數。有幾個指標可以讓您全面了解駕駛系統,如下所述:
- 路線完成 (RC):測量車輛可以完成的距離的百分比;
- 違規分數/罰分(IS):是跟蹤違規行為并匯總違規罰分的幾何級數。車輛的起始分數為1.0,然后根據違規處罰進一步降低分數。它衡量客服人員開車不造成違規的頻率;
- 駕駛分數(DS):是一個主要指標,計算為路線完成度與違規處罰的乘積。它衡量按每條路線的違規行為加權的路線完成率。
有評估違規行為的具體指標,每次違規發生時,每個指標都會應用懲罰系數。與行人的碰撞、與其他車輛的碰撞、與靜態元素的碰撞、碰撞布局、紅燈違規、停車標志違規和越野違規是使用的一些指標。
09 數據集和仿真
數據集
在端到端模型中,數據的質量和豐富性是模型訓練的關鍵方面。訓練數據不是使用不同的超參數,而是影響模型性能的最關鍵因素。輸入模型的信息量決定了它產生的結果類型。我們根據傳感器模式(包括攝像頭、激光雷達、GNSS 和動力學)總結了自動駕駛數據集。數據集的內容包括城市駕駛、交通和不同的路況。天氣條件也會影響模型的性能。一些數據集,例如 ApolloScape,捕獲從晴天到下雪的所有天氣條件。表六提供了詳細信息。

仿真和工具集
端到端駕駛和學習管道的標準測試需要先進的軟件模擬器來處理信息并為其各種功能得出結論。此類駕駛系統的試驗成本高昂,而且在公共道路上進行測試受到嚴格限制。模擬環境有助于在道路測試之前訓練特定的算法/模塊。像Carla這樣的模擬器可以根據實驗要求靈活地模擬環境,包括天氣條件、交通流量、道路代理等。模擬器在生成安全關鍵場景方面發揮著至關重要的作用,并有助于模型泛化以檢測和預測 防止此類情況的發生。
表七比較了廣泛使用的端到端驅動管道訓練平臺。MATLAB/Simulink用于各種設置;它包含高效的繪圖函數,并且能夠與其他軟件(例如CarSim])進行聯合仿真,從而簡化了不同設置的創建。PreScan可以模擬現實世界的環境,包括天氣條件,這是MATLAB和CarSim所缺乏的。它還支持MATLAB Simulink接口,使建模更加有效。Gazebo以其高通用性和與ROS的輕松連接而聞名。與CARLA和LGSVL模擬器相比,使用Gazebo創建模擬環境需要機械工作。CARLA和LGSVL提供高質量的模擬框架,需要GPU處理單元以適當的速度和幀速率運行。CARLA基于Unreal引擎構建,而LGSVL基于Unity游戲引擎。該API允許用戶訪問CARLA和LGSVL中的各種功能,從開發可定制的傳感器到地圖生成。LGSVL一般通過各種橋連接到驅動堆棧,而CARLA允許通過ROS和Autoware進行內置橋連接。

10 未來研究方向
- 1)學習魯棒性:目前端到端自動駕駛的研究主要集中在強化學習和模仿學習方法。強化學習通過與模擬環境交互來訓練智能體,而IL則向專家智能體學習,無需進行廣泛的環境交互。然而IL中的分布變化和RL中的計算不穩定等挑戰凸顯了進一步改進的必要性。多任務學習也是一種令人印象深刻的方法,但需要在自動駕駛研究中進一步探索。
- 2)增強安全性:安全性是開發端到端自動駕駛系統的關鍵因素。確保車輛的行為安全并準確預測不確定行為是安全研究的關鍵方面。一個有效的系統應該能夠處理各種駕駛情況,從而提供舒適可靠的交通。為了促進端到端方法的廣泛采用,必須完善安全約束并提高其有效性。
- 3)提高模型可解釋性:可解釋性的缺乏對端到端驅動的發展提出了新的挑戰。然而人們正在不斷努力,通過設計和生成可解釋的語義特征來解決這個問題。這些努力在性能和可解釋性方面都顯示出有希望的改進。盡管如此,設計新穎的方法來解釋導致失敗的模型操作并提供潛在的解決方案還需要進一步的進展。未來的研究還可以探索改進反饋機制的方法,讓用戶了解決策過程并增強對端到端駕駛系統可靠性的信心。
11 結論
在過去的幾年里,由于與傳統的模塊化自動駕駛相比,端到端自動駕駛的設計簡單,人們對它產生了濃厚的興趣。在端到端駕駛研究呈指數級增長的推動下,我們首次對使用深度學習的端到端自動駕駛進行了全面調查。該調查論文不僅有助于理解端到端自動駕駛,而且可以作為該領域未來研究的指南。
我們開發了一種分類法,根據模式、學習和培訓方法對研究進行分類。此外,我們還研究了利用領域適應方法來優化訓練過程的潛力。此外,本文還介紹了一個包含開環和閉環評估的評估框架,可以對系統性能進行全面分析。為了促進該領域的進一步研究和開發,我們編制了公開可用的數據集和模擬器的匯總列表。本文還探討了不同文章提出的有關安全性和可解釋性的潛在解決方案。盡管端到端方法的性能令人印象深刻,但仍需要在安全性和可解釋性方面繼續探索和改進,以實現更廣泛的技術接受。