













為什么編程更關注內存而很少關注CPU?

在知乎上看到一個問題“為什么編程更關注內存而很少關注CPU?”這是一個引人深思的問題。作為一位C#軟件工程師,可以從以下幾個角度來分析為什么編程更關注內存而很少關注CPU。
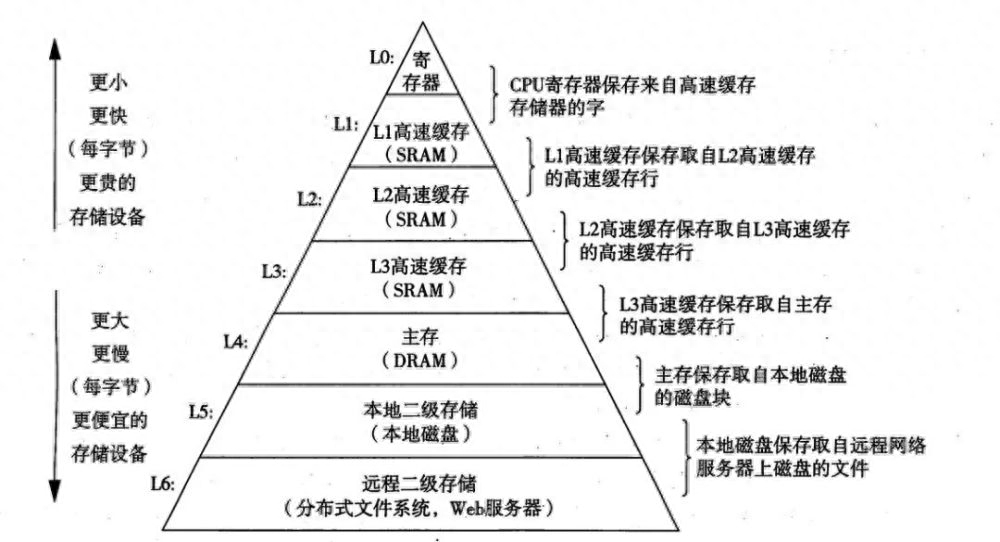
1、內存限制:
內存是程序運行時的關鍵資源之一。在很多場景下,程序需要處理大量的數據,如果不合理地管理內存,可能會導致內存溢出或者性能下降。因此,關注內存的使用情況,進行內存優化是非常重要的。
舉例說明:
在某些工作場景中,我們可能需要處理大型數據集,如讀取和分析大型日志文件、處理大量的數據庫記錄或者進行圖像/視頻處理等。以下是一個在C#中處理大型日志文件的示例,展示了如何合理地管理內存并進行優化。
using System;
using System.IO;
class Program
{
static void Main()
{
string logFilePath = "path/to/logfile.log";
// 使用StreamReader逐行讀取日志文件
using (StreamReader reader = new StreamReader(logFilePath))
{
string line;
while ((line = reader.ReadLine()) != null)
{
// 處理日志行數據
ProcessLogLine(line);
}
}
Console.WriteLine("日志處理完成。");
}
static void ProcessLogLine(string line)
{
// 在這里編寫代碼來處理單行日志數據
// 可能的操作包括解析數據、分析數據、提取有用信息等
// 例如,統計特定事件的發生次數、獲取某個時間段的日志等
// 示例:在控制臺打印日志行
Console.WriteLine(line);
}
}在上述示例中,我們使用StreamReader逐行讀取大型日志文件,而不是一次性將整個文件加載到內存中。這樣可以避免因為文件過大而導致的內存溢出問題。
通過逐行讀取日志文件,我們可以針對每一行數據進行處理,例如解析數據、分析數據或提取有用信息。在ProcessLogLine方法中,我們展示了一個簡單的操作,即在控制臺打印每一行日志。
除了逐行讀取外,我們還應該注意及時釋放不再使用的資源。在讀取大型文件時,可以使用using語句來確保在不再需要時及時釋放StreamReader。
在實際工作中,內存優化的策略和技術取決于具體的場景和需求。例如,在處理大量數據庫記錄時,可以使用分頁查詢、延遲加載等技術來減少內存消耗;在圖像/視頻處理中,可以使用流式處理的方式,避免一次性加載整個文件。
2、內存訪問速度:
相比于CPU,內存的訪問速度較慢。CPU可以通過高速緩存(Cache)來加速數據訪問,但當數據無法在高速緩存中找到時,需要從內存中加載數據,這會引入較大的延遲。因此,減少對內存的訪問次數,提高內存訪問的局部性,可以有效提升程序的性能。
在實際工作場景中,一個常見的情況是處理大量的數據集。例如,在金融領域,我們可能需要對市場交易數據進行分析和計算,以生成報告或者進行決策。這種數據集通常很大,并且需要進行復雜的計算操作。在這樣的情況下,內存訪問的效率對程序的性能起著至關重要的作用。
假設我們正在編寫一個金融數據分析的應用程序,需要對大量的股票交易數據進行移動平均線計算。移動平均線是一種常見的技術指標,用于平滑價格走勢以及預測趨勢的變化。
我們有一個包含數百萬條股票交易數據的數組,每條數據包含日期和價格。我們需要計算每個交易日的5日移動平均線。為了優化內存訪問并提高程序性能,我們可以采取以下策略:
class Program
{
static void Main()
{
// 模擬股票交易數據
List<TradeData> tradeData = new List<TradeData>();
// 初始化股票交易數據...
// ...
int dataSize = tradeData.Count;
int movingAveragePeriod = 5;
// 用于存儲移動平均線結果的數組
double[] movingAverages = new double[dataSize];
// 計算移動平均線
for (int i = 0; i < dataSize; i++)
{
// 檢查是否有足夠的數據進行計算
if (i >= movingAveragePeriod - 1)
{
double sum = 0;
// 計算移動平均值
for (int j = i; j >= i - (movingAveragePeriod - 1); j--)
{
sum += tradeData[j].Price;
}
// 存儲移動平均值
movingAverages[i] = sum / movingAveragePeriod;
}
else
{
// 不足夠的數據,將移動平均線值設為0或其他合適的初始值
movingAverages[i] = 0;
}
}
// 打印移動平均線結果
foreach (double average in movingAverages)
{
Console.WriteLine(average);
}
Console.WriteLine("移動平均線計算完成。");
}
}
// 股票交易數據類
class TradeData
{
public DateTime Date { get; set; }
public double Price { get; set; }
// 其他屬性...
}在這個示例中,我們使用一個TradeData類來表示股票交易數據,包括日期和價格等信息。我們首先創建一個包含數百萬條交易數據的列表tradeData,然后定義了移動平均線的期間為5天。
為了優化內存訪問,我們遍歷每一條數據,并在每個交易日都計算移動平均線。由于移動平均線的計算需要考慮一定的歷史數據,我們利用一個內部循環,從當前交易日往前回溯5天并計算總和,最后除以5得到移動平均值。通過這種方式,我們在計算移動平均線時只訪問了必要的數據,減少了對內存的訪問次數。
需要注意的是,當交易日不足5天時,我們將移動平均線值設為0或其他合適的初始值,以避免對無效數據進行計算。
這個示例展示了如何在工作場景中(金融數據分析)應用內存訪問的優化策略。通過減少內存訪問次數和提高內存訪問的局部性,我們可以顯著提升程序的性能,特別是處理大量數據時。
3、內存泄漏和懸掛引用:
內存管理不當可能導致內存泄漏和懸掛引用的問題。內存泄漏是指程序中存在無法訪問的對象占用內存的情況,這會導致內存占用不斷增加。懸掛引用是指程序中存在被引用但實際上已經不再使用的對象,這些對象仍然被引用,導致GC無法回收它們。因此,關注內存管理,及時釋放不再使用的對象,可以避免這些問題的出現。
內存泄漏和懸掛引用是在程序開發中常見的問題。在實際工作場景中,一個典型的例子是在Web應用程序中使用數據庫連接對象。如果不正確地管理這些連接對象,可能會導致內存泄漏和懸掛引用的問題。
假設我們正在開發一個在線購物網站的后端服務,使用C#編寫。在該網站中,我們需要使用數據庫來存儲用戶的訂單信息。為了與數據庫進行通信,我們需要創建和釋放數據庫連接對象。
以下是一個簡化的示例代碼:
class Program
{
private static List<DbConnection> openConnections = new List<DbConnection>();
static void Main()
{
// 模擬處理用戶訂單的業務邏輯
ProcessOrders();
// 關閉所有數據庫連接
CloseAllConnections();
Console.WriteLine("程序執行完畢。");
}
static void ProcessOrders()
{
// 模擬處理多個訂單
for (int i = 0; i < 1000; i++)
{
// 創建數據庫連接
DbConnection connection = CreateConnection();
// 執行一些數據庫操作...
// ...
// 將連接添加到已打開連接列表中
openConnections.Add(connection);
}
}
static DbConnection CreateConnection()
{
// 創建數據庫連接對象
DbConnection connection = new DbConnection();
// 連接數據庫...
// ...
return connection;
}
static void CloseAllConnections()
{
// 關閉所有數據庫連接
foreach (DbConnection connection in openConnections)
{
// 關閉連接
connection.Close();
}
// 清空連接列表
openConnections.Clear();
}
}
// 模擬數據庫連接類
class DbConnection
{
// 連接數據庫的一些屬性和方法...
// ...
}在這個示例中,我們首先創建了一個靜態變量openConnections,用于存儲所有打開的數據庫連接對象。然后,在處理訂單的業務邏輯中,我們循環創建數據庫連接對象,并執行一些數據庫操作。為了避免內存泄漏和懸掛引用,我們將每個打開的連接對象添加到openConnections列表中。
最后,在程序執行完畢之前,我們通過調用CloseAllConnections方法關閉所有的數據庫連接并清空連接列表。
通過上述代碼,我們有效地管理了數據庫連接對象的生命周期,確保在不使用時及時釋放。這樣可以避免內存泄漏,因為在每次處理訂單的循環中,我們都會創建新的連接對象并添加到openConnections列表中,而在程序結束之前會將所有連接關閉并清空列表。
如果我們沒有正確地管理這些連接對象,可能會導致內存泄漏。例如,如果在處理訂單的循環中未將連接添加到openConnections列表中,那么這些連接對象將無法被正常關閉和釋放,從而占用內存并可能導致內存泄漏。
同樣,如果在程序結束后未關閉連接和清空列表,那么這些連接對象將繼續被引用,無法被垃圾回收器回收,從而導致懸掛引用的問題。
因此,在實際工作場景中,正確地管理和釋放對象是確保程序性能和穩定性的重要一步。及時釋放不再使用的對象可以避免內存泄漏和懸掛引用的問題,提高系統的可靠性和資源利用率。
4、并發和并行:
在多線程和并行編程中,內存訪問往往是一個關鍵的性能瓶頸。多個線程同時訪問共享的內存,可能會引發競態條件和數據一致性的問題。因此,合理地管理內存,使用鎖機制或者其他并發控制手段,可以提高程序的并發性能。
在實際工作場景中,多線程和并行編程經常用于處理大規模數據、提高系統性能和響應速度。然而,當多個線程同時訪問共享的內存時,可能會引發競態條件(Race Condition)和數據一致性問題。為了避免這些問題,需要正確地管理內存訪問,使用鎖機制或其他并發控制手段。
假設我們正在開發一個電子商務網站,需要實現一個庫存管理系統。在這個系統中,多個線程將并發地讀取和更新商品的庫存信息。我們使用C#編寫以下示例代碼來模擬這個場景:
class InventoryManager
{
private Dictionary<string, int> inventory; // 商品庫存信息
private object lockObject; // 鎖對象
public InventoryManager()
{
inventory = new Dictionary<string, int>();
lockObject = new object();
}
public void UpdateStock(string product, int quantity)
{
lock (lockObject) // 使用鎖保證線程安全
{
if (inventory.ContainsKey(product))
{
inventory[product] += quantity;
}
else
{
inventory[product] = quantity;
}
}
}
public int GetStock(string product)
{
lock (lockObject) // 使用鎖保證線程安全
{
if (inventory.ContainsKey(product))
{
return inventory[product];
}
else
{
return 0;
}
}
}
}
class Program
{
static void Main()
{
InventoryManager inventoryManager = new InventoryManager();
// 模擬多個線程并發地更新庫存
Thread t1 = new Thread(() => inventoryManager.UpdateStock("Product A", 10));
Thread t2 = new Thread(() => inventoryManager.UpdateStock("Product B", 5));
t1.Start();
t2.Start();
// 等待兩個線程執行完畢
t1.Join();
t2.Join();
// 輸出商品的最終庫存
Console.WriteLine("Product A stock: " + inventoryManager.GetStock("Product A"));
Console.WriteLine("Product B stock: " + inventoryManager.GetStock("Product B"));
Console.WriteLine("程序執行完畢。");
}
}在這個示例中,我們創建了一個InventoryManager類,用于管理商品庫存信息。在構造函數中初始化了一個字典inventory用來存儲每個商品的庫存數量,并創建了一個對象lockObject作為鎖對象。
UpdateStock方法用于更新商品庫存的數量,它使用lock語句來獲取鎖對象,確保同一時間只有一個線程可以執行該方法。在方法內部,首先檢查字典inventory是否已經包含了該商品的庫存信息,如果存在,則增加數量;否則,將該商品的數量添加到字典中。
GetStock方法用于獲取商品的庫存數量,同樣也使用lock語句來獲取鎖對象,確保線程安全。在方法內部,通過判斷字典inventory是否包含了該商品的庫存信息來返回相應的庫存數量。
在Main方法中,我們創建一個InventoryManager對象,并模擬兩個線程并發地更新庫存。每個線程調用UpdateStock方法來增加商品的數量。然后,通過調用GetStock方法獲取商品的最終庫存數量,并輸出結果。
通過使用鎖機制,即在訪問共享資源前獲取鎖對象,我們可以確保在同一時間只有一個線程能夠訪問和修改共享的內存資源。這樣就避免了競態條件和數據不一致的問題,提高了程序的并發性能和數據的正確性。
需要注意的是,鎖機制可能會引起線程阻塞和性能損失,特別是在高并發情況下。因此,在實際開發中,根據具體情況可以考慮使用更高級的并發控制手段,如使用讀寫鎖(ReaderWriterLock)來允許多個線程同時讀取共享資源,但保證只有一個線程能夠寫入資源。或者使用并發集合類(ConcurrentDictionary、ConcurrentBag等)來管理共享資源,這些類底層已經實現了線程安全的操作。
總之,在多線程和并行編程中,合理地管理內存訪問是確保程序性能和數據正確性的重要一環。使用鎖機制或其他并發控制手段可以有效避免競態條件和數據一致性問題,并提高程序的并發性能。
關注CPU的部分
抽象層次:編程語言和開發框架提供了高層次的抽象,使得開發人員可以更專注于業務邏輯和應用程序的功能實現,而不需要過多關注底層的硬件細節。這種抽象層次的提升使得開發人員能夠更快速地開發軟件,并降低了對CPU的依賴。
多核處理器的普及:隨著多核處理器的普及,現代計算機系統可以同時執行多個線程或進程。這意味著開發人員可以通過并發編程來充分利用多核處理器的性能,而無需過多關注單個CPU的細節。相反,開發人員更關注如何設計并發算法和數據結構,以充分利用多核處理器的性能。
編譯器和運行時優化:編譯器和運行時環境會自動對代碼進行優化,以提高程序的性能。這些優化包括指令重排、內聯函數、循環展開等技術,使得程序在執行時可以更有效地利用CPU的資源。因此,開發人員不需要手動優化代碼以充分利用CPU的性能。
跨平臺和可移植性:現代軟件開發越來越注重跨平臺和可移植性。開發人員希望他們的軟件能夠在不同的操作系統和硬件平臺上運行。為了實現這一目標,他們更傾向于使用高級編程語言和跨平臺的開發框架,這些工具會自動處理不同CPU架構的差異,使得開發人員無需關注底層的CPU細節。
綜上所述,盡管CPU也是程序執行的重要組成部分,但在編程中更關注內存的原因主要包括內存限制、內存訪問速度、內存泄漏和懸掛引用問題以及并發和并行編程的需求。盡管如此,對于一些特定的應用場景,如高性能計算、嵌入式系統、游戲開發等,開發人員可能仍然需要關注CPU的細節,以充分利用硬件資源和提高程序性能。在這些情況下,開發人員可能需要使用底層的編程語言(如匯編語言)或使用特定的優化技術來手動優化代碼。但對于大多數常見的應用程序開發,關注CPU的細節并不是必需的。

















