













微軟小模型擊敗大模型:27億參數,手機就能跑
上個月,微軟 CEO 納德拉在 Ignite 大會上宣布自研小尺寸模型 Phi-2 將完全開源,在常識推理、語言理解和邏輯推理方面的性能顯著改進。

今天,微軟公布了 Phi-2 模型的更多細節以及全新的提示技術 promptbase。這個僅 27 億參數的模型在大多數常識推理、語言理解、數學和編碼任務上超越了 Llama2 7B、Llama2 13B、Mistral 7B,與 Llama2 70B 的差距也在縮小(甚至更好)。
同時,小尺寸的 Phi-2 可以在筆記本電腦、手機等移動設備上運行。納德拉表示,微軟非常高興將一流的小語言模型(SLM)和 SOTA 提示技術向研發人員分享。

今年 6 月,微軟在一篇題為《Textbooks Are All You Need》的論文中,用規模僅為 7B token 的「教科書質量」數據訓練了一個 1.3B 參數的模型 ——phi-1。盡管在數據集和模型大小方面比競品模型小幾個數量級,但 phi-1 在 HumanEval 的 pass@1 上達到了 50.6% 的準確率,在 MBPP 上達到了 55.5%。phi-1 證明高質量的「小數據」能夠讓模型具備良好的性能。
隨后的 9 月,微軟又發表了論文《Textbooks Are All You Need II: phi-1.5 technical report》,對高質量「小數據」的潛力做了進一步研究。文中提出了 Phi-1.5,參數 13 億,適用于 QA 問答、代碼等場景。
如今 27 億參數的 Phi-2,再次用「小身板」給出了卓越的推理和語言理解能力,展示了 130 億參數以下基礎語言模型中的 SOTA 性能。得益于在模型縮放和訓練數據管理方面的創新, Phi-2 在復雜的基準測試中媲美甚至超越了 25 倍于自身尺寸的模型。
微軟表示,Phi-2 將成為研究人員的理想模型,可以進行可解釋性探索、安全性改進或各種任務的微調實驗。微軟已經在 Azure AI Studio 模型目錄中提供了 Phi-2,以促進語言模型的研發。
Phi-2 關鍵亮點
語言模型規模增加到千億參數,的確釋放了很多新能力,并重新定義了自然語言處理的格局。但仍存在一個問題:是否可以通過訓練策略選擇(比如數據選擇)在較小規模的模型上同樣實現這些新能力?
微軟給出的答案是 Phi 系列模型,通過訓練小語言模型實現與大模型類似的性能。Phi-2 主要在以下兩個方面打破了傳統語言模型的縮放規則。
首先,訓練數據的質量在模型性能中起著至關重要的作用。微軟通過重點關注「教科書質量」數據將這一認知發揮到了極致,他們的訓練數據中包含了專門創建的綜合數據集,教給模型常識性知識和推理,比如科學、日常活動、心理等。此外通過精心挑選的 web 數據進一步擴充自己的訓練語料庫,其中這些 web 數據根據教育價值和內容質量進行過濾。
其次,微軟使用創新技術進行擴展,從 13 億參數的 Phi-1.5 開始,將知識逐漸嵌入到了 27 億參數的 Phi-2 中。這種規模化知識遷移加速了訓練收斂,并顯著提升了 Phi-2 的基準測試分數。
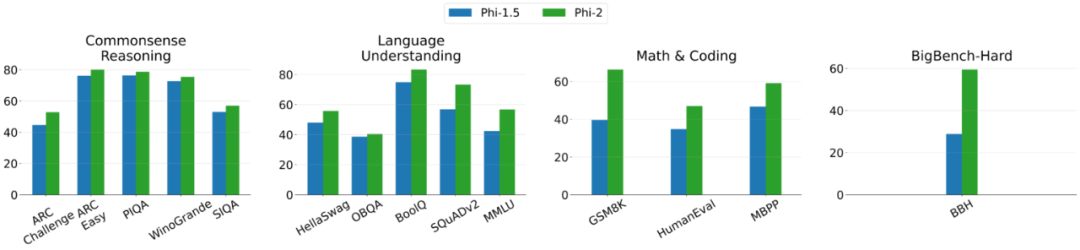
下圖 2 為 Phi-2 與 Phi-1.5 之間的比較,除了 BBH(3-shot CoT)和 MMLU(5-shot)之外,所有其他任務都利用 0-shot 進行評估。
訓練細節
Phi-2 是一個基于 Transformer 的模型,旨在預測下一個單詞,在用于 NLP 與編碼的合成數據集和 Web 數據集上進行訓練,在 96 個 A100 GPU 上花費了 14 天。
Phi-2 是一個基礎模型,沒有通過人類反饋強化學習 (RLHF) 進行對齊,也沒有進行指令微調。盡管如此,與經過調整的現有開源模型相比,Phi-2 在毒性和偏見方面仍然表現得更好,如下圖 3 所示。

實驗評估
首先,該研究在學術基準上對 Phi-2 與常見語言模型進行了實驗比較,涵蓋多個類別,包括:
- Big Bench Hard (BBH) (3 shot with CoT)
- 常識推理(PIQA、WinoGrande、ARC easy and challenge、SIQA)、
- 語言理解(HellaSwag、OpenBookQA、MMLU(5-shot)、SQuADv2(2-shot)、BoolQ)
- 數學(GSM8k(8 shot))
- 編碼(HumanEval、MBPP(3-shot))
Phi-2 僅有 27 億個參數,卻在各種聚合基準上性能超越了 7B 和 13B 的 Mistral 模型、Llama2 模型。值得一提的是,與大 25 倍的 Llama2-70B 模型相比,Phi-2 在多步驟推理任務(即編碼和數學)方面實現了更好的性能。
此外,盡管模型較小,但 Phi-2 的性能可與最近谷歌發布的 Gemini Nano 2 相媲美。
由于許多公共基準可能會泄漏到訓練數據中,研究團隊認為測試語言模型性能的最佳方法是在具體用例上對其進行測試。因此,該研究使用多個微軟內部專有數據集和任務對 Phi-2 進行了評估,并再次將其與 Mistral 和 Llama-2 進行比較,平均而言,Phi-2 優于 Mistral-7B,Mistral-7B 優于 Llama2 模型(7B、13B、70B)。


此外,研究團隊還針對研究社區常用的 prompt 進行了廣泛的測試。Phi-2 的表現與預期一致。例如,對于一個用于測試模型解決物理問題的能力的 prompt(最近用于評估 Gemini Ultra 模型),Phi-2 給出了以下結果:






























