小模型如何比肩大模型,北理工發布明德大模型MindLLM,小模型潛力巨大
大型語言模型 (LLMs) 在各種自然語言任務中展現出了卓越的性能,但是由于訓練和推理大參數量模型需要大量的計算資源,導致高昂的成本,將大語言模型應用在專業領域中仍存在諸多現實問題。因此,北理團隊先從輕量級別模型入手,最大程度發揮數據和模型的優勢,立足更好地服務特定領域,減少下游任務的訓練與推理成本。
10 月 24 日,北京理工大學自然語言處理團隊發布系列雙語輕量級大語言模型明德 (Ming De LLM)——MindLLM,全面介紹了大型模型開發過程中積累的經驗,涵蓋了數據構建、模型架構、評估和應用過程的每個詳細步驟。MindLLM 從頭開始訓練,具有 1.3B 和 3B 兩個版本, 在某些公共基準測試中始終匹配或超越其他開源大型模型的性能。MindLLM 還引入了專為小型模型量身定制的創新指令調整框架,來有效增強其能力。此外,在法律和金融等特定垂直領域的應用,MindLLM 也具有出色的領域適應能力。


- 論文地址:https://arxiv.org/abs/2310.15777
MindLLM 亮點
- 我們分享了數據處理方面的經驗,包括維護高質量和高比例的網絡文本、保留書籍和對話等長期數據、對數學數據進行下采樣,同時對代碼數據進行上采樣。我們建議均勻地打亂數據以進行能力學習,并將一些樣本分塊以用于小樣本學習場景。
- 我們的評估結果優于部分大型模型,在未使用指令微調和對齊時,MindLLM模型 在 MMLU 和 AGIEval 評測上的性能優于 MPT-7B 和 GPT-J-6B 等大型模型。在中文方面,MindLLM 在 C-Eval 和 CMMLU 上表現出與更大參數模型相當的性能。具體來說,MindLLM-3B 在數學能力上優于 MOSS-Base-16B、MPT-7B 等較大模型,在雙語能力上超過 Baichuan2-7B 和 MOSS-Base-16B。而且,MindLLM-1.3B 在數學上比同等大小的 GPT-Neo-1.3B 更好。
- 我們比較了雙語學習中兩種不同的訓練策略,并研究在預訓練期間是否保持數據均勻分布的影響。我們得出的結論,對于容量規模有限的輕量級模型(≤7B)來說,通過預訓練然后遷移訓練的策略來實現數學、推理或雙語對齊等復雜能力并不是最優的,因為整合新知識和現有知識是困難的。相比之下,更有效的策略是從頭開始,結合下游任務的需求,對多種數據類型進行整合,從而確保所需能力能夠穩定且有效地獲取。
- 我們發現在指令調優過程中利用針對特定能力的定制數據,可以顯著增強輕量級模型的特定能力,例如綜合推理能力或學科知識能力。
- 我們介紹了使用基于熵的質量過濾策略構建指令集的方法,并證明了其在過濾輕量級模型的高質量指令調整數據方面的有效性。我們證明,在輕量級模型的背景下,通過改善指令調優數據質量可以更有效地實現模型性能的優化,而不是僅僅增加數據量。
- 我們的模型在特定領域展現出了出色表現,特別是在法律和金融等領域。我們發現模型參數大小的差異不會在特定領域內產生顯著差異,并且較小的模型可以優于較大的模型。我們的模型在特定領域優于參數大小從 1.3B 到 3B 的所有模型,同時與參數大小從 6B 到 13B 的模型保持競爭力,而且模型在特定領域內的分類能力在 COT 方法下顯著增強。
數據相關
數據處理
我們使用英文和中文兩種語言的訓練數據。英文數據源自Pile數據集,經過進一步處理。中文數據包括來自Wudao、CBooks等開源訓練數據,以及我們從互聯網上爬取的數據。為確保數據質量,我們采用了嚴格的數據處理方法,特別是對于從網絡爬取的數據。
我們采用的數據處理方法包括如下幾個方面:
- 格式清洗:我們使用網頁解析器從源網頁中提取和清理文本內容。這一階段包括去除無用的HTML、CSS,JS標識和表情符號,以確保文本的流暢性。此外,我們處理了格式不一致的問題。我們還保留了繁體中文字符,以便我們的模型能夠學習古代文學或詩歌。
- 低質量數據過濾:我們根據網頁中的文本與內容的比例來評估數據質量。具體來說,我們會排除文本密度低于75%或包含少于100個中文字符的網頁。這一閾值是通過對抽樣網頁進行初步測試確定的。
- 數據去重:鑒于WuDao的數據也源自網頁,某些網站可能會重復發布相同的信息。因此,我們采用了局部敏感哈希算法,用以去除重復內容,同時保留了我們訓練數據的多樣性。
- 敏感信息過濾:鑒于網頁通常包含敏感內容,為構建一個積極正向的語言模型,我們采用了啟發式方法和敏感詞匯詞庫來檢測和過濾這些內容。為了保護隱私,我們使用正則表達式來識別私人信息,如身份證號碼、電話號碼和電子郵件地址,并用特殊標記進行替換。
- 低信息數據過濾:低信息數據,如廣告,通常表現為重復內容。因此,我們通過分析網頁文本內容中的短語頻率來鑒別這類內容。我們認為來自同一網站的頻繁重復短語可能對模型學習不利。因此,我們的過濾器主要關注廣告或未經認證的網站中的連續重復短語。
最終我們獲得了數據如下表:

Scaling Law
為了確保在深度學習和大型語言模型的訓練成本不斷增加的情況下獲得最佳性能,我們進行了數據量和模型容量之間的關系研究,即Scaling Law。在著手訓練具有數十億參數的大型語言模型之前,我們首先訓練較小的模型,以建立訓練更大模型的擴展規律。我們的模型大小范圍從1千萬到5億參數不等,每個模型都在包含高達100億tokens的數據集上進行了訓練。這些訓練采用了一致的超參數設置,以及前文提到的相同數據集。通過分析各種模型的最終損失,我們能夠建立從訓練FLOP(浮點運算數)到Loss之間的映射。如下圖所示,不同大小的模型飽和的訓練數據量不同,隨著模型大小的增加,所需的訓練數據也增加。為了滿足目標模型的精確數據需求,我們使用了冪律公式來擬合模型的擴展規律,并預測出3B參數模型的訓練數據量與Loss數值,并與實際結果進行對照(圖中星標)。

數據混雜與數據課程
數據對模型的影響主要涵蓋兩個方面:(1)混合比例,涉及如何將來自不同來源的數據組合在一起,以在有限的訓練預算下構建一個特定大小的數據集;(2)數據課程,涉及來自不同來源的數據的排列方式,以訓練模型特定的技能。
我們將每個數據來源等比例縮小,用于訓練15M參數量的模型。如下圖所示,不同類型的數據對學習效率和模型最終結果有不同的影響。例如,數學題數據的最終損失較低,學習速度較快,表明它具有更為明顯的模式且容易學習。相比之下,來自信息豐富的書籍或多樣化的網絡文本的數據需要更長的適應時間。一些領域相似的數據可能在損失上更為接近,例如技術相關數據和百科全書。
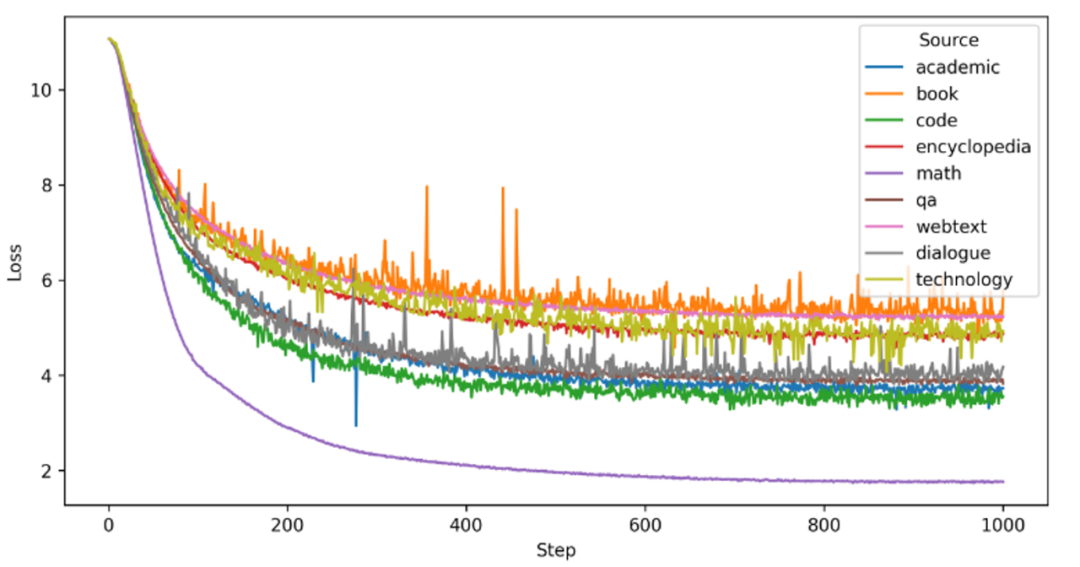
為了進一步探究模型從單一數據泛化到其他數據的性能,我們使用這些在單一數據上訓練好的模型在其他數據上進行測試,結果如下圖所示:

不同數據集展現出不同程度的泛化能力,例如:網頁文本、百科全書和問答數據訓練的模型在多個數據源上展現出較強的泛化能力,表明它們的內容包含了各個領域的多樣信息。相比之下,學術論文數據和代碼數據訓練的模型在數學能力上表現出色,但在泛化方面較弱,可能是由于領域特定性和獨特的格式信息。
此外,我們進行了多次的數據比例調整,以平衡模型在各種技能和數據類型之間的表現。基于我們的實驗,我們最終確定了數據混合比例的一些原則:
- 保持高質量網絡文本和百科全書數據的比例,因為它們具有多樣性。
- 降低數學數據的比例,以避免過擬合。
- 利用代碼和學術數據來增強數學能力,同時通過多樣化的抽樣和相關處理減輕格式的影響。
- 保留一些對話和書籍數據,有助于學習長程依賴關系。
除了混合比例,數據課程(數據的訓練順序)也會影響模型的能力學習。實驗表明,不同來源的數據將使模型學習不同的技能,由于技能之間的相關性,采用特定的學習順序可能有助于模型學習新的技能。我們的實驗集中于非均勻混合數據和語言遷移學習對模型能力的影響。我們的實驗表明,非均勻混合數據會導致模型在同一類型數據上進行連續訓練,這更接近于上下文內學習的情境,因此在少樣本學習方面表現更好;然而,由于學習的不均勻性,后期可能會出現明顯的遺忘現象。此外,語言遷移學習有助于模型獲得雙語能力,通過語言對齊可能提高整體性能,但我們認為使用混合語言數據進行訓練更有利于模型能力的分配與習得。
MindLLMs 模型架構
MindLLM-1.3B采用的是GPTNeo-1.3B相同的模型架構,而MindLLM-3B則是在此基礎上增加了一些改進。基于訓練穩定性和模型能力方面的考慮,我們使用旋轉位置編碼(RoPE)DeepNorm、RMS Norm、FlashAttention-2、GeGLU等優化算子。
我們在GPTNeo-1.3B的基礎上增加了中文詞表,并采用遷移學習的策略訓練MindLLM-1.3B的雙語能力。而MindLLM-3B,我們則是使用來自SentencePiece的BPE來對數據進行分詞,我們的Tokenizer的最終詞匯量大小為125,700。通過兩種不同的雙語訓練方式,我們總結了一些普遍實用的預訓練方法。
預訓練
預訓練細節
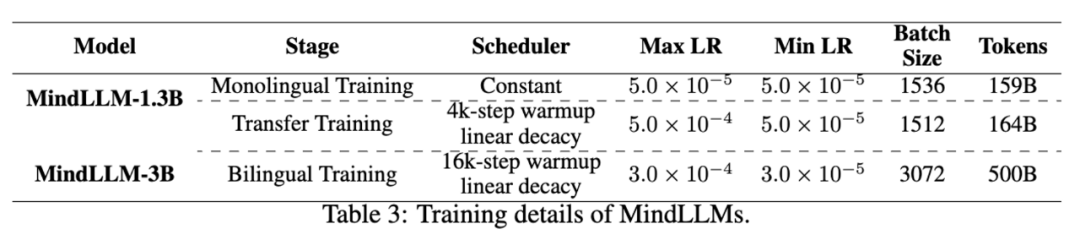
我們使用了兩種不同的策略從頭訓練雙語模型MindLLM。對于MindLLM-3B,我們直接在混合的中英文雙語數據上預訓練了800,00步,同時學習中英文能力;對于MindLLM-1.3B,我們首先在英文數據集上進行預訓練101,100步,然后使用中英文混合數據訓練了105,900步。預訓練細節如下:
預訓練階段評估
較小的模型可以擊敗更大的模型
為評估模型的中英文能力,我們使用MMLU(5-shot)和AGIEval(4-shot)評估模型英文能力,使用C-Eval(5-shot)和CMMLU(4-shot)評估模型的中文能力。其中AGIEval采用英文部分的多選題部分。評估結果如下:

在英文表現上,MindLLMs平均水平超過了GPT-J-6B,MPT-7B,MOSS-Base-16B等更大的模型,并接近Falcon-7B,而后者均有更大的模型規模和更多的預訓練數據。在中文能力上,MindLLMs則和開源的LLMs表現相當。值得說明的是,目前MindLLMs仍在訓練增強中。
此外,我們發現數據量更少,但是使用了中英文數據訓練的MindLLM-1.3B在MMLU上的表現優于GPT-Neo-1.3B,我們推測這可能是雙語學習帶來的增益,因為不同語種在能力之間也存在共通性。詳細實驗和分析可查看論文4.4節。
較小的模型在具體能力上存在巨大的潛力
對于輕量級模型,在應用于下游任務時,只需要存在相關的能力上展現出出色的表現即可。因此,我們本部分想要探究MindLLMs和其他輕量級LLM在(≤7B)具體能力上的表現和影響因素。
我們主要從數學能力、推理能力和雙語對齊能力三個角度評估不同模型表現,因為這三種能力復雜且對于雙語模型的應用相對重要。
(1) 數學
我們使用Arithmetic(5-shot)數據集評估模型的算數能力,使用GSM8K(4-shot)和MATH(4-shot)評估模型的通用數學能力。評估結果如下:

我們發現,MindLLM-3B在數學能力上的平均分數達到了16.01,超過了MOSS-Base-16B(15.71)和MPT-7B(13.42),GPT-J-6B(13.15)。此外MindLLM-1.3B的數學平均水平也超過了相同大小的GPT-Neo-1.3B。以上結果表明,輕量級模型在數學上有著巨大的潛力,較小的模型也可以在具體領域表現出超越或者與更大模型相當的水平。進一步,我們可以看到數學能力較為出色的(均分≥15),除MindLLM-3B,均為7B左右的模型。這表明,如數學能力類似的復雜能力的全面獲取可能會收到模型規模的限制,這一猜測可以進一步在模型雙語能力和推理能力的評估進一步體現。
(2) 推理
我們使用HellaSwag、WinoGrande評估模型語言推理能力(5-shot),使用LogiQA評估模型邏輯推理能力(5-shot),使用PubMedQA、PIQA、MathQA評估模型知識推理能力(5-shot),使用BBH評估模型綜合推理能力(3-shot)。具體評估結果如下:

首先,在模型容量有限的條件下,雙語帶來的能力增益可能需要和語言學習對模型能力容量的消耗進行平衡。語言學習會占據部分模型能力容量,使得復雜能力如推理能力可能無法全面獲取。比如MindLLM-1.3B在英文MMLU評估指標上均優于GPT-Neo-1.3B,但在推理能力的平均水平上弱于后者(35.61 vs 38.95)。而Blooms的推理能力沒有特別出色,但后續評估的雙語能力出色,這也一定程度上印證了以上觀點。其次,規模越大的預訓練數據集可能包含的世界知識更多,這樣邊有助于模型進行推理任務,例如Open-LLaMA-3B的推理表現和較大的模型表現相當,而其預訓練數據為1T B,超過了其它同規模的模型所使用的預訓練數據。因此,較小規模的模型依舊能夠有潛力在推理能力上獲得和較大模型相當的表現。另外,我們發現MOSS在推理上的水平似乎沒有從前期代碼數據的學習獲得增益而表現更好(MOSS在CodeGen上進行了繼續訓練),但相關工作表明,代碼確實有利于模型推理能力的提升,那么到底代碼數據如何以及何時加入訓練來增強模型的推理能力值得進一步探討。
(3) 雙語能力
我們使用Flores-101(8-shot)中的zh-en部分評估雙語或者多語模型在中英文上的對齊能力。我們加入Chinese-LLaMA-2-7B進行評估,其為在LLaMA-2-7B基礎上進行中文領域適應的模型。結果如下所示:

我們發現,模型在英文到繁體中文的翻譯表現均不佳,這主要是預訓練數據中的繁體中文占比很少。除此外,只有Blooms和MindLLM-3B在中文到英文和英文到中文雙向的語言對齊上表現出色,其次為LLaMA-2-7B和MOSS-Base-16B。而LLaMA-7B和Open-LLaMA-7B則只能在中文到英文上對齊。結合模型預訓練的數據可以知道,Blooms和MindLLM-3B的預訓練數據中中英文比例較平衡,而LLaMA-2-7B中中文數據比例遠低于英文,在LLaMA-7B和Open-LLaMA-7B的預訓練數據中中文比例更少。
因此,我們有兩個結論,其一是模型可以通過在某種語言上進行大量的訓練學習到通過的語言表示,同時混入少量的另一種語言就可以理解并進行單向對齊,如LLaMA-7B和Open-LLaMA-7B的表現。其二則是,若需要獲得更好的雙語或多語對齊能力,那么在預訓練開始階段就需要有較平衡的雙語或多語數據比例,如Blooms和MindLLM-3B。進一步,我們發現MOSS-Base-16B和Chinese-LLaMA-2-7B存在較合理的中英文數據比例,單依舊沒有表現出雙向對齊,我們的假設是雙語對齊能力在遷移訓練的時候加入是困難的,因為此時的模型已經存在了大量的知識,這在容量較小的情況下會產生矛盾沖突。這也解釋了容量更小,前期單語訓練的數據量少的MindLLM-1.3B也沒有獲得雙語對齊能力的現象。而Baichuan2-7B在其他表現方面非常出色,可能也就占據了較大的能力容量,無法學習到較好的雙向對齊能力。
(4) 總結
通過評估預訓練階段的評估結果,我們有一下兩個結論:
- 輕量級模型在特定的領域或者能力上有巨大的潛力超過或者達到更大模型的水平。
- 對于容量有限的模型(≤7B),我們可以在預訓練數據中根據下游任務的具體能力需求合理分配數據比例,這樣有利于模型從頭穩定地學習獲取目標能力,并進行不同知識與能力的融合和促進。
此外,論文中還對比了是否保持數據均勻分布對模型預訓練性能的影響,實驗結果顯示類似課程學習的數據構造方式可能在前期和均勻混合的數據構造方式下訓練的模型表現相當,但是最終可能出現災難性遺忘而導致表現突然下降,而后者表現則更持續穩定,獲取的預訓練數據知識也更加全面,這也佐證了以上第二點結論。另外我們發現類似課程學習的數據構造方式可能產生更多有利于增強模型上下文學習能力的數據分布。具體細節可以查看論文4.5部分。
指令微調
我們想要探討在輕量級模型上,不同類別數據集的指令微調會有什么樣的性能表現。下表是我們使用的指令微調數據集,包含我們重新構造的中文數據集MingLi、公開數據集Tulu(英文)和中英雙語數據集MOSS。

對于MindLLM來說,指令微調的數據質量要比數據數量更加重要。
MindLLM-1.3B和MindLLM-3B模型在不同數據下指令微調后在C-Eval上的性能表現如下。從實驗結果看,使用精心挑選的50,000條指令微調數據集訓練的模型性能要高于多樣性高、數據量大的指令微調數據集訓練的模型性能。同樣,在英文指標MMLU上,模型也表現出相同的性能(詳見論文Table 14)。因此,對于輕量級模型來說,如何定義和篩選出高質量的指令微調數據集是非常重要的。

基于數據熵的指令微調數據篩選策略
如何定義高質量的指令微調數據?有學者提出指令微調數據的多樣性可以代表指令微調數據集的數據質量。然而根據我們的實驗發現,指令微調的數據熵和數據長度會更加影響輕量級模型的性能。我們將每條數據在預訓練模型上的交叉熵損失定義為該數據的數據熵,并通過K-Means算法依據數據熵對數據進行聚類得到不同的數據簇。MindLLM經過每個數據簇的指令微調后再C-Eval的結果如下表所示(MMLU的結果詳見論文Table19):

依據表中結果可知,MindLLM-1.3B和MindLLM-3B在不同數據簇上的表現相差明顯。進一步的,我們對數據熵和模型在C-Eval和MMLU上的準確率的關系進行和函數擬合分析,如圖所示:

圖像中紅色五角星的點為預訓練模型的熵值。根據分析可知,當數據的熵比預訓練模型的熵高1-1.5時,模型經過該區間的數據指令微調后性能最佳。因此,我們通過數據熵定義了高質量數據,并且提出了篩選高質量數據的方法。
MindLLM可以經過指定指令微調數據集獲得特定能力
為了探究MindLLM能否經過指令微調有效的提升其特定能力,我們使用萬卷數據集中的exam數據部分微調模型,目的是為了增強模型的學科知識能力。我們在C-Eval上進行了評估,結果如下:

可以看到,經過指令微調之后,模型在學科知識能力上有了很大的提升,1.3B的MindLLM的性能甚至超過ChatGLM-6B、Chinese-Alpaca-33B等更大規模的模型。因此我們認為MindLLM在指令微調后可以提升其特定能力,又鑒于其輕量級的特點,更適合部署在下游垂直領域任務之中。
領域應用
為了展示小模型在具體領域應用的效果,我們采用了在金融和法律兩個公開數據集來做出驗證。從結果中可以觀察到,模型的參數大小對領域性能有一定影響,但表現并不明顯。MindLLM的性能在領域應用內超越了其它同等規模的模型,并且與更大的模型有可比性。進一步證明了小模型在領域應用落地有極大潛力。
金融領域
在該領域,對金融數據進行情緒感知分類任務。首先,我們從東方財富網爬取了2011年5月13日至2023年8月31日的數據,并根據接下來的股價波動對數據進行了標記。隨后,按照日期將數據劃分為訓練集和測試集。考慮到類別的不平衡性,我們對數據進行了采樣,最終使用了32萬條數據作為訓練集,而測試集則采用了2萬條數據。

我們通過兩種不同的訓練方法來比較不同模型的表現。第一,僅適用簡單的監督微調(Supervised Fine-Tuning, SFT)對文本進行分類訓練。第二,從ChatGPT中蒸餾推理過程數據,并將其作為輔助數據添加到訓練中,具體采用了COT(Chain-Of-Thought)訓練方式。

實驗結果表明,通過補充輔助信息,可以在不同程度上提升所有baseline模型和MindLLM模型效果。進一步可觀察到,COT 訓練使得 MindLLM-1.3B 和 3B 的性能比 SFT訓練性能分別提高了 27.81% 和 26.28%,除了Baichuan-7B以外,MindLLM比其他模型提高幅度更加顯著。此外,MindLLM-1.3B 和 3B 在相同規模下達到了最佳性能,而且超過了 ChatGLM2-6B 和 Open-LLaMA-7B。
法律領域
我們收集了一些公開的法律相關數據,并結合了一些通用指令數據對 MindLLM 進行指令微調 (SFT)。為了探究數據的 token 長度是如何影響模型在具體領域上的性能的,我們使用不同數據長度的數據來分別訓練 MindLLM。我們首先篩選了長度小于450的全部數據,然后分別使用 MindLLM-1.3B 和 MindLLM-3B 的Tokenizer篩選出長度在200-300和300-450之間的數據。數據統計和所對應的訓練模型如下表所示:

為了避免人類評估產生的偏差和專業知識不足造成的錯誤,我們使用采用chatgpt作為評估器,具體方法如下。由ChatGPT生成的多輪法律咨詢對話數據集,提取了其中100個對話作為我們的評估數據。我們使用ChatGPT來評估模型對于法律咨詢的回復,讓ChatGPT對于模型的回復進行排序,再根據排序結果計算Elo分數。最終篩選出一個最佳模型作為 MindLLM-Law 和其它開源模型相比較。
對于 Bloom,GPT-Neo 和 Open-LLaMA 模型使用了和 MindLLM-Law 一樣的數據集進行了微調,比較結果如下所示:

結果顯示 MindLLM-Law 尚未超越具有 13B 參數的模型和 ChatGLM2-6B,其主要原因是我們在預訓練階段法律方面數據不足,未能帶來更大的增益。但是,MindLLM相較于 Baichuan2-7B-Chat、微調后的 Open-LLaMA-7B 和其他同規模模型來講,整體優勢非常明顯。
總結
本文介紹了 MindLLM 系列模型,目前包括兩款輕量級大語言模型。我們詳細探討了它們的訓練過程,包括數據處理、預訓練、微調、以及領域應用,分享了在這些領域所積累的寶貴經驗和技術應用。盡管 MindLLM 的參數規模相對較小,但它們在多個性能評測中表現出色,甚至在某些方面超越了一些更大體量的模型。MindLLM 在領域適應方面相對于其他輕量模型表現出更卓越的性能。同時,與更大規模的模型相比,它們能夠以更快的訓練速度和更少的訓練資源取得相當的成績。基于以上分析,我們認為小模型仍然具有極大的潛力。我們將進一步提升數據質量,優化模型訓練過程和擴展模型規模,以多維度方式提升 MindLLM 的性能。未來,我們計劃在更多下游任務和特定領域進行嘗試,以更深入地實現輕量級大模型的具體應用。