













走近Kafka:大數(shù)據(jù)領(lǐng)域的不敗王者
一、引言
1.背景
和 RabbitMQ 類似,Kafka(全稱 Apache Kafka)是一個(gè)分布式發(fā)布-訂閱消息系統(tǒng)。
自 Apache 2010 年開源這個(gè)頂級(jí)實(shí)用項(xiàng)目以來,至今已有十?dāng)?shù)年,Kafka 仍然是非常熱門的一個(gè)消息中間件,在互聯(lián)網(wǎng)應(yīng)用里占據(jù)著舉足輕重的地位。
甚至,技術(shù)圈一度將 Kafka 評(píng)為消息隊(duì)列大數(shù)據(jù)領(lǐng)域中的最強(qiáng)王者!
Kafka 以其速度快(ms 級(jí)的順序?qū)懭牒土憧截悾⑿阅芨撸═B級(jí)的高吞吐量)、高可靠(有熱擴(kuò)展,副本容錯(cuò)機(jī)制能力)和高可用(依賴Zookeeper作分布式協(xié)調(diào))等特點(diǎn)聞名于世,它非常適合消息、日志和大數(shù)據(jù)業(yè)務(wù)的存儲(chǔ)和通信。
本文接下來將會(huì)從下載安裝,配置修改,收發(fā)消息等理論和實(shí)踐入手,帶大家一起探索 kafka 的核心組件,以及業(yè)務(wù)中常見的數(shù)據(jù)消費(fèi)問題。

二、kafka下載與安裝
1.前提條件
由于 kafka 需要 JDK 環(huán)境來收發(fā)消息,并通過 ZooKeeper 協(xié)調(diào)服務(wù),將 Producer,Consumer,Broker 等結(jié)合在一起,建立起生產(chǎn)者和消費(fèi)者的訂閱關(guān)系,實(shí)現(xiàn)負(fù)載均衡。
所以安裝 kafka 之前,我們需要先:
- 安裝 JDK
- 安裝 Zookeeper
網(wǎng)上安裝教程很多,而本文主要探討 kafka,所以就不再這里給出 JDK 和 zk 的詳細(xì)安裝步驟了。
2.下載安裝
安裝 Kafka 時(shí),主要有以下兩種方式(更推薦使用 docker 安裝):
- 虛機(jī)安裝官網(wǎng)下載 kafka 壓縮包 [https://kafka.apache.org/downloads],或者使用 docker 下載解壓縮至如下路徑 /opt/usr/kafka 目錄下。
- docker安裝(需先在虛機(jī)上安裝 docker):
# 拉取鏡像,默認(rèn)最新版本
docker pull bitnami/kafka
# 創(chuàng)建網(wǎng)絡(luò)環(huán)境,保證zk和kafka在同一個(gè)網(wǎng)絡(luò)中
docker network create kafka-network
# 運(yùn)行zookeper
docker run -d --name zookeeper --network kafka-network bitnami/zookeeper:latest
#運(yùn)行kafka,其中:環(huán)境變量KAFKA_CFG_ZOOKEEPER_CONNECT指定ZooKeeper的連接信息,KAFKA_CFG_ADVERTISED_LISTENERS是Kafka對(duì)外的訪問地址
docker run -d --name kafka --network kafka-network \
-e KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \
-p 9092:9092 \
bitnami/kafka:latest3.修改配置文件
進(jìn)入目錄 /opt/usr/kafka/config,如果是 docker 安裝方式,需先用命令 docker exec -it containerID bash 進(jìn)入容器,修改 server.properties 文件:
#broker.id屬性在kafka集群中必須要是唯?
broker.id=0
#kafka部署的機(jī)器ip和提供服務(wù)的端?號(hào),根據(jù)自己服務(wù)器的網(wǎng)段修改IP
listeners=PLAINTEXT://192.168.65.60:9092
#kafka的消息存儲(chǔ)?件
log.dir=/opt/usr/data
#kafka連接zookeeper的地址,根據(jù)自己服務(wù)器的網(wǎng)段修改IP
zookeeper.connect=192.168.65.60:2181三、啟動(dòng)Kafka
1.啟動(dòng) kafka 服務(wù)器
進(jìn)入 /opt/kafka/bin 目錄下,使用命令啟動(dòng):
./kafka-server-start.sh -daemon ../config/server.properties使用 ps -ef |grep server.properties 命令查看是否啟動(dòng)成功

2.啟動(dòng) Zookeeper
查看 zookeeper 是否正常添加好節(jié)點(diǎn),首先,進(jìn)入 zookeeper 的某一個(gè)容器內(nèi)【這里進(jìn)的是 zookeeper:zoo1 節(jié)點(diǎn)】
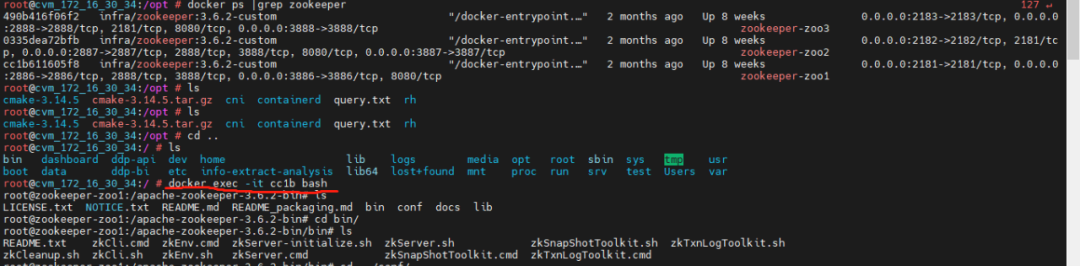
進(jìn)入 bin 目錄下,使用 zkCli.sh 命令,啟動(dòng)客戶端
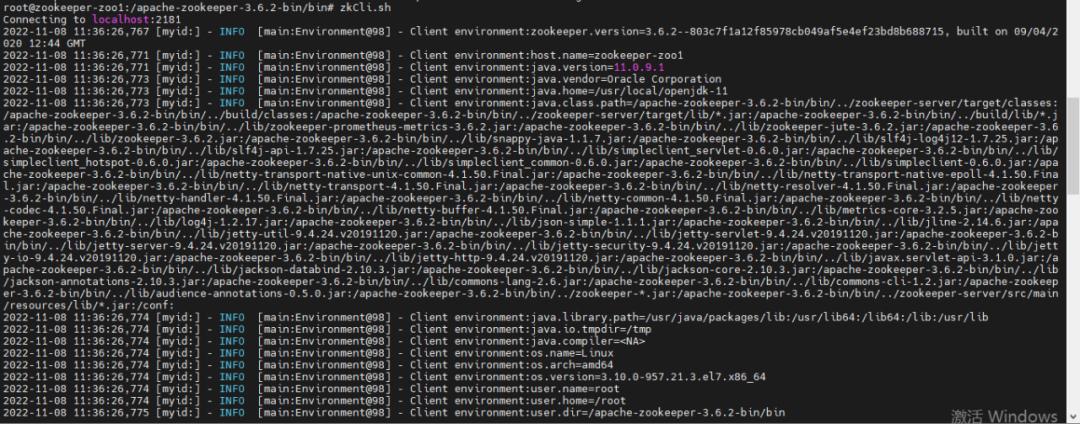
3.判斷是否正常啟動(dòng)
使用 ls /brokers/ids 命令查詢對(duì)應(yīng)的 kafka broker:

如果看到有對(duì)應(yīng)的 broker.id,如上圖的 1,2,3,就說明已經(jīng)啟動(dòng)成功了!
如果有啟動(dòng)報(bào)錯(cuò),一般是 server.properties 配置文件有誤:比如,broker Id 不唯一,IP 端口不正確導(dǎo)致。
四、Kafka常見概念與核心組件
以下是 Kafka 中的一些核心組件:
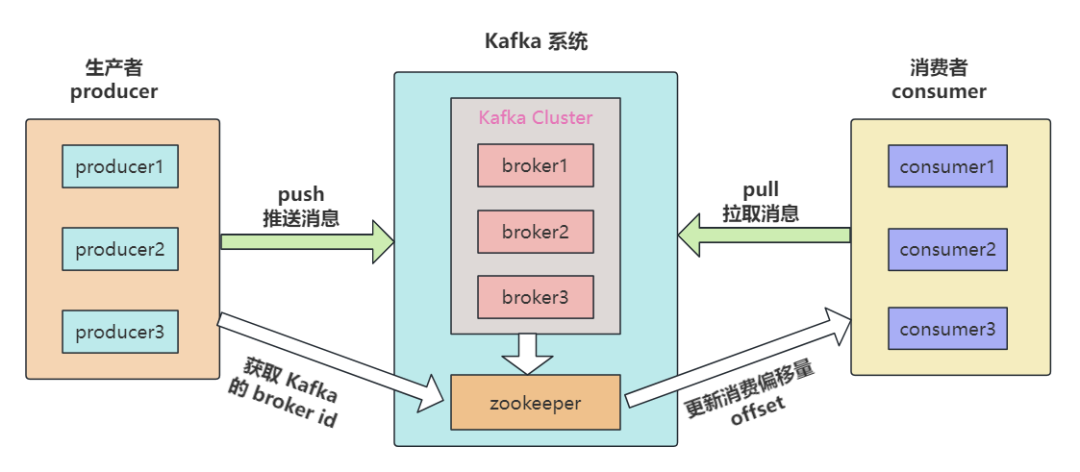
名稱 | 解釋 |
Broker | Kafka 集群中的消息處理節(jié)點(diǎn),?個(gè) Kafka 節(jié)點(diǎn)就是?個(gè) broker,broker.id 不能重復(fù) |
Producer | 消息生產(chǎn)者,向 broker 發(fā)送消息的客戶端 |
Consumer | 消費(fèi)者,從 broker 讀取消息的客戶端 |
Topic | 主題,Kafka 根據(jù) topic 對(duì)消息進(jìn)?歸類 |
Partition | 分區(qū),將一個(gè) topic 的消息存放到不同分區(qū) |
Replication | 副本,分區(qū)的多個(gè)備份,備份分別存放在集群不同的 broker 中 |
1.主題Topic
(1) 什么是Topic
Topic 在 kafka 中是一個(gè)邏輯概念,kafka 通過 topic 將消息進(jìn)行分類,消費(fèi)者需通過 topic 來進(jìn)行消費(fèi)消息。
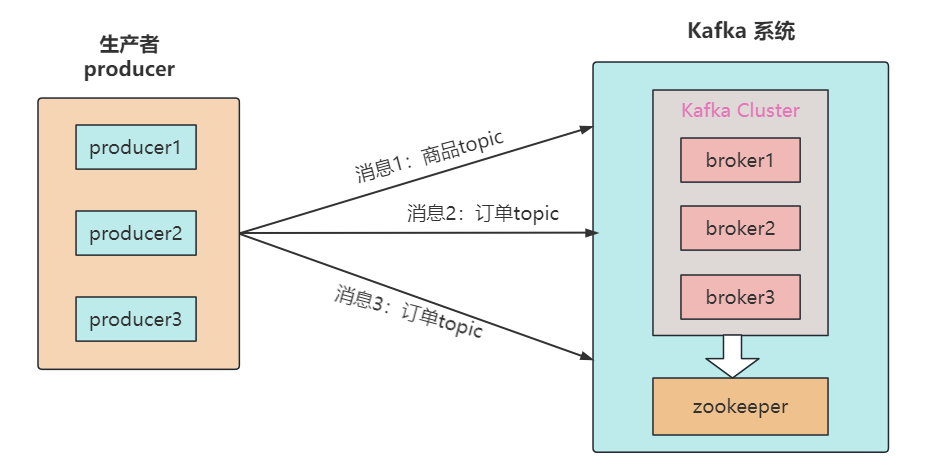
注意:發(fā)送到 Kafka 集群的每條消息都需要指定?個(gè) topic,否則無法進(jìn)行消費(fèi)。
(2) 如何創(chuàng)建Topic
我們可以通過以下命令創(chuàng)建一個(gè)名為 hello-world 的 topic,在創(chuàng)建 topic 時(shí)可以指定分區(qū)數(shù)量和副本數(shù)量。
# 創(chuàng)建 topic
./kafka-topics.sh --create --zookeeper 172.16.30.34:2181 --replication-factor 1 --partitions 1 --topic hello-world
# 通過命令查看 zk 節(jié)點(diǎn)下所有的主題
./kafka-topics.sh --list --zookeeper 172.16.30.34:2181以下是在 docker 容器里創(chuàng)建 topic 的例子:

(3) 查看 topic 的具體信息
我們可以通過以下命令來查看名為 my-replicated-topic 這個(gè)主題的詳細(xì)信息:
./kafka-topics.sh --describe --zookeeper 172.16.30.34:2181 --topic my-replicated-topic可以看出該 topic 的名稱,分區(qū)數(shù)量,副本數(shù)量,以及配置信息等:

并且,我們也可以直接在 zookeeper 客戶端查看已創(chuàng)建的主題,通過以下命令查看:
# 進(jìn)入客戶端
./bin/zkCli.sh
# 查看主題
ls /brokers/topics
get /brokers/topics/hello-world可以看到,hello-world 主題已經(jīng)被創(chuàng)建成功了:

2.Partition 分區(qū)
由于單機(jī)的 CPU、內(nèi)存和磁盤等瓶頸,因此引入分區(qū)概念,類似于分布式系統(tǒng)的橫向擴(kuò)展。
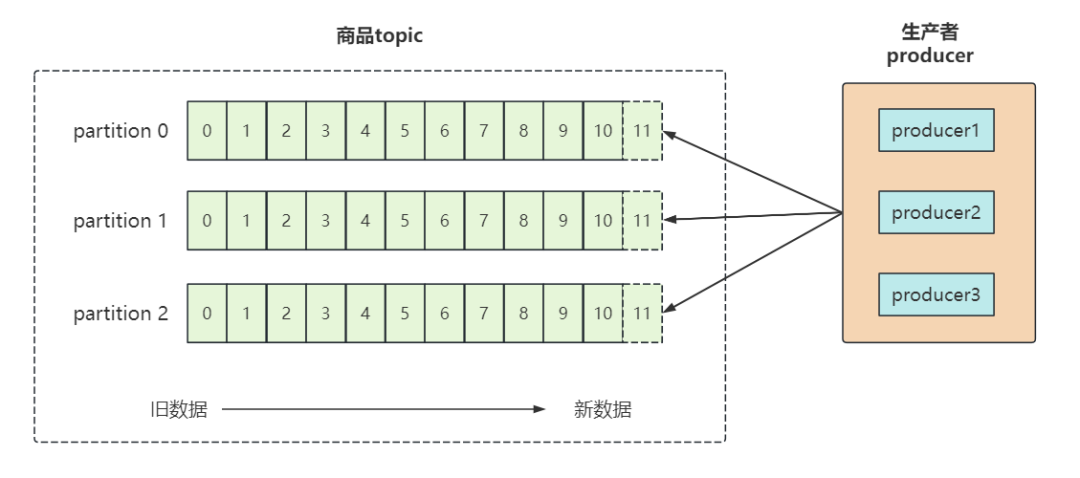
通過分區(qū),一個(gè) topic 的消息可以放在不同的分區(qū)上,好處是:
- 分離存儲(chǔ):解決一個(gè)分區(qū)上日志存儲(chǔ)文件過大的問題;
- 提高性能:讀和寫可以同時(shí)在多個(gè)分區(qū)上進(jìn)行,方便擴(kuò)展和提升并發(fā)。
創(chuàng)建多分區(qū)的主題
以下命令創(chuàng)建一個(gè)名稱為 hello-world 的 topic,指定 zookeeper 內(nèi)網(wǎng)節(jié)點(diǎn)地址為:172.16.30.34:2181(注意:如果在自己的內(nèi)網(wǎng)機(jī)器上部署,這個(gè)地址需要改成自己的服務(wù)器 IP)。
--partitions 3:指定分區(qū)數(shù)量為 3
# 創(chuàng)建topic,replication-factor副本數(shù)為3,partitions分區(qū)數(shù)為1
./kafka-topics.sh --create --zookeeper 172.16.30.34:2181 --replication-factor 1 --partitions 3 --topic hello-world3.Replication 副本
副本,就是主題中分區(qū)創(chuàng)建的多個(gè)備份,多個(gè)備份在 kafka 集群的多個(gè) broker 中,會(huì)有一個(gè) leader,多個(gè) follower。
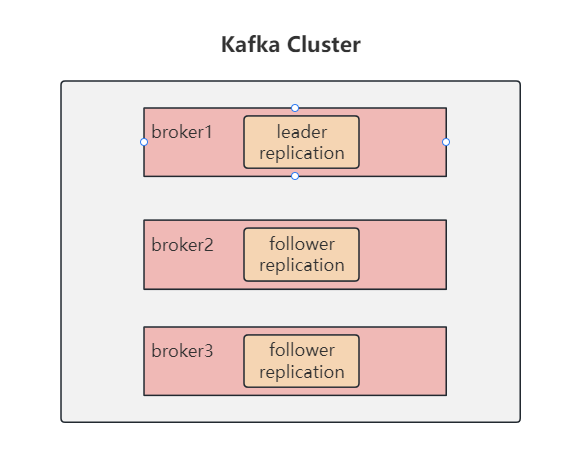
副本類似于冗余的意思,是保障系統(tǒng)高可用的有效應(yīng)對(duì)方案。
指定副本數(shù)量
當(dāng)新建主題時(shí),除了可指定分區(qū)數(shù),還可以指定副本數(shù)。
--replication-factor 3:指定副本數(shù)量為 3
# 創(chuàng)建topic,replication-factor副本數(shù)為3,partitions分區(qū)數(shù)為1
./kafka-topics.sh --create --zookeeper 172.16.30.34:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic五、在Kafka中收發(fā)消息
1.發(fā)送消息
當(dāng)創(chuàng)建完 topic 之后,我們可以通過 kafka 安裝后自帶的客戶端工具 kafka-console-producer.sh,向已創(chuàng)建的主題中發(fā)消息:
# 打開hello-world主題的消息發(fā)送窗口
./kafka-console-producer.sh --bootstrap-server 172.16.30.34:49092 --topic hello-world消息發(fā)送窗口打開后,向 hello-world 主題中發(fā)送消息:

2.消費(fèi)消息
當(dāng)消息發(fā)送成功后,我們新開一個(gè)窗口,通過 kafka 安裝后自帶的客戶端工具 kafka-console-consumer.sh 創(chuàng)建一個(gè)消費(fèi)者,并監(jiān)聽 hello-world 這個(gè) topic,以消費(fèi)消息:
# 打開hello-world主題的消息消費(fèi)窗口
./kafka-console-consumer.sh --bootstrap-server 172.16.30.34:49092 --topic hello-world在 kafka 中,消費(fèi)者默認(rèn)從當(dāng)前主題的最后一條消息的 offset(偏移量位置)+1 位置開始監(jiān)聽,所以當(dāng)消費(fèi)者開始監(jiān)聽時(shí),只能收到 topic 之后發(fā)送的消息:

從頭開始消費(fèi)
這時(shí),如果 topic 消息已經(jīng)發(fā)送有一會(huì)了,但我們想要從頭開始消費(fèi)該怎么辦呢?
只需要在開啟消費(fèi)者監(jiān)聽時(shí),加一個(gè) --from-beginning 命令即可:
# 從當(dāng)前主題的第一條消息開始消費(fèi)
./kafka-console-consumer.sh --bootstrap-server 172.16.30.34:49092 --from-beginning --topic hello-world從第一條消息開始消費(fèi):

六、消息收發(fā)相關(guān)
1.消息的存儲(chǔ)和順序性
生產(chǎn)者將消息發(fā)給 broker,broker 會(huì)將消息保存在本地的日志文件中。
在 config 文件中,日志目錄為 /opt/usr/data,文件名為 主題-分區(qū)/00000000.log。
在存儲(chǔ)和消費(fèi)消息時(shí),kafka 會(huì)用 offset 來記錄當(dāng)前消息的順序:
- 消息存儲(chǔ)有序:通過 offset 偏移量來描述消息的有序性;
- 消費(fèi)有序:消費(fèi)者消費(fèi)消息時(shí)也是通過 offset 來描述當(dāng)前要消費(fèi)的消息位置。
2. 消費(fèi)組
(1) 創(chuàng)建消費(fèi)組
當(dāng)創(chuàng)建消費(fèi)者時(shí),我們可以為消費(fèi)者指定一個(gè)組別(group)。
--consuemr-property group.id=testGroup:指定 group 名稱為 testGroup
./kafka-console-consumer.sh --bootstrap-server 172.16.30.34:49092 --consuemr-property group.id=testGroup --topic hello-world指定組別后,在消費(fèi)消息時(shí),同一個(gè)消費(fèi)組 group 只有一個(gè)消費(fèi)者可以收到訂閱的 topic 消息。
(2) 查看消費(fèi)組信息
我們可以通過 describe 命令查看消費(fèi)組信息,命令如下:
# 消費(fèi)組testGroup的詳細(xì)信息
./kafka-consumer-groups.sh --bootstrap-server 172.16.30.34:49094 --describe --group testGroup消費(fèi)者信息如下:

我們需要關(guān)注的重點(diǎn)字段如下:
- CURRENT-OFFSET:最后被消費(fèi)的消息偏移量(offset);
- LOG-END-OFFSET:消息總量(最后一條消息的偏移量);
- LAG:積壓了多少條消息。
在同一個(gè)消費(fèi)組里面,任何一個(gè)消費(fèi)者拿到了消息,都會(huì)改變上述的字段值。
3.單播/多播消息
當(dāng)創(chuàng)建消費(fèi)組后,我們根據(jù)消費(fèi)組的個(gè)數(shù)來判斷消息是單播還是多播。這倆名詞源于網(wǎng)絡(luò)中的請(qǐng)求轉(zhuǎn)發(fā),單播就是一對(duì)一發(fā)送消息,多播就是多個(gè)消費(fèi)組同時(shí)消費(fèi)消息。
# 注意,當(dāng)兩個(gè)消費(fèi)者都不指定消費(fèi)組時(shí),可以同時(shí)消費(fèi)
./kafka-console-consumer.sh --bootstrap-server 172.16.30.34:49092 --topic hello-world每次創(chuàng)建消費(fèi)者時(shí),如果沒有指定消費(fèi)組,則相當(dāng)于創(chuàng)建了一個(gè)默認(rèn)消費(fèi)組,kafka 會(huì)為這些默認(rèn)消費(fèi)組生成一個(gè)隨機(jī)的 group id。
所以多次創(chuàng)建默認(rèn)消費(fèi)組時(shí),就是多播。
./kafka-console-consumer.sh --bootstrap-server 172.16.30.34:49092 --consuemr-property group.id=testGroup --topic hello-world而單播消費(fèi)時(shí),只有一個(gè)消費(fèi)組,所以 group_id 相同。
多播消費(fèi)時(shí),分別指定不同的消費(fèi)組名稱或者不指定消費(fèi)組名稱即可。
4.kafka消息日志文件
在 kafka 中,為了持久化數(shù)據(jù),服務(wù)器創(chuàng)建了多個(gè)主題分區(qū)文件來保存消息,其中:
(1) 主題-分區(qū)/00000000.log 日志文件里保存了某個(gè)主題下的消息;
(2) Kafka 內(nèi)部創(chuàng)建了 50 個(gè)分區(qū) consumer-offsets-0 ~ 49,用來存放消費(fèi)者消費(fèi)某個(gè) topic 的偏移量,這些偏移量由消費(fèi)者消費(fèi) topic 的時(shí)候主動(dòng)上報(bào)給 kafka。
- 提交到哪個(gè)分區(qū)由 hash 后取模得出:hash(consumerGroupId)% 50;
- 提交的內(nèi)容為:key = consumerGroupId + topic + 分區(qū)號(hào),value 為當(dāng)前 offset 的值,為正整數(shù)。
在 Kafka 中,消費(fèi)者的偏移量(consumer offset)是指消費(fèi)者在分區(qū)中已經(jīng)讀取到的位置。消費(fèi)者偏移量是由 Kafka 自動(dòng)管理的,以確保消費(fèi)者可以在故障恢復(fù)后繼續(xù)從上次中斷的位置開始消費(fèi)。
如果大家在日常業(yè)務(wù)時(shí)想要跳過某些不消費(fèi)的消息,或者重復(fù)消費(fèi),可以使用 Kafka 提供的 kafka-consumer-groups.sh 腳本,來查看和修改消費(fèi)者組的偏移量。
七、尾聲
1.小結(jié)
本文介紹了 Kafka 以其高速、高性能、高可靠性和高可用性在大數(shù)據(jù)領(lǐng)域中占據(jù)重要地位。
并且從下載安裝 Kafka 開始,到修改配置、服務(wù)啟動(dòng),通過命令行驗(yàn)證其是否啟動(dòng)成功。
接著,我們?cè)敿?xì)介紹了 Kafka 的核心組件,包括 Broker、Producer、Consumer、Topic、Partition 和Replication。
然后特別強(qiáng)調(diào)了 Topic 的創(chuàng)建和管理,展示了如何創(chuàng)建 Topic、指定分區(qū)和副本數(shù)量,以及如何查看 Topic 的詳細(xì)信息。我們還講述了 Partition 分區(qū)的優(yōu)勢(shì),如分離存儲(chǔ)和提高性能,并解釋了 Replication 副本的概念和重要性。
接著,我們展示了在 Kafka 中發(fā)送和消費(fèi)消息的過程,然后討論了消息存儲(chǔ)、順序性、消費(fèi)組的創(chuàng)建和查看消費(fèi)組信息,以及單播和多播消息的概念。
最后,文章提到了 Kafka 中消息日志文件保存的內(nèi)容,包括消息本身和消息偏移量,以及如何修改消息偏移量的位置。
相信看了這部分內(nèi)容,大家已經(jīng)學(xué)會(huì)如何搭建自己的 kafka 消息隊(duì)列了~
2.后續(xù)
Kafka 系列文章分為上下篇,上篇主要是核心組件的介紹和實(shí)踐上手等內(nèi)容,包含對(duì) Kafka 做了一個(gè)全面介紹,包括安裝、配置、核心組件和消息收發(fā)機(jī)制,本文是上篇內(nèi)容。
下篇內(nèi)容主要討論集群高可用、消息重復(fù)消費(fèi)、延時(shí)隊(duì)列等常見的高級(jí)用法,敬請(qǐng)期待。

















