













還在搞NeRF?實(shí)時(shí)渲染生成逼真自動(dòng)駕駛數(shù)據(jù)!Street Gaussians:超越所有SOTA!
作者:閻赟之、孫海洋
今天為大家分享一篇浙大&理想聯(lián)合發(fā)布的最新動(dòng)態(tài)城市場(chǎng)景建模工作—Street Gaussians,效果十分驚艷!
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
Street Gaussians的動(dòng)機(jī)
- 在自動(dòng)駕駛領(lǐng)域,動(dòng)態(tài)街景重建有著重要的應(yīng)用場(chǎng)景,比如數(shù)據(jù)生成、自動(dòng)標(biāo)注、閉環(huán)仿真等。由于對(duì)重建質(zhì)量和效率有較高的要求,這方面的技術(shù)仍舊臨著巨大的挑戰(zhàn)。
- 對(duì)于單目視頻建模動(dòng)態(tài)城市街景的問(wèn)題,近期方法主要是基于NeRF并結(jié)合跟蹤車輛的姿態(tài),從而重建出高真實(shí)感的視圖。然而訓(xùn)練和渲染速度慢、對(duì)跟蹤車輛姿態(tài)精度需求高,使其在很難真正被應(yīng)用起來(lái)。
- 我們提出了Street Gaussians,這是一種新的顯式場(chǎng)景表示方法,可以解決所有這些限制。
開(kāi)源鏈接:
- Street Gaussians for Modeling Dynamic Urban Scenes
- https://zju3dv.github.io/street_gaussians/
方法簡(jiǎn)介
- 在Street Gaussians中,動(dòng)態(tài)城市街道被表示為一組3D高斯的點(diǎn)云,每個(gè)點(diǎn)云與前景車輛或背景之一相關(guān)聯(lián)。為了模擬動(dòng)態(tài)前景物體車輛,每個(gè)物體模型都用可優(yōu)化的跟蹤姿態(tài)進(jìn)行建模,并配有動(dòng)態(tài)球諧函數(shù)模型來(lái)表現(xiàn)動(dòng)態(tài)外觀。
- 這種顯式表示可以輕松地組合物體車輛和背景,進(jìn)而允許進(jìn)行場(chǎng)景編輯操作。同時(shí)擁有極高的效率,可以在半小時(shí)完成訓(xùn)練,渲染速度達(dá)到133FPS(1066x1600分辨率)。
- 實(shí)驗(yàn)表明,Street Gaussians在所有數(shù)據(jù)集上優(yōu)于現(xiàn)階段SOTA方法。此外,提出了前景目標(biāo)位姿優(yōu)化策略(初始位姿來(lái)自跟蹤器),與使用真值姿態(tài)所達(dá)到性能相當(dāng),也驗(yàn)證了Street Gaussians的高魯棒性。
背景介紹
- 靜態(tài)場(chǎng)景建模
?基于場(chǎng)景表達(dá)的不同,我們可以將場(chǎng)景重建分為volume-based和point-based。volume-based的方法,用MLP網(wǎng)絡(luò)表示連續(xù)的體積場(chǎng)景,已經(jīng)取得了令人印象深刻的渲染結(jié)果。同時(shí)比如Mip-NeRF360、DNMP等也將其應(yīng)用場(chǎng)景擴(kuò)展到了城市街景 。point-based的方法,在點(diǎn)云上定義學(xué)習(xí)神經(jīng)描述符,并使用神經(jīng)渲染器執(zhí)行可微分的光柵化,大大可以提高了渲染效率。然而,它們需要密集的點(diǎn)云作為輸入,并在點(diǎn)云稀疏區(qū)域的結(jié)果相對(duì)模糊。最近的一項(xiàng)工作3D Gaussian Splatting (3D GS),在3D世界中定義了一組各向異性的高斯核,并執(zhí)行自適應(yīng)密度控制,以僅使用稀疏的點(diǎn)云輸入實(shí)現(xiàn)高質(zhì)量的渲染結(jié)果。我們可以把3DGS理解成介于volume-based和point-based的中間態(tài),所有同時(shí)擁有volume-based方法的高質(zhì)量,也擁有point-based方法的高效率。然而,3DGS假定場(chǎng)景是靜態(tài)的,不能模擬動(dòng)態(tài)移動(dòng)的對(duì)象。 - 動(dòng)態(tài)場(chǎng)景建模。
?可以從不同的角度來(lái)實(shí)現(xiàn)動(dòng)態(tài)場(chǎng)景建模,從目標(biāo)角度,可以在單個(gè)對(duì)象場(chǎng)景上構(gòu)建4D神經(jīng)場(chǎng)景表示(比如HyperReel ),從場(chǎng)景角度,可以通過(guò)在光流(如Suds)或視覺(jué)變換器特征(Emernerf )監(jiān)督下的實(shí)現(xiàn)場(chǎng)景解耦。然而,這些方法均無(wú)法對(duì)場(chǎng)景進(jìn)行進(jìn)行編輯,限制了其在自動(dòng)駕駛仿真中的應(yīng)用。還有一種方式,使用神經(jīng)場(chǎng)將場(chǎng)景建模為移動(dòng)對(duì)象模型和背景模型的組合(比如NSG、Panoptic Neural Fields),然而,它們需要精確的對(duì)象軌跡,并且在內(nèi)存成本和渲染速度上存在問(wèn)題。
算法建模
- 考慮到自動(dòng)駕駛場(chǎng)景中都是通過(guò)車載相機(jī)得到圖像序列,我們希望構(gòu)建一個(gè)模型,可以生成任意時(shí)間和視角的高質(zhì)量圖像。為實(shí)現(xiàn)這一目標(biāo),我們提出了一種新穎的場(chǎng)景表示,命名為"Street Gaussians"。如圖所示,我們將動(dòng)態(tài)城市街景表示為一組點(diǎn)云,每個(gè)點(diǎn)云對(duì)應(yīng)于靜態(tài)背景或移動(dòng)車輛。這種基于點(diǎn)的表示可以輕松組合多個(gè)獨(dú)立的模型,實(shí)現(xiàn)實(shí)時(shí)渲染以及解耦前景對(duì)象以實(shí)現(xiàn)場(chǎng)景編輯。我們提出的場(chǎng)景表示可以僅使用RGB圖像進(jìn)行訓(xùn)練,同時(shí)結(jié)合車輛位姿優(yōu)化策略,進(jìn)一步增強(qiáng)動(dòng)態(tài)前景的表示精度。
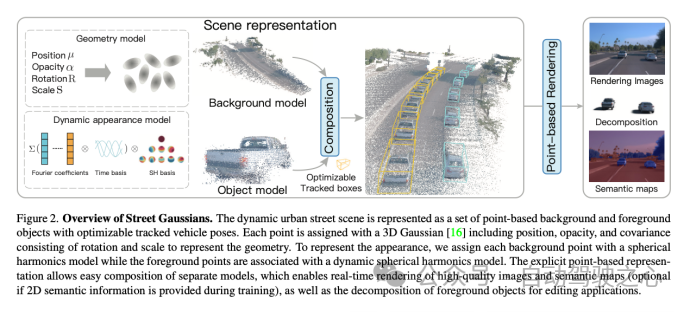
靜態(tài)背景建模
- 針對(duì)靜態(tài)背景,使用基本的3DGS方式建模,即我們世界坐標(biāo)系中一組點(diǎn)來(lái)表示背景模型,每個(gè)點(diǎn)分配有一個(gè)3D高斯分布,以平滑地表示連續(xù)的場(chǎng)景幾何和顏色。高斯參數(shù)包括協(xié)方差矩陣和位置向量(表示均值)。與3DGS一樣,為了避免在優(yōu)化過(guò)程中出現(xiàn)無(wú)效的協(xié)方差矩陣,每個(gè)協(xié)方差矩陣進(jìn)一步縮減為縮放矩陣和旋轉(zhuǎn)矩陣,其中縮放矩陣由其對(duì)角元素表征,而旋轉(zhuǎn)矩陣被轉(zhuǎn)換為單位四元數(shù)。除了位置和協(xié)方差矩陣之外,每個(gè)高斯分布還分配有一個(gè)不透明度值和一組球諧系數(shù)來(lái)表示場(chǎng)景幾何和外觀。為了獲得視圖相關(guān)的顏色,球諧系數(shù)還會(huì)乘以從視圖方向投影的球諧基函數(shù)。為了表示3D語(yǔ)義信息,每個(gè)點(diǎn)還附加有一個(gè)語(yǔ)義特征。
動(dòng)態(tài)前景建模
- 針對(duì)包含多輛移動(dòng)前景物體車輛的場(chǎng)景,我們將每個(gè)對(duì)象用一組可優(yōu)化的姿勢(shì)(初始位姿可以來(lái)自某個(gè)跟蹤器,比如CasTracker)和一組點(diǎn)云表示,其中每個(gè)點(diǎn)分配有一個(gè)3D高斯分布、語(yǔ)義和動(dòng)態(tài)外觀模型。前景對(duì)象和背景的高斯屬性相似,不透明度和尺度矩陣的定義相同,然而它們的位置、旋轉(zhuǎn)和外觀模型均不同。
- 每一個(gè)前景對(duì)象的3DGS模型,定義在該對(duì)象的local坐標(biāo)系下。我們通過(guò)前景對(duì)象的RT矩陣,可以將前景對(duì)象和背景的模型統(tǒng)一到世界坐標(biāo)系下。
- 僅使用球諧系數(shù)簡(jiǎn)單表示物體外觀不足以模擬移動(dòng)車輛的外觀,如圖所示,因?yàn)橐苿?dòng)車輛的外觀受到其在全局場(chǎng)景中位置的影響。如果使用單獨(dú)的球諧來(lái)表示每個(gè)時(shí)間的對(duì)象,會(huì)顯著增加存儲(chǔ)成本,我們的解決方案是引入了4D球諧模型,通過(guò)用一組傅里葉變換系數(shù)來(lái)表示球諧系數(shù),當(dāng)給定任意時(shí)間t,可以通過(guò)逆傅立葉變換來(lái)求出對(duì)應(yīng)的球諧系數(shù)。基于這種方式,我們將時(shí)間信息編碼到外觀中,而且不增加額外存儲(chǔ)成本。

渲染過(guò)程
- 要渲染Street Gaussians,我們就需要聚合每個(gè)模型對(duì)最終結(jié)果的貢獻(xiàn)。以前的方法中,由于神經(jīng)場(chǎng)表示方式,需要復(fù)雜的raymarching 方式進(jìn)行組合渲染。相反,Street Gaussians可以通過(guò)將所有點(diǎn)云拼接起來(lái),并將它們投影到2D圖像空間來(lái)進(jìn)行渲染。具體來(lái)說(shuō),在給定渲染時(shí)間點(diǎn)的情況下,我們首先計(jì)算球諧系數(shù),并根據(jù)跟蹤的車輛姿態(tài)將前景對(duì)象點(diǎn)云轉(zhuǎn)換到世界坐標(biāo)系,然后將背景點(diǎn)云和變換后的前景對(duì)象點(diǎn)云拼接起來(lái)形成一個(gè)新的全場(chǎng)景點(diǎn)云。
效果評(píng)估
- 我們?cè)赪aymo和KITTI數(shù)據(jù)集上都進(jìn)行了實(shí)驗(yàn)來(lái)評(píng)估我們的方法合成新視角的能力,不論定性和定量結(jié)果表明,相比之前的工作,我們的方法可以渲染出渲染高質(zhì)量圖片,并在各項(xiàng)指標(biāo)上均有有顯著提升。
?下圖是從定性角度,分別在waymo和kitti數(shù)據(jù)集上對(duì)比目前已有方法,無(wú)論背景還是前景目標(biāo),我們的方法在細(xì)節(jié)的渲染上均有大幅提高。


?同時(shí)我們?cè)趉itti和waymo上定量對(duì)比了重建指標(biāo),我們的方法也大幅領(lǐng)先已有方法。

KITTI數(shù)據(jù)集

Waymo數(shù)據(jù)集
下游任務(wù)
- Street Gaussians可以被應(yīng)用到很多下游任務(wù)當(dāng)中,包括場(chǎng)景的前背景解耦、場(chǎng)景的可控編輯、語(yǔ)義分割等。豐富且高質(zhì)量的下游任務(wù)適配,大大提高了Street Gaussians的應(yīng)用上限。
?我們的模型可以實(shí)現(xiàn)場(chǎng)景前背景解耦,細(xì)節(jié)上相比之前的方法有明顯提升。

?我們的模型支持便捷的場(chǎng)景編輯,如下圖分別是車輛增加、替換和交換的編輯操作。

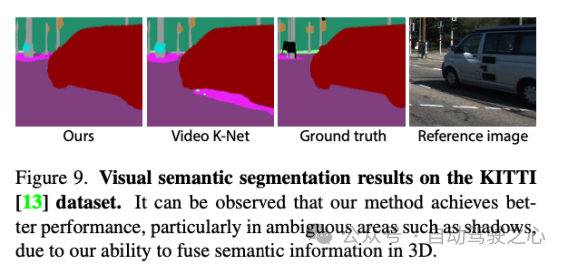
?我們的模型還支持拓展到語(yǔ)義分割任務(wù),依靠我們的建模方式,我們對(duì)于前景目標(biāo)的分割更加細(xì)膩。
方法總結(jié)
- 我們提出來(lái)了Street Gaussians,這是一種新穎的用于建模復(fù)雜的動(dòng)態(tài)街道場(chǎng)景的表征方法,它能夠高效地重建和渲染出高保真度的城市街道場(chǎng)景,并且支持實(shí)時(shí)渲染。
- 我們開(kāi)發(fā)了一種優(yōu)化跟蹤姿態(tài)的策略,配合一個(gè)4D球諧函數(shù)模型外觀模型來(lái)處理移動(dòng)前景的動(dòng)態(tài)車輛。
- 我們?cè)趲讉€(gè)具有挑戰(zhàn)性的數(shù)據(jù)集上進(jìn)行了全面的比較和消融實(shí)驗(yàn),展示了我們方法的最新最先進(jìn)性能以及所提出組件的有效性。


原文鏈接:https://mp.weixin.qq.com/s/zE32LGs6DHfbz_D5-8JYOA
責(zé)任編輯:張燕妮
來(lái)源:
自動(dòng)駕駛之心


























