刷榜「代碼生成」任務(wù)!復(fù)旦等發(fā)布StepCoder框架:從編譯器反饋信號中強化學(xué)習(xí)
大型語言模型(LLMs)的發(fā)展極大地推動了代碼生成領(lǐng)域的發(fā)展,之前有工作將強化學(xué)習(xí)(RL)與編譯器的反饋信號集成在一起,用于探索LLMs的輸出空間,以提高代碼生成質(zhì)量。
但當(dāng)下還存在兩個問題:
1. 強化學(xué)習(xí)探索很難直接適配到「復(fù)雜的人類需求」,即要求LLMs生成「長序列代碼」;
2. 由于單元測試可能無法覆蓋復(fù)雜的代碼,因此使用未執(zhí)行的代碼片段來優(yōu)化LLMs是無效的。
為了解決這些挑戰(zhàn),復(fù)旦大學(xué)、華中科技大學(xué)、皇家理工學(xué)院的研究人員提出了一種用于代碼生成的新型強化學(xué)習(xí)框架StepCoder,由兩個主要組件組成:
1. CCCS通過將長序列代碼生成任務(wù)分解為代碼完成子任務(wù)課程來解決探索挑戰(zhàn);
2. FGO通過屏蔽未執(zhí)行的代碼段來優(yōu)化模型,以提供細(xì)粒度優(yōu)化。

論文鏈接:https://arxiv.org/pdf/2402.01391.pdf
項目鏈接:https://github.com/Ablustrund/APPS_Plus
研究人員還構(gòu)建了用于強化學(xué)習(xí)訓(xùn)練的APPS+數(shù)據(jù)集,手動驗證以確保單元測試的正確性。
實驗結(jié)果表明,該方法提高了探索輸出空間的能力,并在相應(yīng)的基準(zhǔn)測試中優(yōu)于最先進的方法。
StepCoder
在代碼生成過程中,普通的強化學(xué)習(xí)探索(exploration)很難處理「獎勵稀疏且延遲的環(huán)境」和涉及「長序列的復(fù)雜需求」。
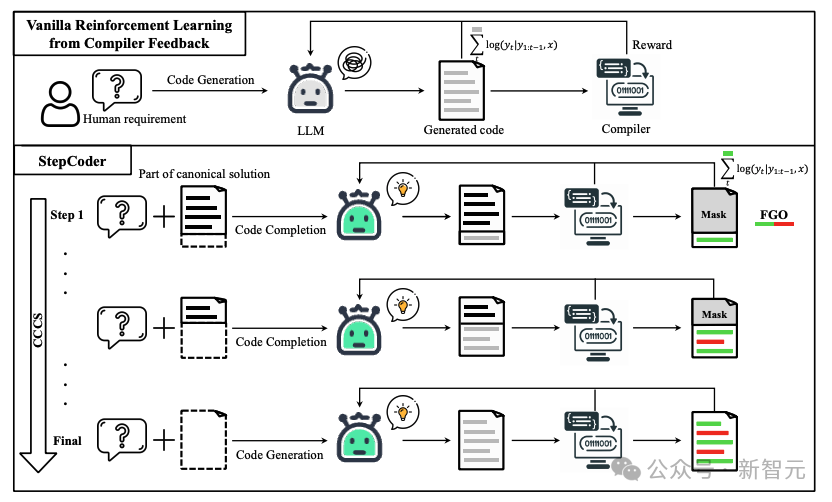
在CCCS(Curriculum of Code Completion Subtasks)階段,研究人員將復(fù)雜的探索問題分解為一系列子任務(wù)。利用標(biāo)準(zhǔn)解(canonical solution)的一部分作為提示(prompt),LLM可以從簡單序列開始探索。
獎勵的計算只與可執(zhí)行的代碼片段相關(guān),因此用整個代碼(圖中紅色部分)來優(yōu)化LLM是不精確的(圖中灰色部分)。
在FGO(Fine-Grained Optimization)階段,研究人員對單元測試中未執(zhí)行的tokens(紅色部分)進行遮罩,只使用已執(zhí)行的tokens(綠色部分)計算損失函數(shù),從而可以提供細(xì)粒度的優(yōu)化。
預(yù)備知識
假定 是用于代碼生成的訓(xùn)練數(shù)據(jù)集,其中x、y、u分別表示人類需求(即任務(wù)描述)、標(biāo)準(zhǔn)解和單元測試樣本。
是用于代碼生成的訓(xùn)練數(shù)據(jù)集,其中x、y、u分別表示人類需求(即任務(wù)描述)、標(biāo)準(zhǔn)解和單元測試樣本。
 是通過自動分析標(biāo)準(zhǔn)解yi的抽象語法樹得出的條件語句列表,其中st和en分別表示語句的起始位置和結(jié)束位置。
是通過自動分析標(biāo)準(zhǔn)解yi的抽象語法樹得出的條件語句列表,其中st和en分別表示語句的起始位置和結(jié)束位置。
對于人類需求x,其標(biāo)準(zhǔn)解y可表示為 ;在代碼生成階段,給定人類需求x,最終狀態(tài)是通過單元測試u的代碼集合。
;在代碼生成階段,給定人類需求x,最終狀態(tài)是通過單元測試u的代碼集合。
方法細(xì)節(jié)
StepCoder集成了兩個關(guān)鍵組件:CCCS和FGO,其中CCCS的目的是將代碼生成任務(wù)分解為代碼完成子任務(wù)的課程,可以減輕RL中的探索挑戰(zhàn);FGO專為代碼生成任務(wù)而設(shè)計,通過只計算已執(zhí)行代碼片段的損失來提供細(xì)粒度優(yōu)化。
CCCS
在代碼生成過程中,要解決復(fù)雜的人類需求,通常需要策略模型采取較長的動作序列。同時,編譯器的反饋是延遲和稀疏的,也就是說,策略模型只有在生成整個代碼后才會收到獎勵。在這種情況下,探索非常困難。
該方法的核心是將這樣一長串探索問題分解為一系列簡短、易于探索的子任務(wù),研究人員將代碼生成簡化為代碼補全子任務(wù),其中子任務(wù)由訓(xùn)練數(shù)據(jù)集中的典型解決方案自動構(gòu)建。
對于人類需求x,在CCCS的早期訓(xùn)練階段,探索的起點s*是最終狀態(tài)附近的狀態(tài)。
具體來說,研究人員提供人類需求x和標(biāo)準(zhǔn)解 的前半部分,并訓(xùn)練策略模型來根據(jù)x'=(x, xp)完成代碼。
的前半部分,并訓(xùn)練策略模型來根據(jù)x'=(x, xp)完成代碼。
假定y^是xp和輸出軌跡τ的組合序列,即y?=(xp,τ),獎勵模型根據(jù)以y^為輸入的代碼片段τ的正確性提供獎勵r。

研究人員使用近端策略優(yōu)化(PPO)算法,通過利用獎勵r和軌跡τ來優(yōu)化策略模型πθ 。
在優(yōu)化階段,用于提供提示的規(guī)范解代碼段xp將被屏蔽,這樣它就不會對策略模型πθ更新的梯度產(chǎn)生影響。
CCCS通過最大化反對函數(shù)來優(yōu)化策略模型πθ,其中π^ref是PPO中的參考模型,由SFT模型初始化。

隨著訓(xùn)練的進行,探索的起點s*會逐漸向標(biāo)準(zhǔn)解的起點移動,具體來說,為每個訓(xùn)練樣本設(shè)置一個閾值ρ,每當(dāng)πθ生成的代碼段的累計正確率大于ρ時,就將starting point向beginning移動。
在訓(xùn)練的后期階段,該方法的探索過程等同于原始強化學(xué)習(xí)的探索過程,即s*=0,策略模型僅以人類需求為輸入生成代碼。
在條件語句的起始位置對初識點s*進行采樣,以完成剩余的未寫代碼段。
具體來說,條件語句越多,程序的獨立路徑就越多,邏輯復(fù)雜度也就越高,復(fù)雜性要求更頻繁地采樣以提高訓(xùn)練質(zhì)量,而條件語句較少的程序則不需要那么頻繁地采樣。
這種采樣方法可以均衡地抽取具有代表性的代碼結(jié)構(gòu),同時兼顧訓(xùn)練數(shù)據(jù)集中復(fù)雜和簡單的語義結(jié)構(gòu)。
為了加速訓(xùn)練階段,研究人員將第i個樣本的課程數(shù)量設(shè)置為 ,其中Ei是其條件語句的數(shù)量。第i個樣本的訓(xùn)練課程跨度為
,其中Ei是其條件語句的數(shù)量。第i個樣本的訓(xùn)練課程跨度為 ,而不是1。
,而不是1。
CCCS的主要觀點可歸納如下:
1. 從接近目標(biāo)的狀態(tài)(即最終狀態(tài))開始探索很容易;
2. 從距離目標(biāo)較遠(yuǎn)的狀態(tài)開始探索具有挑戰(zhàn)性,但如果能利用已經(jīng)學(xué)會如何達到目標(biāo)的狀態(tài),探索就會變得容易。
FGO
代碼生成中獎勵與行動之間的關(guān)系不同于其他強化學(xué)習(xí)任務(wù)(如Atari),在代碼生成中,可以排除一組與計算生成代碼中的獎勵無關(guān)的動作。
具體來說,對于單元測試,編譯器的反饋只與執(zhí)行的代碼片段,然而,在普通RL優(yōu)化目標(biāo)中,軌跡上的所有動作都會參與到梯度計算中,而梯度計算是不精確的。
為了提高優(yōu)化精度,研究人員屏蔽了單元測試中未執(zhí)行的行動(即tokens),策略模型的損失。

實驗部分
APPS+數(shù)據(jù)集
強化學(xué)習(xí)需要大量高質(zhì)量的訓(xùn)練數(shù)據(jù),在調(diào)研過程中,研究人員發(fā)現(xiàn)在目前可用的開源數(shù)據(jù)集中,只有APPS符合這一要求。
但APPS中存在一些不正確的實例,例如缺少輸入、輸出或標(biāo)準(zhǔn)解,其中標(biāo)準(zhǔn)解可能無法編譯或無法執(zhí)行,或者執(zhí)行輸出存在差異。
為了完善APPS數(shù)據(jù)集,研究人員過濾掉了缺少輸入、輸出或標(biāo)準(zhǔn)解的實例,然后對輸入和輸出的格式進行了標(biāo)準(zhǔn)化,以方便單元測試的執(zhí)行和比較;然后對每個實例進行了單元測試和人工分析,剔除了代碼不完整或不相關(guān)、語法錯誤、API誤用或缺少庫依賴關(guān)系的實例。
對于輸出中的差異,研究人員會手動審核問題描述,糾正預(yù)期輸出或消除實例。
最后構(gòu)建了得到APPS+數(shù)據(jù)集,包含了7456個實例,每個實例包括編程問題描述、標(biāo)準(zhǔn)解決方案、函數(shù)名稱、單元測試(即輸入和輸出)和啟動代碼(即標(biāo)準(zhǔn)解決方案的開頭部分)。

實驗結(jié)果
為了評估其他LLM和StepCoder在代碼生成方面的性能,研究人員在APPS+數(shù)據(jù)集上進行了實驗。
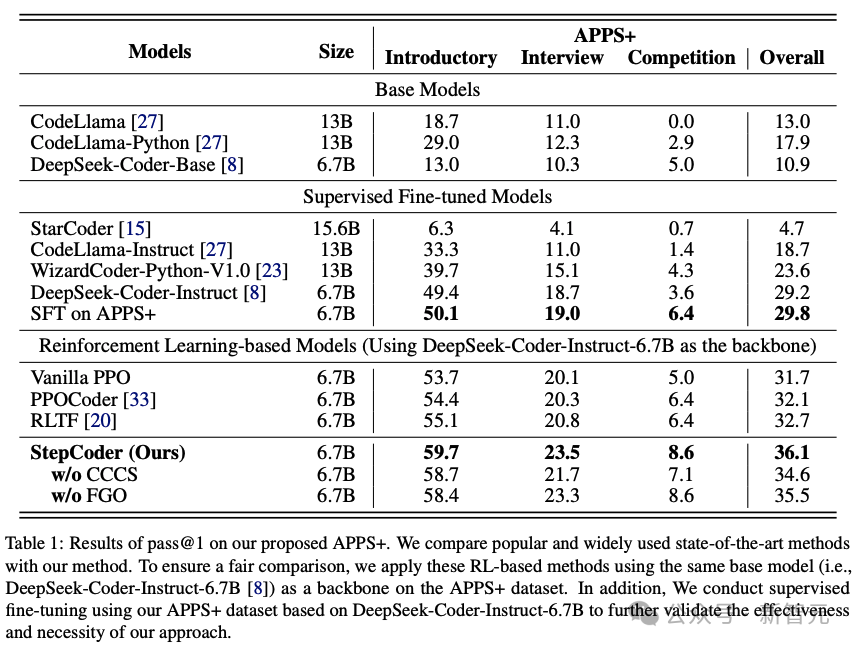
結(jié)果表明,基于RL的模型優(yōu)于其他語言模型,包括基礎(chǔ)模型和SFT模型。
研究人員有理由推斷,強化學(xué)習(xí)可以在編譯器反饋的指導(dǎo)下,更有效地瀏覽模型的輸出空間,從而進一步提高代碼生成的質(zhì)量。
此外,StepCoder超越了所有基線模型,包括其他基于RL的方法,獲得了最高分。
具體來說,該方法在「入門」(Introductory)、「面試」(Interview)和「競賽」(Competition)級別的測試題目中分別獲得了59.7%、23.5%和 8.6%的高分。
與其他基于強化學(xué)習(xí)的方法相比,該方法通過將復(fù)雜的代碼生成任務(wù)簡化為代碼完成子任務(wù),在探索輸出空間方面表現(xiàn)出色,并且FGO過程在精確優(yōu)化策略模型方面發(fā)揮了關(guān)鍵作用。
還可以發(fā)現(xiàn),在基于相同架構(gòu)網(wǎng)絡(luò)的APPS+數(shù)據(jù)集上,StepCoder的性能優(yōu)于對微調(diào)進行有監(jiān)督的LLM;與骨干網(wǎng)相比,后者幾乎沒有提高生成代碼的通過率,這也直接表明,使用編譯器反饋優(yōu)化模型的方法比代碼生成中的下一個token預(yù)測更能提高生成代碼的質(zhì)量。