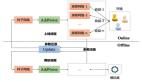
從反饋中學習:強化學習如何提升百曉生問答精準度
第一部分:引言
在人工智能技術(shù)飛速發(fā)展的今天,智能問答系統(tǒng)已成為連接信息與用戶的重要橋梁,它們不僅重塑著人機交互方式,更在提升服務(wù)效率、優(yōu)化知識獲取路徑等方面展現(xiàn)出巨大潛力。在此背景下,"百曉生"作為一款基于RAG(檢索增強生成)與外掛知識庫的大型語言模型(LLM)驅(qū)動的問答產(chǎn)品,專注于為上門工程師提供精準的質(zhì)檢知識答疑服務(wù)。經(jīng)過一年的持續(xù)迭代與優(yōu)化,該產(chǎn)品已從最初的10%小流量實驗,逐步開放至全國范圍,目前每日穩(wěn)定為超過3000名工程師提供支持,連續(xù)多周問答準確率保持在90%+。其技術(shù)架構(gòu)也經(jīng)歷了顯著演進,從初期的簡單RAG問答,升級為集多輪對話管理、主動反向追問(以澄清模糊問題)和圖文混排答案生成于一體的復(fù)雜智能體(Agent)系統(tǒng)。
然而,隨著問答精準度的不斷提升,系統(tǒng)優(yōu)化的挑戰(zhàn)也從明確的事實性錯誤轉(zhuǎn)向答案生成的穩(wěn)定性、對復(fù)雜質(zhì)檢知識的深入理解、問答速度提升(精簡思考過程)等深層次優(yōu)化。傳統(tǒng)的優(yōu)化方法在面對這些需要持續(xù)學習和策略決策的場景時,逐漸顯現(xiàn)出瓶頸。與此同時,人工智能領(lǐng)域的一項技術(shù)正悄然改變著大模型的優(yōu)化范式--強化學習(Reinforcement Learning, RL)。特別是基于人類反饋的強化學習(RLHF)和更前沿的基于可驗證獎勵的強化學習(RLVR),正在引導(dǎo)大模型從"生成看似正確的答案"向"生成確實正確的答案"飛躍。
因此,將強化學習技術(shù)深度融合到"百曉生"這類智能問答系統(tǒng)的優(yōu)化過程中,代表著一條極具潛力的演進路徑。它不僅能優(yōu)化系統(tǒng)從海量信息中檢索和生成答案的質(zhì)量,更能讓系統(tǒng)在持續(xù)的人機交互反饋循環(huán)中不斷學習與調(diào)整,最終實現(xiàn)應(yīng)答精準度與用戶滿意度的雙重提升。本文將深入探討強化學習如何針對百曉生問答系統(tǒng)中的答案生成的穩(wěn)定性、對復(fù)雜質(zhì)檢知識的深入理解、問答速度提升(精簡思考過程)等關(guān)鍵環(huán)節(jié)發(fā)揮作用。
第二部分:強化學習技術(shù)選型:PPO、DPO與GRPO概述
2.1 近端策略優(yōu)化(PPO)
PPO全稱Proximal Policy Optimization(近端策略優(yōu)化),近端(Proximal)意味著這種優(yōu)化方法會限制每次更新的幅度,從而保證了訓(xùn)練的穩(wěn)定性。

2.2 直接偏好優(yōu)化(DPO)
背景:DPO是一種離線且無獎勵模型的偏好學習算法。它洞察到,對于基于Bradley-Terry模型的偏好概率,可以通過解析地推導(dǎo)出最優(yōu)策略與獎勵函數(shù)之間的關(guān)系,從而繞過顯式學習獎勵模型的步驟,直接利用偏好數(shù)據(jù)優(yōu)化策略。

2.3 群體相對策略優(yōu)化(GRPO)
背景:GRPO是針對PPO的一種改進方法,旨在減少對額外評估網(wǎng)絡(luò)(Critic)的依賴,并通過群體內(nèi)的相對比較來估計優(yōu)勢函數(shù),以提升訓(xùn)練效率與穩(wěn)定性。它特別適合處理離散獎勵信號和大規(guī)模語言模型微調(diào)的場景。

2.4 強化學習技術(shù)總結(jié)
在大模型對齊(Alignment)技術(shù)中,PPO、DPO和GRPO是三種主流的優(yōu)化算法,它們的目標都是讓模型的輸出更符合人類偏好,區(qū)別如下:
PPO(近端策略優(yōu)化)的核心在于通過裁剪機制限制策略更新的幅度,確保訓(xùn)練穩(wěn)定性。它采用Actor-Critic架構(gòu),其中Actor(策略網(wǎng)絡(luò))負責選擇動作,Critic(評估網(wǎng)絡(luò))評估狀態(tài)價值,并通過廣義優(yōu)勢估計(GAE)計算優(yōu)勢函數(shù)來指導(dǎo)策略更新。這種設(shè)計使其在復(fù)雜環(huán)境中能有效平衡探索與利用,成為目前最流行的強化學習算法之一。
DPO(直接偏好優(yōu)化)則完全繞開了復(fù)雜的獎勵模型建模和強化學習流程。它直接利用人類標注的偏好數(shù)據(jù)(即一對“好答案”和“壞答案”),通過數(shù)學推導(dǎo)將獎勵函數(shù)的優(yōu)化轉(zhuǎn)化為直接對策略模型的優(yōu)化。這種方法大幅簡化了訓(xùn)練流程,降低了計算成本,同時在大模型對齊任務(wù)中表現(xiàn)出優(yōu)異的穩(wěn)定性和效果。
GRPO(群體相對策略優(yōu)化)的創(chuàng)新點在于利用“群體比較”的思想。對于每個問題,模型會生成一組多個答案,然后在這些答案內(nèi)部進行相對評分和比較(例如,將每個答案的獎勵與組內(nèi)平均獎勵進行比較),并以此作為策略優(yōu)化的信號。這種方法避免了對評估網(wǎng)絡(luò)(Critic)的依賴,使訓(xùn)練過程更輕量,特別適合計算資源受限或需要快速迭代的場景。
第三部分:百曉生系統(tǒng)強化微調(diào)實踐
3.1 強化微調(diào)(Reinforcement Fine-Tuning, RFT)
對開源大模型進行領(lǐng)域適配時,監(jiān)督微調(diào)(SFT)是普遍采用的方法。然而,若SFT數(shù)據(jù)質(zhì)量不佳或訓(xùn)練輪次過多,模型容易陷入過擬合,具體表現(xiàn)為"復(fù)讀機"式的重復(fù)生成,以及在新任務(wù)上表現(xiàn)驟降的災(zāi)難性遺忘問題,最終導(dǎo)致生成質(zhì)量和實際業(yè)務(wù)指標下降。
為解決上述問題,一種結(jié)合監(jiān)督學習與強化學習優(yōu)勢的迭代式訓(xùn)練范式------強化微調(diào)(Reinforcement Fine-Tuning, RFT)顯示出巨大潛力。強化微調(diào)指的是:多階段反復(fù)進行SFT+RL流程,例如,deepseek-R1反復(fù)進行了兩階段SFT+GRPO。RFT核心邏輯在于形成一種有效的互補:SFT負責利用高質(zhì)量數(shù)據(jù)為模型打下堅實的基礎(chǔ)行為模式,而強化學習(如GRPO)則在此基礎(chǔ)上通過獎勵信號引導(dǎo)模型進行探索和優(yōu)化,學習更復(fù)雜的偏好和推理能力。
3.2 百曉生系統(tǒng)RFT實踐
百曉生問答模型RFT訓(xùn)練,采用兩階段SFT+RL流程,其中RL過程采用GRPO算法。
3.2.1 百曉生系統(tǒng)簡介
在轉(zhuǎn)轉(zhuǎn)上門回收服務(wù)中,工程師對電子產(chǎn)品進行準確估價是確認最終回收價格的核心環(huán)節(jié)。該流程主要分為設(shè)備檢測與系統(tǒng)定價兩步:工程師首先對設(shè)備的外觀、功能等進行全面檢測,隨后在內(nèi)部系統(tǒng)中根據(jù)檢測結(jié)果勾選對應(yīng)的狀態(tài)選項;系統(tǒng)則依據(jù)這些選項信息,通過內(nèi)置算法模型自動生成回收價格。因此,勾選的準確性直接決定了估價的公正性,也關(guān)系到用戶與公司雙方的利益。
為提升選項勾選的規(guī)范性與一致性,轉(zhuǎn)轉(zhuǎn)引入了百曉生系統(tǒng)。該系統(tǒng)基于RAG(檢索增強生成)技術(shù),為工程師提供實時的、標準化的勾選指引和業(yè)務(wù)答疑。例如,當工程師遇到"手機主板出現(xiàn)第三方標識"這一情況時,百曉生系統(tǒng)會明確提示應(yīng)勾選【主板拆修】-【主板-有第三方標識】選項,并同時說明例外情形(如"友商標"等非拆修標識則無需勾選),從而有效減少因個人判斷差異導(dǎo)致的誤操作。
3.2.2 GRPO獎勵函數(shù)設(shè)計與訓(xùn)練
GRPO訓(xùn)練過程,對同一個問題,生成N個候選答案。使用獎勵函數(shù)對N個候選答案進行打分,獎勵超過平均分的答案,懲罰低于平均分的答案。針對百曉生問答,設(shè)計了2個獎勵函數(shù)。相似度獎勵和重復(fù)懲罰。
相似度獎勵:意在提升問答準確率,通過計算標準答案與大模型生成答案的相似度,獎勵相似度高的答案。為提升長文本語義相似度效果,相似度獎勵采用deepseek-V3進行評分。為保證訓(xùn)練速度,使用BERT對deepseek-V3評分進行蒸餾,訓(xùn)練中使用bert評分作為獎勵。deepseek-V3評分prompt如下:
 圖片
圖片
重復(fù)懲罰獎勵:重復(fù)懲罰意在解決復(fù)讀機現(xiàn)象,對答案中的重復(fù)程度進行評分,重復(fù)程度使用embedding模型進行計算。
評分示例:
 圖片
圖片
completions是大模型生成答案,cross_encoder_similarity表示相似度獎勵,anti_repetition_throught表示重復(fù)懲罰獎勵,advantages綜合(加權(quán)平均)獎勵得分,為正數(shù)時,對答案進行獎勵,提高其出現(xiàn)概率。
訓(xùn)練過程:
 圖片
圖片
kl是GRPO新訓(xùn)練模型與原始模型的KL散度,其作用是防止新模型偏離原始模型太遠。限制kl散度,防止領(lǐng)域化訓(xùn)練的過程中,模型原有能力的災(zāi)難性遺忘現(xiàn)象;
CrossEncoderSimilarityORM是相似度獎勵;
AntiRepetitionThoughtORM是重復(fù)懲罰獎勵,重復(fù)越低,得分越高。
3.2.3 效果評估
在Qwen3-8B模型上實施強化微調(diào)(RFT)后,其在百曉生問答任務(wù)上的準確率達到94.05%,與參數(shù)量達200B(2000億)的豆包1.6-thinking-pro模型效果相當。 使用相同訓(xùn)練數(shù)據(jù),RFT相比監(jiān)督微調(diào)(SFT)在準確率上進一步提升6%,顯示出強化學習機制在任務(wù)對齊上的有效性。
在生成質(zhì)量方面,RFT顯著改善了"重復(fù)生成"問題,相關(guān)現(xiàn)象發(fā)生率降至0%。由于輸出更簡潔,模型平均生成時長縮短至約10秒,遠低于豆包1.6的40秒,體現(xiàn)出更好的推理效率。
此外,RFT也顯著提升了生成答案的穩(wěn)定性。對同一問題多次生成答案進行一致性評估,其答案間相關(guān)系數(shù)達到0.85,高于豆包1.6的0.76,說明RFT模型輸出更可控、更可靠。
第四部分:總結(jié)與展望
RFT(強化微調(diào))作為一種新興的大模型訓(xùn)練范式,已在多項權(quán)威的推理能力、數(shù)學及代碼生成榜單中展現(xiàn)出顯著優(yōu)勢。我們通過近兩個月的實驗驗證,證實RFT技術(shù)在百曉生系統(tǒng)中同樣能夠有效提升業(yè)務(wù)關(guān)鍵指標。相較于傳統(tǒng)方法,RFT訓(xùn)練流程能夠更深入地挖掘數(shù)據(jù)中的潛在規(guī)律,其核心優(yōu)勢在于能夠有效抑制微調(diào)過程中常見的負面效應(yīng),例如生成內(nèi)容的重復(fù)性("復(fù)讀機現(xiàn)象")以及模型對已習得通用知識的災(zāi)難性遺忘問題。
面向未來,RFT技術(shù)在百曉生系統(tǒng)乃至更廣闊的應(yīng)用場景中,仍有豐富的探索方向:
其一,可設(shè)計更精細、更貼合業(yè)務(wù)目標的獎勵函數(shù),以更精準地引導(dǎo)模型優(yōu)化方向;
其二,可積極探索將RFT應(yīng)用于多模態(tài)任務(wù),例如基于圖片的質(zhì)檢問答等復(fù)雜場景,以拓展模型能力的邊界。
關(guān)于作者:車天博、李俊波、李瑩瑩,轉(zhuǎn)轉(zhuǎn)算法工程師,主要負責客服問答、百曉生質(zhì)檢問答相關(guān)項目。