使用深度強化學習預測股票:DQN 、Double DQN和Dueling Double DQN對比和代碼示例
深度強化學習可以將深度學習與強化學習相結合:深度學習擅長從原始數據中學習復雜的表示,強化學習則使代理能夠通過反復試驗在給定環境中學習最佳動作。通過DRL,研究人員和投資者可以開發能夠分析歷史數據的模型,理解復雜的市場動態,并對股票購買、銷售或持有做出明智的決策。
下面我們一邊寫代碼一邊介紹這些相關的知識
數據集
import numpy as np
import pandas as pd
import copyimport numpy as npimport chainer
import chainer.functions as F
import chainer.links as Lfrom plotly import tools
from plotly.graph_objs import *
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
from tqdm import tqdm_notebook as tqdminit_notebook_mode()這里主要使用使用Jupyter notebook和plotly進行可視化,所以需要一些額外的設置,下面開始讀取數據
try:
data = pd.read_csv('../input/Data/Stocks/goog.us.txt')
data['Date'] = pd.to_datetime(data['Date'])
data = data.set_index('Date')except (FileNotFoundError): import datetime
import pandas_datareader as pdr
from pandas import Series, DataFrame start = datetime.datetime(2010, 1, 1)
end = datetime.datetime(2017, 1, 11) data = pdr.get_data_yahoo("AAPL", start, end)print(data.index.min(), data.index.max())split_index = int(len(data)/2)
date_split = data.index[split_index]
train = data[:split_index]
test = data[split_index:]#date_split = '2016-01-01'
date_split = '2016-01-01'
train = data[:date_split]
test = data[date_split:]
print(len(data), len(train), len(test))
display(data)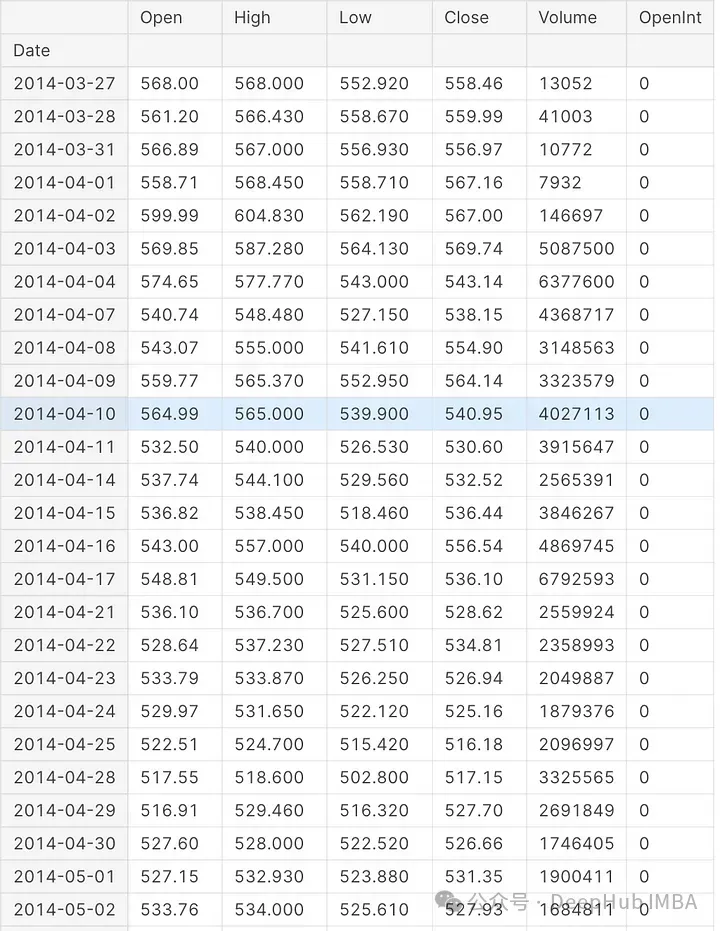
代碼從數據集中讀取數據。進行測試和驗證集的拆分,然后使用' display '函數,代碼在Jupyter筆記本中顯示導入的數據。
def plot_train_test(train, test, date_split):
data = [
Candlestick(x=train.index, open=train['Open'], high=train['High'], low=train['Low'], close=train['Close'], name='train'),
Candlestick(x=test.index, open=test['Open'], high=test['High'], low=test['Low'], close=test['Close'], name='test')
]
layout = {
'shapes': [
{'x0': date_split, 'x1': date_split, 'y0': 0, 'y1': 1, 'xref': 'x', 'yref': 'paper', 'line': {'color': 'rgb(0,0,0)', 'width': 1}}
],
'annotations': [
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'left', 'text': ' test data'},
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'right', 'text': 'train data '}
]
}
figure = Figure(data=data, layout=layout)
iplot(figure)這段代碼定義了一個名為plot_train_test的函數,該函數使用Python繪圖庫Plotly創建可視化圖。基于指定的日期,圖表將股票數據分為訓練集和測試集。輸入參數包括train、test和date_split。
可視化結果如下:
plot_train_test(train, test, date_split)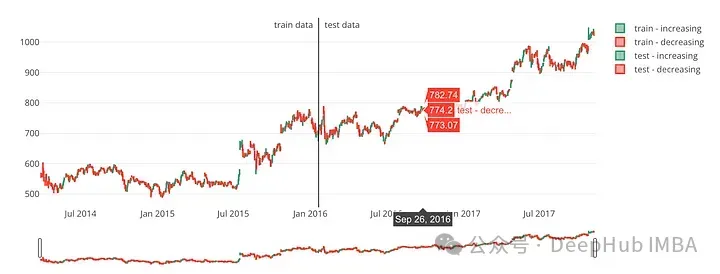
環境
下面我們開始編寫強化學習相關的內容
class Environment:
def __init__(self, data, history_t=90):
self.data = data
self.history_t = history_t
self.reset()
def reset(self):
self.t = 0
self.done = False
self.profits = 0
self.positions = []
self.position_value = 0
self.history = [0 for _ in range(self.history_t)]
return [self.position_value] + self.history # obs
def step(self, act):
reward = 0
# act = 0: stay, 1: buy, 2: sell
if act == 1:
self.positions.append(self.data.iloc[self.t, :]['Close'])
elif act == 2: # sell
if len(self.positions) == 0:
reward = -1
else:
profits = 0
for p in self.positions:
profits += (self.data.iloc[self.t, :]['Close'] - p)
reward += profits
self.profits += profits
self.positions = []
# set next time
self.t += 1
self.position_value = 0
for p in self.positions:
self.position_value += (self.data.iloc[self.t, :]['Close'] - p)
self.history.pop(0)
self.history.append(self.data.iloc[self.t, :]['Close'] - self.data.iloc[(self.t-1), :]['Close'])
# clipping reward
if reward > 0:
reward = 1
elif reward < 0:
reward = -1
return [self.position_value] + self.history, reward, self.done, self.profits # obs, reward, done, profits首先定義強化學習的環境,這里的Environment的類模擬了一個簡單的交易環境。使用歷史股票價格數據,代理可以根據這些數據決定是否購買、出售或持有股票。
init()接受兩個參數:data,表示股票價格數據;history_t,定義環境應該維持多少時間步長。通過設置data和history_t值并調用reset(),構造函數初始化了環境。
Reset()初始化或重置環境的內部狀態變量,包括當前時間步長(self.t)、完成標志、總利潤、未平倉頭寸、頭寸值和歷史價格。該方法返回由頭寸價值和價格歷史組成的觀測值。
step()方法,可以基于一個動作更新環境的狀態。動作用整數表示:0表示持有,1表示購買,2表示出售。如果代理人決定買入,股票的當前收盤價將被添加到頭寸列表中。一旦經紀人決定賣出,該方法計算每個未平倉頭寸的利潤或損失,并相應地更新利潤變量。然后,所有未平倉頭寸被平倉。根據賣出行為中產生的利潤或損失,獎勵被削減到- 1,0或1。
代理可以使用Environment類學習并根據歷史股票價格數據做出決策,Environment類模擬股票交易環境。在受控環境中,可以訓練強化學習代理來制定交易策略。
env = Environment(train)
print(env.reset())
for _ in range(3):
pact = np.random.randint(3)
print(env.step(pact))

DQN
def train_dqn(env, epoch_num=50):
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
) def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y
def reset(self):
self.zerograds()
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q)
step_max = len(env.data)-1
memory_size = 200
batch_size = 20
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5 memory = []
total_step = 0
total_rewards = []
total_losses = [] start = time.time()
for epoch in range(epoch_num): pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max: # select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data) # act
obs, reward, done, profit = env.step(pact) # add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0) # train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=np.bool)
q = Q(b_pobs)
maxq = np.max(Q_ast(b_obs).data, axis=1)
target = copy.deepcopy(q.data)
for j in range(batch_size):
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
Q.reset()
deephub_loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q) # epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease # next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards這段代碼定義了一個函數train_dqn(),它為一個簡單的股票交易環境訓練一個Deep Q-Network (DQN)。該函數接受兩個參數:一個是env參數,表示交易環境;另一個是epoch_num參數,指定要訓練多少epoch。
代碼定義了一個Q_Network類,它是Chainer的Chain類的一個子類。在Q-Network中,有三個完全連接的層,前兩層具有ReLU激活函數。模型梯度通過reset()方法歸零。
創建Q- network的兩個實例Q和Q_ast,以及用于更新模型參數的Adam優化器。對于DQN訓練,定義了幾個超參數,包括緩沖區內存大小、批處理大小、epsilon、gamma和更新頻率。
為了跟蹤模型在訓練期間的表現,在內存列表中創建total_rewards和total_losses列表。在每個epoch的開始,環境被重置,一些變量被初始化。
代理根據當前狀態和epsilon-greedy探索策略選擇一個動作(持有、買入或賣出)。然后,代理在環境中執行動作,獲得獎勵,并觀察新的狀態。在緩沖區中,存儲了經驗元組(前一個狀態、動作、獎勵、新狀態和完成標志)。
為了訓練DQN,當緩沖區滿時,從內存中采樣一批經驗。利用Q_ast網絡和Bellman方程,計算了目標q值。損失計算為預測q值與目標q值之間的均方誤差。計算梯度,優化器更新模型參數。
目標網絡Q_ast使用主網絡q的權值定期更新,隨著智能體的學習,epsilon值線性減小,促進更多的利用。每個時期,總獎勵和損失都會累積起來,結果也會被記錄下來。
訓練結束時,train_dqn()返回訓練后的Q-Network、總損失和總獎勵。DQN模型可用于根據輸入的股票價格數據和模擬的交易環境制定交易策略。
dqn, total_losses, total_rewards = train_dqn(Environment(train), epoch_num=25)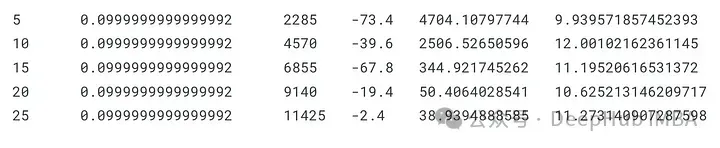
這段代碼使用來自指定環境的訓練數據(使用train_dqn函數)訓練DQN模型,并返回訓練后的模型以及每個訓練歷元的總損失和獎勵。
def plot_loss_reward(total_losses, total_rewards):
figure = tools.make_subplots(rows=1, cols=2, subplot_titles=('loss', 'reward'), print_grid=False)
figure.append_trace(Scatter(y=total_losses, mode='lines', line=dict(color='skyblue')), 1, 1)
figure.append_trace(Scatter(y=total_rewards, mode='lines', line=dict(color='orange')), 1, 2)
figure['layout']['xaxis1'].update(title='epoch')
figure['layout']['xaxis2'].update(title='epoch')
figure['layout'].update(height=400, width=900, showlegend=False)
iplot(figure)plot_loss_reward”使用Plotly庫的“make_subplots”函數創建一個帶有兩個子圖的圖形。在訓練周期內,該圖顯示了損失值和獎勵值的趨勢,提供了對DQN模型性能的洞察。
plot_loss_reward(total_losses, total_rewards)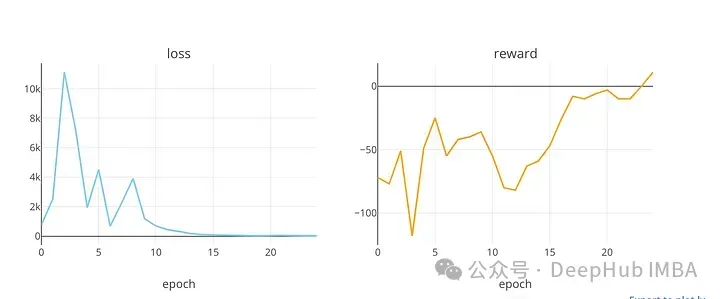
顯示了在訓練時期損失和獎勵值的趨勢。在DQN模型(可能用于股票市場預測)的訓練過程中,代碼使用該函數繪制損失和回報值。
def plot_train_test_by_q(train_env, test_env, Q, algorithm_name):
# train
pobs = train_env.reset()
train_acts = []
train_rewards = []
train_ongoing_profits = []
for _ in range(len(train_env.data)-1):
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
train_acts.append(pact)
obs, reward, done, profit = train_env.step(pact)
train_rewards.append(reward)
train_ongoing_profits.append(profit) pobs = obs
train_profits = train_env.profits
# test
pobs = test_env.reset()
test_acts = []
test_rewards = []
test_ongoing_profits = [] for _ in range(len(test_env.data)-1):
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
test_acts.append(pact)
deep_hub_obs, reward, done, profit = test_env.step(pact)
test_rewards.append(reward)
test_ongoing_profits.append(profit) pobs = obs
test_profits = test_env.profits
# plot
train_copy = train_env.data.copy()
test_copy = test_env.data.copy()
train_copy['act'] = train_acts + [np.nan]
train_copy['reward'] = train_rewards + [np.nan]
test_copy['act'] = test_acts + [np.nan]
test_copy['reward'] = test_rewards + [np.nan]
train0 = train_copy[train_copy['act'] == 0]
train1 = train_copy[train_copy['act'] == 1]
train2 = train_copy[train_copy['act'] == 2]
test0 = test_copy[test_copy['act'] == 0]
test1 = test_copy[test_copy['act'] == 1]
test2 = test_copy[test_copy['act'] == 2]
act_color0, act_color1, act_color2 = 'gray', 'cyan', 'magenta' data = [
Candlestick(x=train0.index, open=train0['Open'], high=train0['High'], low=train0['Low'], close=train0['Close'], increasing=dict(line=dict(color=act_color0)), decreasing=dict(line=dict(color=act_color0))),
Candlestick(x=train1.index, open=train1['Open'], high=train1['High'], low=train1['Low'], close=train1['Close'], increasing=dict(line=dict(color=act_color1)), decreasing=dict(line=dict(color=act_color1))),
Candlestick(x=train2.index, open=train2['Open'], high=train2['High'], low=train2['Low'], close=train2['Close'], increasing=dict(line=dict(color=act_color2)), decreasing=dict(line=dict(color=act_color2))),
Candlestick(x=test0.index, open=test0['Open'], high=test0['High'], low=test0['Low'], close=test0['Close'], increasing=dict(line=dict(color=act_color0)), decreasing=dict(line=dict(color=act_color0))),
Candlestick(x=test1.index, open=test1['Open'], high=test1['High'], low=test1['Low'], close=test1['Close'], increasing=dict(line=dict(color=act_color1)), decreasing=dict(line=dict(color=act_color1))),
Candlestick(x=test2.index, open=test2['Open'], high=test2['High'], low=test2['Low'], close=test2['Close'], increasing=dict(line=dict(color=act_color2)), decreasing=dict(line=dict(color=act_color2)))
]
title = '{}: train s-reward {}, profits {}, test s-reward {}, profits {}'.format(
deephub_algorithm_name,
int(sum(train_rewards)),
int(train_profits),
int(sum(test_rewards)),
int(test_profits)
)
layout = {
'title': title,
'showlegend': False,
'shapes': [
{'x0': date_split, 'x1': date_split, 'y0': 0, 'y1': 1, 'xref': 'x', 'yref': 'paper', 'line': {'color': 'rgb(0,0,0)', 'width': 1}}
],
'annotations': [
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'left', 'text': ' test data'},
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'right', 'text': 'train data '}
]
}
figure = Figure(data=data, layout=layout)
iplot(figure)
return train_ongoing_profits, test_ongoing_profitsPlot_train_test_by_q()將訓練好的DQN模型在訓練和測試數據集上的交易行為和性能可視化。
使用訓練好的Q-Network,該函數初始化環境并迭代訓練和測試數據。對于這兩個數據集,它都會累積行動、獎勵和持續利潤。
為了分析或比較算法的性能,該函數返回訓練和測試數據集的持續利潤。
train_profits, test_profits = plot_train_test_by_q(Environment(train), Environment(test), dqn, 'DQN')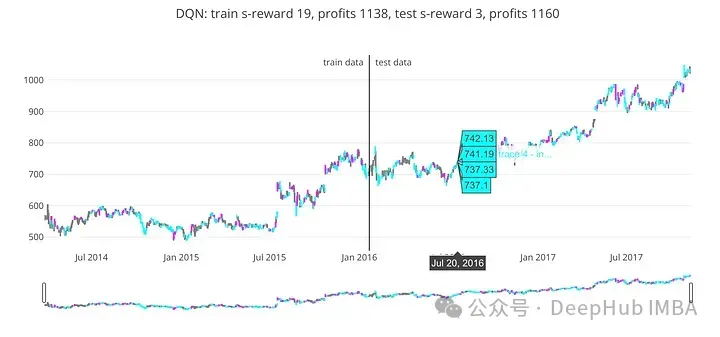
基于DQN模型的預測,' train_profits '變量接收從訓練數據中獲得的利潤。' test_profits '接收測試數據作為DQN模型預測的結果而獲得的利潤。
代碼在訓練和測試數據上評估訓練好的DQN模型,并計算每個數據集上獲得的利潤。這種評價可能有助于確定DQN模型的準確性和有效性。
我們還可以將,將DQN模型的性能與用于股市預測的“買入并持有”策略進行比較。Matplotlib的' plt '模塊用于生成繪圖。
plt.figure(figsize=(23,8))
plt.plot(data.index,((data['Close']-data['Close'][0])/data['Close'][-1]), label='buy and hold')
plt.plot(train.index, ([0] + train_profits)/data['Close'][-1], label='rl (train)')
plt.plot(test.index, (([0] + test_profits) + train_profits[-1])/data['Close'][-1], label='rl (test)')
plt.ylabel('relative gain')
plt.legend()
plt.show()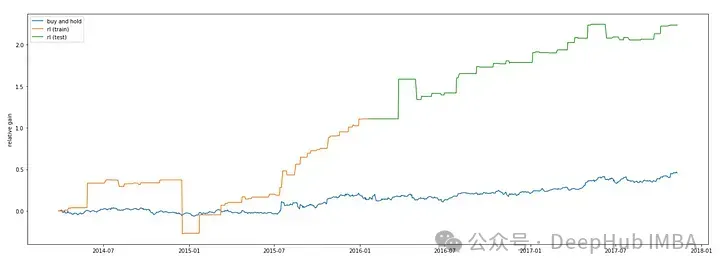
代碼繪制了在訓練數據上獲得的利潤。在該圖中,x軸表示訓練數據的指數,y軸表示DQN模型預測的相對收益。相對收益是通過將利潤除以輸入數據中的最后收盤價來計算的。
使用DQN模型,代碼繪制了在測試數據上獲得的利潤。x軸表示測試數據的指數,y軸表示DQN模型預測的相對利潤增益。通過將訓練利潤相加并除以導入數據中的最后收盤價來計算相對收益。該圖的標簽為“rl (test)”。
使用Matplotlib庫的“show”函數顯示該圖。在訓練和測試數據上,該圖顯示了“買入并持有”策略和DQN模型預測的相對利潤增益。將DQN模型與“買入并持有”等簡單策略進行比較,可以深入了解其有效性。
Double DQN
Double Deep Q-Network (DDQN) 是一種用于強化學習中的深度學習算法,特別是在處理離散動作空間的 Q-Learning 問題時非常有效。DDQN 是對傳統 Deep Q-Network (DQN) 的一種改進,旨在解決 DQN 在估計 Q 值時可能存在的過高估計(overestimation)問題。
DDQN 使用一個額外的神經網絡來評估選取最大 Q 值的動作。它不再直接使用目標 Q 網絡預測的最大 Q 值來更新當前 Q 網絡的 Q 值,而是使用當前 Q 網絡選擇的動作在目標 Q 網絡中預測的 Q 值來更新。這種方法通過減少動作選擇與目標 Q 值計算之間的相關性,有助于減輕 Q 值的過高估計問題。
def train_ddqn(env, epoch_num=50):
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
) def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y
def reset(self):
self.zerograds()
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q)
step_max = len(env.data)-1
memory_size = 200
batch_size = 50
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5 memory = []
total_step = 0
total_rewards = []
total_losses = [] start = time.time()
for epoch in range(epoch_num):
pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max: # select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data) # act
obs, reward, done, profit = env.step(pact) # add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0) # train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
deep_hub_shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact_deephub = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=np.bool)
q = Q(b_pobs)
""" <<< DQN -> Double DQN
maxq = np.max(Q_ast(b_obs).data, axis=1)
=== """
indices = np.argmax(q.data, axis=1)
maxqs = Q_ast(b_obs).data
""" >>> """
target = copy.deepcopy(q.data)
for j in range(batch_size):
""" <<< DQN -> Double DQN
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
=== """
target[j, b_pact[j]] = b_reward[j]+gamma*maxqs[j, indices[j]]*(not b_done[j])
""" >>> """
Q.reset()
loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q) # epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease # next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards上面代碼定義了一個函數train_ddqn(),該函數訓練Double Deep Q-Network (DDQN)來解決交易環境。
ddqn, total_losses, total_rewards = train_ddqn(Environment(train), epoch_num=50)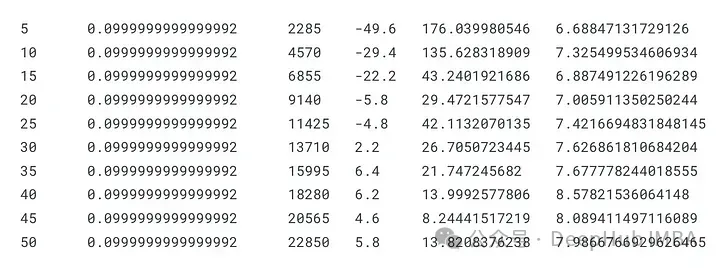
plot_loss_reward(total_losses, total_rewards)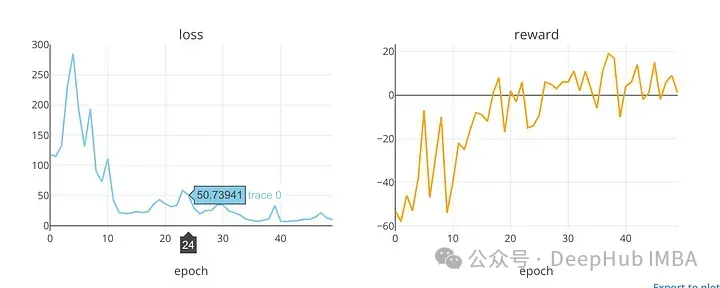
可視化了在訓練時期的損失和獎勵值的趨勢。在DDQN模型(可能用于預測股票市場價格)的訓練過程中,該函數繪制損失和回報值。
train_profits, test_profits = plot_train_test_by_q(Environment(train), Environment(test), ddqn, 'Double DQN')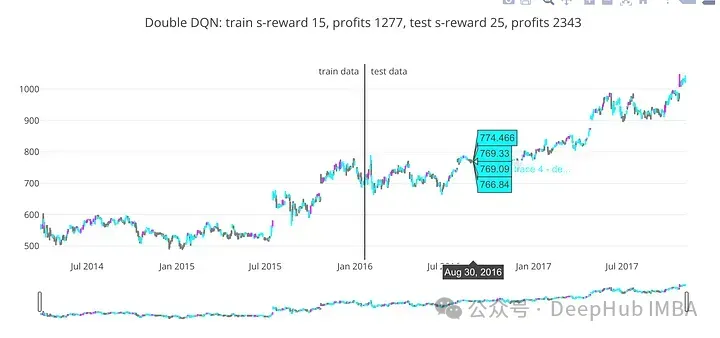
在訓練和測試數據上評估訓練后的DDQN模型的性能,為每個數據集獲得利潤。對于股票市場預測或其他需要強化學習的決策任務,此評估的結果可能有用。
plt.figure(figsize=(23,8))
plt.plot(data.index,((data['Close']-data['Close'][0])/data['Close'][-1]), label='buy and hold')
plt.plot(train.index, ([0] + train_profits)/data['Close'][-1], label='rl (train)')
plt.plot(test.index, (([0] + test_profits) + train_profits[-1])/data['Close'][-1], label='rl (test)')
plt.ylabel('relative gain')
plt.legend()
plt.show()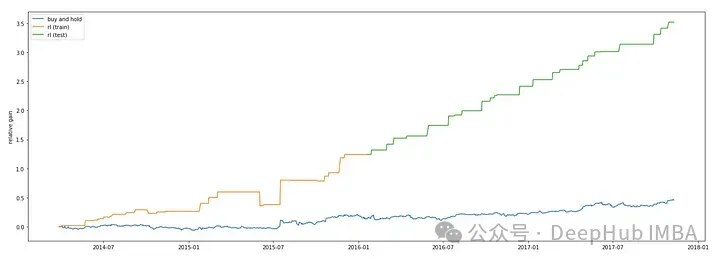
可以看到Double DQN要更高一些。這和Double Deep Q-Network的介紹: (DDQN)通過使用兩個神經網絡來分別估計當前策略選擇的動作和目標 Q 值的最大動作,有效解決了傳統 DQN 中的 Q 值過高估計問題,提高了在離散動作空間下的強化學習性能和穩定性。是相吻合的
Dueling Double DQN
Dueling Double Deep Q-Network (Dueling DDQN) 是一種結合了兩種技術的強化學習算法:Dueling網絡結構和Double DQN。它旨在進一步提高 Q-Learning 的效率和穩定性,特別是在處理離散動作空間的問題時非常有效。
def train_dddqn(env, epoch_num=50): """ <<< Double DQN -> Dueling Double DQN
class Q_Network(chainer.Chain): def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
) def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y def reset(self):
self.zerograds()
=== """
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, hidden_size//2),
fc4 = L.Linear(hidden_size, hidden_size//2),
state_value = L.Linear(hidden_size//2, 1),
advantage_value = L.Linear(hidden_size//2, output_size)
)
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
hs = F.relu(self.fc3(h))
ha = F.relu(self.fc4(h))
state_value = self.state_value(hs)
advantage_value = self.advantage_value(ha)
advantage_mean = (F.sum(advantage_value, axis=1)/float(self.output_size)).reshape(-1, 1)
q_value = F.concat([state_value for _ in range(self.output_size)], axis=1) + (advantage_value - F.concat([advantage_mean for _ in range(self.output_size)], axis=1))
return q_value
def reset(self):
self.zerograds()
""" >>> """
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q) step_max = len(env.data)-1
memory_size = 200
batch_size = 50
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5 memory = []
total_step = 0
total_rewards = []
total_losses = []
start = time.time()
for epoch in range(epoch_num):
pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max: # select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data) # act
obs, reward, done, profit = env.step(pact) # add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0) # train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
deephub_batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=np.bool) q = Q(b_pobs)
""" <<< DQN -> Double DQN
maxq = np.max(Q_ast(b_obs).data, axis=1)
=== """
indices = np.argmax(q.data, axis=1)
maxqs = Q_ast(b_obs).data
""" >>> """
target = copy.deepcopy(q.data)
for j in range(batch_size):
""" <<< DQN -> Double DQN
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
=== """
target[j, b_pact[j]] = b_reward[j]+gamma*maxqs[j, indices[j]]*(not b_done[j])
""" >>> """
Q.reset()
loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q) # epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease # next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards在call方法中,前兩層在兩個流之間共享,然后分成兩個獨立的流。狀態價值流有一個輸出單個值的額外線性層(state_value),而優勢價值流有一個為每個動作輸出值的額外線性層(advantage_value)。最終的q值由狀態值和優勢值結合計算,并減去平均優勢值以保持穩定性。代碼的其余部分與Double DQN實現非常相似。
dddqn, total_losses, total_rewards = train_dddqn(Environment(train), epoch_num=25)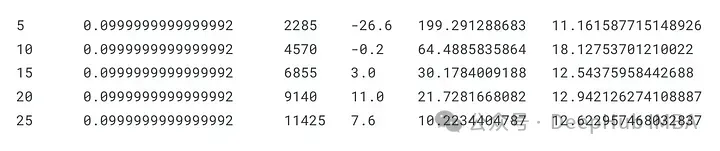
plot_loss_reward(total_losses, total_rewards)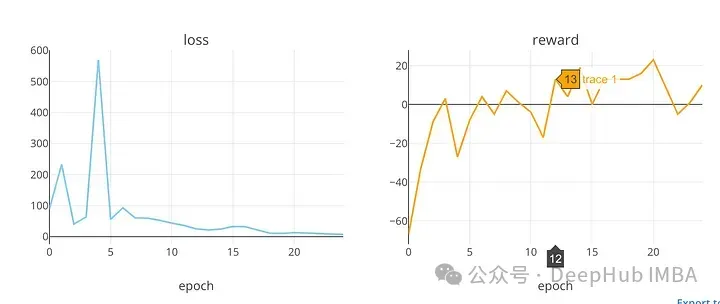
train_profits, test_profits = plot_train_test_by_q(Environment(train), Environment(test), dddqn, 'Dueling Double DQN')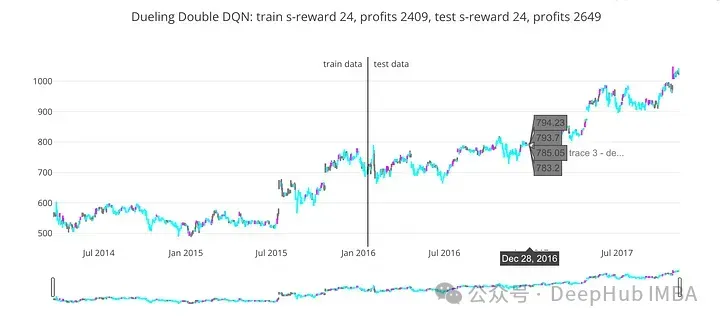
plt.figure(figsize=(23,8))
plt.plot(data.index,((data['Close']-data['Close'][0])/data['Close'][-1]), label='buy and hold')
plt.plot(train.index, ([0] + train_profits)/data['Close'][-1], label='rl (train)')
plt.plot(test.index, (([0] + test_profits) + train_profits[-1])/data['Close'][-1], label='rl (test)')
plt.plot(test.index, (([0] + test_profits) - data['Close'][0] + data['Close'][len(train_profits)])/data['Close'][-1], label='rl (test)')
plt.ylabel('relative gain')
plt.legend()
plt.show()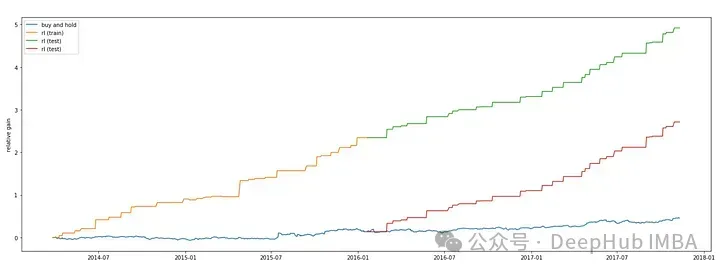
Dueling Double Deep Q-Network (Dueling DDQN) 是一種結合了 Dueling 網絡結構和 Double DQN 的強化學習算法。它通過將 Q 函數分解為狀態值函數和優勢函數來提高效率,同時利用 Double DQN 的思想來減少 Q 值的過高估計,從而在處理離散動作空間下的強化學習問題中表現出色。
總結
讓我們對傳統的 Deep Q-Network (DQN), Double DQN, Dueling DQN 和 Dueling Double DQN 進行對比總結,看看它們各自的特點和優劣勢。
1、Deep Q-Network (DQN)
特點
- 使用深度神經網絡來估計 Q 函數,從而學習到每個狀態下每個動作的價值。
- 使用經驗回放和固定 Q 目標網絡來提高穩定性和收斂性。
優點
- 引入深度學習提高了 Q 函數的表示能力,能夠處理復雜的狀態和動作空間。
- 經驗回放和固定 Q 目標網絡有助于穩定訓練過程,減少樣本間的相關性。
缺點
- 存在 Q 值的過高估計問題,尤其是在動作空間較大時更為明顯,這可能導致訓練不穩定和性能下降。
2、Double Deep Q-Network (Double DQN)
特點
- 解決了 DQN 中 Q 值過高估計的問題。
- 引入一個額外的目標 Q 網絡來計算目標 Q 值,減少更新時的相關性。
優點
- 減少了 Q 值的過高估計,提高了訓練的穩定性和收斂性。
缺點
- 算法結構相對簡單,對于某些復雜問題可能需要更高的表示能力。
3、Dueling Double Deep Q-Network (Dueling DDQN)
特點
- 結合了 Dueling 網絡結構和 Double DQN 的優勢。
- 使用 Dueling 網絡結構來分解 Q 函數,提高了效率和學習表示能力。
使用 Double DQN 的思想來減少 Q 值的過高估計問題。
優點
- 綜合了兩種技術的優勢,能夠在更廣泛的問題空間中表現出色。
- 提高了訓練的穩定性和效率,有助于更快地收斂到較好的策略。
缺點
- 算法實現和調優可能比單一 DQN 及其改進版更復雜。
總結比較
- 效果和穩定性:Dueling DDQN 在處理動作空間較大的問題時表現出更高的效率和穩定性,因為它們能夠更有效地分離狀態值和動作優勢。
- 過高估計問題:Dueling DDQN 解決了傳統 DQN 中 Q 值過高估計的問題,其中 Double DQN 通過目標網絡降低相關性,而 Dueling 結構則通過優勢函數減少過高估計。
- 復雜性:Dueling DDQN 相對于傳統 DQN 和 Double DQN 更復雜,需要更多的實現和理解成本,但也帶來了更好的性能。
傳統 DQN 適用于簡單的強化學習任務,而 Double DQN、Dueling DDQN 則適用于更復雜和具有挑戰性的問題,根據問題的特性選擇合適的算法可以有效提升訓練效率和性能。
最后我們也看到,深度強化學習預測股票是可行的,因為他不再預測具體的股票價格,而是針對收益預測買進,賣出和持有,我們這里只是使用了股票本身的數據,如果有更多的外生數據那么強化學習應該可以模擬更準確的人工操作。