RAGFlow開源Star量破萬,是時候思考下RAG的未來是什么了
本文作者為張穎峰,英飛流 InfiniFlow 創始人 CEO,連續創業者,先后負責 7 年搜索引擎研發,5 年數據庫內核研發,10 年云計算基礎架構和大數據架構研發,10 年人工智能核心算法研發,包括廣告推薦引擎,計算機視覺和自然語言處理。先后主導并參與三家大型企業數字化轉型,支撐過日活千萬,日均兩億動態搜索請求的互聯網電商業務。
搜索技術是計算機科學中最難的技術挑戰之一,迄今只有很少一部分商業化產品可以把這個問題解決得很好。大多數商品并不需要很強的搜索,因為這和用戶體驗并沒有直接關系。然而,隨著 LLM 的爆炸性增長,每家使用 LLM 的公司都需要內置一個強大的檢索系統,才能使得 LLM 可以真正為企業用起來,這就是 RAG (基于檢索增強的內容生成)—— 通過搜索內部信息給 LLM 提供與用戶提問最相關的內容,來幫助 LLM 做最終的答案生成。
想象一下,LLM 正在針對用戶提問回答,如果沒有 RAG,那么 LLM 不得不根據自己在訓練過程中學到的知識來回憶內容,而有了 RAG 之后,這種問題回答就如同開卷考試,到教科書中去尋找包含答案的段落,因此回答問題變得容易很多。隨著 LLM 的演進,新的 LLM 具有更長的上下文窗口,可以處理更大的用戶輸入,如果可以直接在上下文窗口中載入整個教科書,為什么還需要去教科書中翻答案呢?實際上,對于大多數應用而言,即使 LLM 可以包含上百萬乃至上千萬 Token 的上下文窗口,搜索依然必不可少:
- 企業通常包含多個版本的類似文檔,將它們全部傳給 LLM 會導致相互沖突的信息。
- 大多數企業內部場景都需要對傳給上下文窗口的內容做訪問權限控制。
- LLM 更容易受到跟問題語義相關但卻跟答案無關內容的干擾,從而分心。
- 即使 LLM 能力很強大,也沒有必要浪費多很多的成本和延遲來處理跟用戶提問不相關的數百萬個 Token 。
RAG 從出現到流行只花了很短的時間,這得益于各種 LLMOps 工具迅速將如下的組件串接起來使得整個系統得以運轉。
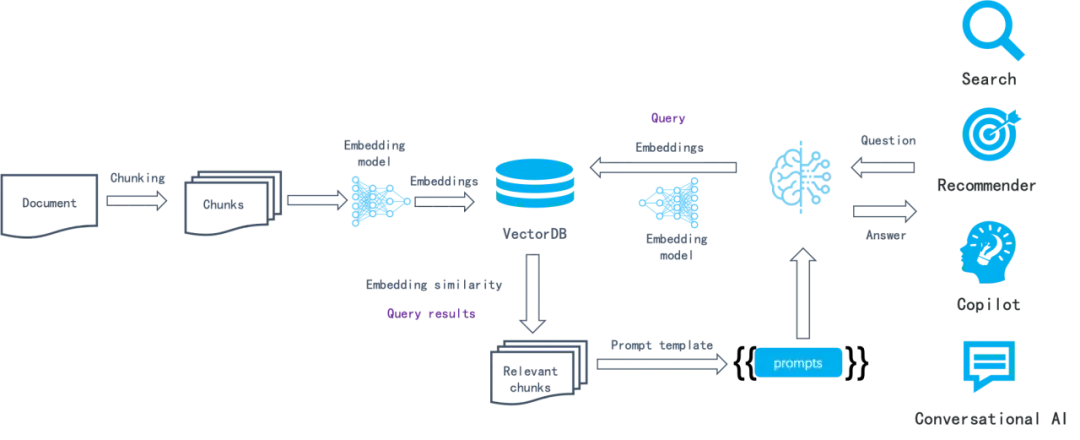
以上這種基于語義相似度的方法已經工作了很多年:首先,將數據分塊(例如根據段落),然后通過 Embedding 模型把每個塊轉成向量保存到向量數據庫。在檢索過程中,把提問也轉成向量,接著通過向量數據庫檢索到最接近該向量的數據塊,這些數據塊理論上包含跟查詢語義最相似的數據。
在整個鏈路中,LLMOps 工具可以操作的事情有:
- 解析和切分文檔。通常采用固定大小來把解析好的文本切成數據塊。
- 編排任務,包括數據寫入和查詢時,負責把數據塊發到 Embedding 模型(既包含私有化也包含 SaaS API);返回的向量連同數據塊共同發給向量數據庫;根據提示詞模板拼接向量數據庫返回的內容。
- 業務邏輯組裝。例如用戶對話內容的生成和返回,對話跟業務系統(如客服系統)的連接,等等。
這個流程的建立很簡單,但搜索效果卻很一般,因為這套樸素的基于語義相似度的搜索系統包含若干局限:
- Embedding 是針對整塊文本的處理,對于一個特定的問題,它無法區分文字中特定的實體 / 關系 / 事件等權重明顯需要提高的 Token,這樣導致 Embedding 的有效信息密度有限,整體召回精度不高。
- Embedding 無法實現精確檢索。例如如果用戶詢問 “2024 年 3 月我們公司財務計劃包含哪些組合”,那么很可能得到的結果是其他時間段的數據,或者得到運營計劃,營銷管理等其他類型的數據。
- 對 Embedding 模型很敏感,針對通用領域訓練的 Embedding 模型在垂直場景可能表現不佳。
- 對如何數據分塊很敏感,輸入數據的解析、分塊和轉換方式不同,導致的搜索返回結果也會大不同。而依托于 LLMOps 工具的體系,對于數據分塊的邏輯往往簡單粗暴,忽視了數據本身的語義和組織。
- 缺乏用戶意圖識別。用戶的提問可能并沒有明確的意圖,因此即便解決了前述的召回精度問題,在意圖不明的情況下,也沒有辦法用相似度來找到答案。
- 無法針對復雜提問進行回答,例如多跳問答(就是需要從多個來源收集信息并進行多步推理才能得出綜合答案的問題。
因此可以把這類以 LLMOps 為核心的 RAG 看作 1.0 版本,它的主要特點在于重編排而輕效果,重生態而輕內核。因此,從面世一開始就迅速普及,普通開發者可以借助于這些工具快速搭建起原型系統,但在深入企業級場景時,卻很難滿足要求,并且經常處于無計可施的狀態。隨著 LLM 快速向更多場景滲透,RAG 也需要快速進化,畢竟搜索系統的核心是找到答案,而不是找到最相似的結果。基于這些,我們認為未來的 RAG 2.0 可能是這樣工作的:

其主要特點為:
1.RAG 2.0 是以搜索為中心的端到端系統,它將整個 RAG 按照搜索的典型流程劃分為若干階段:包含數據的信息抽取、文檔預處理、構建索引以及檢索。RAG 2.0 是典型的 AI Infra,區別于以現代數據棧為代表的 Data Infra,它無法用類似的 LLMOps 工具來編排。因為以上環節之間相互耦合,接口遠沒有到統一 API 和數據格式的地步,并且環節之間還存在循環依賴。例如對問題進行查詢重寫,是解決多跳問答、引入用戶意圖識別必不可少的環節。查詢重寫和獲得答案,是一個反復檢索和重寫的過程,編排在這里不僅不重要,甚至會干擾搜索和排序的調優。近期知名的 AI 編排框架 LangChain 遭到吐槽,就是同樣的道理。
2. 需要一個更全面和強大的數據庫,來提供更多的召回手段,這是由于為解決 RAG 1.0 中召回精度不高的痛點,需要采用多種方法混合搜索。除了向量搜索之外,還應該包含關鍵詞全文搜索、稀疏向量搜索,乃至支持類似 ColBERT 這樣 Late Interaction 機制的張量搜索。
a. 關鍵詞全文搜索是實現精確查詢必不可少的手段,當用戶檢索意圖明確時,期望的文檔卻沒有返回,這會使他感到沮喪。其次,通過關鍵詞全文搜索,可以查看跟查詢匹配的關鍵詞,從而更直觀地了解檢索到該文檔的原因,這對于排序的可解釋性也非常重要。所以在絕大多數情況下,都不應該把關鍵詞全文搜索排除在 RAG 之外。全文搜索是個很成熟的功能,但并不等于實現它很容易。除了需要能夠處理海量數據之外,為符合 RAG 召回的需要,還必須提供默認基于 Top K Union 語義的搜索機制,這是由于 RAG 的查詢輸入通常不是幾個關鍵詞,而是整句話。目前市面上大多數聲稱提供 BM25 和全文搜索能力的數據庫,實現的都是閹割版本,既無法高性能搜索海量數據,也無法提供有效召回,不具備企業級服務能力。
b.IBM 研究院最新的研究成果顯示,在若干問答數據集的評測中,聯合關鍵詞全文搜索、稀疏向量、以及向量搜索 3 種召回方式,取得了 SOTA 的結果。因此,有理由在數據庫中原生支持這種 3 路混合搜索能力。
c. 張量搜索是一種很新的檢索方式。它來自于以 ColBERT 為代表的 Late Interaction 機制。簡單地總結,就是 Cross Encoder 為代表的 Reranker 模型,它能夠捕捉查詢和文檔之間的復雜交互關系,因此相比向量搜索能夠提供更精準的搜索排序結果。但是它的缺點在于,由于需要在查詢時對每個文檔和查詢共同經過 Embedding 模型來編碼,這使得排序的速度非常慢,因此 Cross-Encoder 只能用于最終結果的重排序。而類似 ColBERT 這樣的模型,它仍然把文檔在索引階段就編碼好,這一點類似于向量搜索,但不同之處在于,它把文檔的每個 Token 都用單獨的向量表示,因此是用許多向量或者一個張量來表示一個文檔,在排序計算時,所有 Token 之間的向量都需要做交叉計算,這一點跟 Cross Encoder 的機制類似,因此比向量搜索損失的信息更少,召回精度更高。而相比 Cross Encoder,它的性能要好得多,因為在查詢期間無需對每個文檔進行編碼, 所以可以理解為既擁有接近 Cross Encoder 的召回精度,也擁有接近向量搜索的性能,這樣可以在召回階段就引入更好的模型,具有非常強的實際操作價值。結合張量搜索和關鍵詞全文搜索,不失為一種非常值得采用的混合搜索能力。作為數據庫來說,同樣需要為這樣的能力提供選擇。
近期 OpenAI 收購了數據倉庫公司 Rockset,這背后的邏輯,其實并不在于數據倉庫本身對于 RAG 有多么大的價值,而是相比其他數據倉庫,Rockset 更是一個索引數據庫,它對表的每列數據都建立了倒排索引,因此可以提供類比于 Elasticsearch 的關鍵詞全文搜索能力,再配套以向量搜索,原生具備這 2 類混合搜索能力的數據庫,在當前階段,就已經沒有多少選擇了,再加上 Rockset 還采用了云原生架構,2 點結合,是 OpenAI 做出選擇的主要原因。這些考慮,也是我們在另外開發 AI 原生數據庫 Infinity 的主要原因,我們期望它能原生地包含前述的所有能力,從而可以更好地支撐 RAG 2.0。
3. 數據庫只能涵蓋 RAG 2.0 中的數據檢索和召回環節,還需要站在整個 RAG 的鏈路上,針對各環節進行優化,這包括:
a. 需要有單獨的數據抽取和清洗模塊,來針對用戶的數據,進行切分。切分的粒度,需要跟最終搜索系統返回的結果進行迭代。數據抽取模塊,需要考慮到用戶的各種不同格式,包含復雜文檔例如表格處理和圖文等,因此它必須依托于若干模型才能完成任務。高質量的數據抽取模塊,是保證高質量搜索的前置條件。這部分可以類比為現代數據棧的 ETL,但卻比 ETL 更加復雜,后者是以 SQL 為核心的的確定性規則系統,而前者則是以各種文檔結構識別模型為核心的非標準化體系。
b. 抽取出的數據,在送到數據庫索引之前,還可能需要若干預處理步驟,包括知識圖譜構建,文檔聚類,以及針對垂直領域的 Embedding 模型微調等。這些工作,本質上是為了輔助在檢索階段提供更多的依據,從而讓檢索更加精準。這個步驟不可或缺,它是針對用戶的復雜提問,例如多跳問答,意圖不確定,以及垂直問答等情況下的必要手段。通過把文檔中包含的內部知識以多種方式組織,才能確保在召回結果包含所需要的答案。
c. 檢索階段分為粗篩和精排。精排通常放在數據庫外進行,因為它需要不同的重排序模型。除此之外,還需要對用戶的查詢不斷改寫,根據模型識別出的用戶意圖不斷改寫查詢,然后檢索直至找到滿意的答案。
這些階段,可以說每個環節都是圍繞模型來工作的。它們聯合數據庫一起,共同保證最終問答的效果。
因此,RAG 2.0 相比 RAG 1.0 會復雜很多,其核心是數據庫和各種模型,需要依托一個平臺來不斷迭代和優化,這就是我們開發并開源 RAGFlow 的原因。它沒有采用已有的 RAG 1.0 組件,而是從整個鏈路出發來根本性地解決 LLM 搜索系統的問題。當前,RAGFlow 仍處于初級階段,系統的每個環節,都還在不斷地進化中。由于使用了正確的方式解決正確的問題,因此自開源以來 RAGFlow 只用了不到 3 個月就獲得了 Github 萬星。當然,這只是新的起點。