













導(dǎo)航、采礦、建造,北大這個(gè)新智能體把《我的世界》玩透了
該研究成果由來(lái)自北京大學(xué)的蔡少斐、王子豪、連可為、牟湛存、來(lái)自北京通用人工智能研究院的馬曉健研究員、來(lái)自加州大學(xué)洛杉磯分校的劉安吉共同完成。通訊作者為北京大學(xué)助理教授梁一韜。所有作者均隸屬 CraftJarvis 研究團(tuán)隊(duì)。
在游戲和機(jī)器人研究領(lǐng)域,讓智能體在開放世界環(huán)境中實(shí)現(xiàn)有效的交互,一直是令人興奮卻困難重重的挑戰(zhàn)。想象一下,智能體在《我的世界(Minecraft)》這樣的環(huán)境中,不僅要識(shí)別和理解復(fù)雜的視覺信息,還需要利用鼠標(biāo)和鍵盤精細(xì)地控制游戲畫面,快速做出反應(yīng),完成像導(dǎo)航、采礦、建造、與生物互動(dòng)等任務(wù)。面對(duì)如此龐大且復(fù)雜的交互空間,如何能讓智能體能理解并執(zhí)行人類的意圖呢?

針對(duì)這個(gè)問題,CraftJarvis 團(tuán)隊(duì)提出利用 VLMs (視覺語(yǔ)言模型)強(qiáng)大的視覺語(yǔ)言推理能力來(lái)指導(dǎo)任務(wù)的完成,并創(chuàng)新地提出了一種基于視覺 - 時(shí)間上下文提示(Visual-Temporal Context Prompting)的任務(wù)表示方法。該方法允許人類或 VLMs 在當(dāng)前和歷史游戲畫面中將希望進(jìn)行交互的物體分割出來(lái),來(lái)傳達(dá)具體的交互意圖。為了將交互意圖映射為具體的鼠標(biāo)鍵盤操作,該團(tuán)隊(duì)進(jìn)一步訓(xùn)練了一個(gè)以物體分割為條件的底層策略 ROCKET-1。這種融合了視覺 - 時(shí)間上下文提示的智能體架構(gòu)為開放世界的交互奠定了基礎(chǔ),預(yù)示了未來(lái)游戲 AI 和機(jī)器人互動(dòng)的新可能性。

- 論文鏈接: https://arxiv.org/pdf/2410.17856
- 項(xiàng)目主頁(yè): https://craftjarvis.github.io/ROCKET-1
研究創(chuàng)新點(diǎn)
視覺 - 時(shí)間上下文提示方法

架構(gòu)對(duì)比圖;(e) 為基于視覺 - 時(shí)間上下文提示的新型架構(gòu)
視覺 - 時(shí)間上下文提示是一種全新的任務(wù)表達(dá)方式。通過整合智能體過去和當(dāng)前的觀察信息,該方法利用物體分割信息,為智能體提供空間和交互類型的線索,從而讓低級(jí)策略能夠準(zhǔn)確識(shí)別和理解環(huán)境中的關(guān)鍵對(duì)象。這一創(chuàng)新使得智能體能夠在執(zhí)行任務(wù)時(shí)始終保持對(duì)目標(biāo)對(duì)象的關(guān)注。
基于物體分割的條件策略 ROCKET-1

基于因果 Transformer 實(shí)現(xiàn)的 ROCKET-1 架構(gòu)
ROCKET-1 是一種基于視覺 - 時(shí)間上下文的低級(jí)策略,能夠在視覺觀察和分割掩碼的支持下預(yù)測(cè)行動(dòng)。通過使用 Transformer 模塊,ROCKET-1 可以在部分可觀測(cè)(Partially Observable)環(huán)境中推理過去和當(dāng)前觀測(cè)的依賴關(guān)系,實(shí)現(xiàn)精準(zhǔn)的動(dòng)作預(yù)測(cè)。與傳統(tǒng)方法不同,ROCKET-1 能夠處理細(xì)微的空間和時(shí)序變化,并始終關(guān)注要進(jìn)行交互的物體,顯著提升了與環(huán)境交互的成功率。
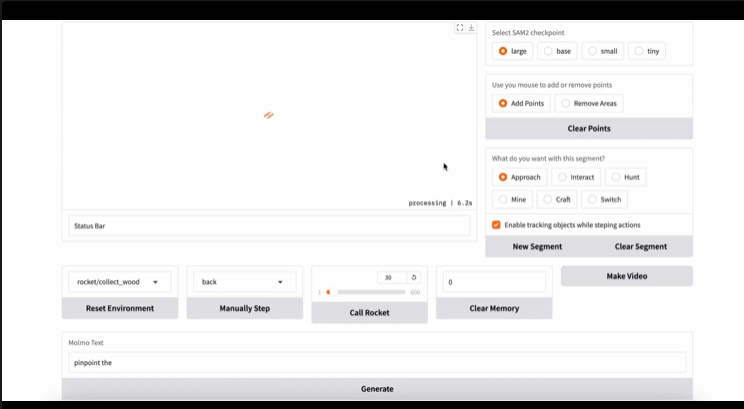
反向軌跡重標(biāo)注策略

反向軌跡重標(biāo)記流程示意
訓(xùn)練 ROCKET-1 需要收集大量帶有物體分割的軌跡數(shù)據(jù)。傳統(tǒng)的數(shù)據(jù)標(biāo)注方法成本高、效率低,CraftJarvis 團(tuán)隊(duì)提出了一種逆向軌跡重標(biāo)注方法,利用 SAM-2 的物體分割能力在倒放的視頻中連續(xù)地對(duì)發(fā)生交互的物體生成分割注釋。這種方法能夠根據(jù)現(xiàn)有的交互事件重建數(shù)據(jù)集,使得 ROCKET-1 在離線條件下即可完成高效訓(xùn)練,減少了對(duì)人工標(biāo)注的依賴,并為大規(guī)模數(shù)據(jù)處理提供了切實(shí)可行的解決方案。
充分釋放預(yù)訓(xùn)練基礎(chǔ)模型的能力

CraftJarvis 團(tuán)隊(duì)將具身決策所依賴的能力分解為視覺語(yǔ)言推理、視覺空間定位、物體追蹤和實(shí)時(shí)動(dòng)作預(yù)測(cè),并巧妙地組合 GPT-4o、Molmo、SAM-2、ROCKET-1 加以解決。
為了應(yīng)對(duì)復(fù)雜任務(wù)規(guī)劃的挑戰(zhàn),該團(tuán)隊(duì)引入了 GPT-4o,目前最先進(jìn)的視覺語(yǔ)言模型之一。可以進(jìn)行強(qiáng)大的視覺語(yǔ)言推理,將復(fù)雜的任務(wù)分解為一系列具體的物體交互指令。此外,該團(tuán)隊(duì)采用了 Molmo 模型來(lái)將 GPT-4o 的交互意圖翻譯為觀察圖像中的坐標(biāo)點(diǎn),用以精確定位交互物體。
為了應(yīng)對(duì)對(duì)象跟蹤的挑戰(zhàn),該團(tuán)隊(duì)引入了 SAM-2,一個(gè)先進(jìn)的視頻分割模型。SAM-2 不僅能夠通過點(diǎn)提示對(duì)物體進(jìn)行分割,還可以在時(shí)間上連續(xù)追蹤目標(biāo),即便物體在視野中消失或重新出現(xiàn)時(shí)也能有效保持跟蹤。這為 ROCKET-1 提供了穩(wěn)定的對(duì)象信息流,確保了在高頻變化的環(huán)境中智能體的交互精度。
實(shí)驗(yàn)成果
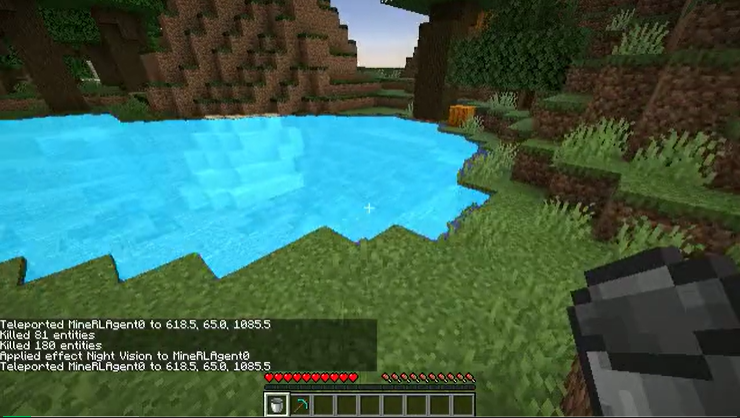
為了驗(yàn)證 ROCKET-1 的交互能力,CraftJarvis 團(tuán)隊(duì)在《我的世界》中設(shè)計(jì)了一系列任務(wù),包括采礦、放置物品、導(dǎo)航和與生物互動(dòng)等。

《我的世界》交互任務(wù)評(píng)測(cè)集

ROCKET-1 評(píng)測(cè)結(jié)果
實(shí)驗(yàn)結(jié)果顯示,ROCKET-1 在這些任務(wù)上,尤其在一些具有高空間敏感性的任務(wù)中,獲得的成功率遠(yuǎn)高于現(xiàn)有方法(在多數(shù)任務(wù)上實(shí)現(xiàn)了高達(dá) 90% 的成功率提升),ROCKET-1 表現(xiàn)出了出色的泛化能力。即便在訓(xùn)練集中從未出現(xiàn)的任務(wù)(如將木門放到鉆石塊上),ROCKET-1 依然能夠借助 SAM-2 的物體追蹤能力完成指定目標(biāo),體現(xiàn)了其在未知場(chǎng)景中的適應(yīng)性。
此外,該團(tuán)隊(duì)也設(shè)計(jì)了一些需要較為復(fù)雜的推理能力的長(zhǎng)期任務(wù),同樣展示了這套方法的杰出性能。

ROCKET-1 在解決任務(wù)時(shí)的截圖

需要依賴規(guī)劃能力的長(zhǎng)期任務(wù)性能結(jié)果
視覺 - 時(shí)間上下文方法的提出和 ROCKET-1 策略的開發(fā)不僅為 Minecraft 中的復(fù)雜任務(wù)帶來(lái)了全新解決方案,也在通用機(jī)器人控制、通用視覺導(dǎo)航等領(lǐng)域展示了廣泛的應(yīng)用前景。






















