一致哈希算法:如何分群,突破集群的“領導者”限制?
作者:架構師秋天
一致哈希算法 是解決分布式KV存儲中數據遷移問題的重要手段。通過邏輯哈希環和虛擬節點技術,可以有效避免傳統哈希算法的遷移瓶頸,并實現較好的負載均衡。
一、一致哈希算法的背景
1.1 傳統哈希算法的問題
在傳統的哈希算法中,數據存儲通常采用如下映射關系:
node=hash(key)%Nnode = hash(key) \% N
- key:數據的鍵
- N:當前集群中節點的數量
問題:當節點數量發生變化(例如從2個節點擴展到3個節點),幾乎所有的鍵都會被重新分配到不同的節點上,導致大量數據遷移。
示例:
- 2個節點:hash(key) % 2 → 節點0、節點1
- 擴展到3個節點:hash(key) % 3 → 節點0、節點1、節點2
可以看到,大部分數據的映射發生了變化。
1.2 一致哈希的引入
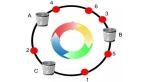
一致哈希算法 使用了一個邏輯哈希環(Hash Ring)的概念,將整個哈希空間(0到2^32-1)組織成一個環形結構。每個節點和數據的Key都通過哈希函數映射到哈希環上。數據會存儲到順時針方向上第一個大于等于該Key的節點上。
1.3 一致哈希的優點
- 數據遷移量小:當一個節點加入或移除時,只影響它在哈希環上的相鄰節點。
- 可擴展性強:節點可以自由加入或退出,不會對整個系統產生大規模影響。
- 負載均衡:結合虛擬節點(Virtual Node)技術,能有效解決節點分布不均勻的問題。
二、一致哈希算法原理
2.1 哈希環
一致哈希將哈希空間組織成一個邏輯的環形結構,哈希值的范圍是 0→232?10 \rightarrow 2^{32}-1。
- 節點映射:通過哈希函數將每個節點映射到環上的某個位置。
- Key映射:將每個Key映射到環上的某個位置。
- 數據存儲規則:Key存儲到順時針方向遇到的第一個節點上。
2.2 虛擬節點(Virtual Nodes)
實際場景中,節點可能會分布不均勻,導致某些節點負載較高。為了解決這個問題,引入了虛擬節點,即為每個實際節點分配多個哈希值,使節點分布更加均勻。
2.3 數據遷移
- 節點增加:新節點只接管部分相鄰節點的數據。
- 節點移除:原本分配到該節點的數據會被順時針下一個節點接管。
三、一致哈希的核心實現
接下來,我們通過 Go語言 來實現一個簡單的一致哈希算法,并添加詳細的注釋。
3.1 基本結構定義
packageconsistenthash
import (
"hash/crc32"
"sort"
"strconv"
)
// 一致性哈希結構體
typeConsistentHashstruct {
hash func(data []byte) uint32 // 哈希函數
replicasint // 虛擬節點倍數
keys []int // 哈希環上的所有虛擬節點
nodes map[int]string // 虛擬節點到真實節點的映射
}
// 構造函數
funcNewConsistentHash(replicasint, fnfunc(data []byte) uint32) *ConsistentHash {
m :=&ConsistentHash{
replicas: replicas,
hash: fn,
nodes: make(map[int]string),
}
ifm.hash==nil {
m.hash=crc32.ChecksumIEEE// 默認哈希函數
}
returnm
}3.2 添加節點
// 添加節點
func (m*ConsistentHash) AddNode(nodes...string) {
for_, node :=rangenodes {
fori :=0; i<m.replicas; i++ {
// 為每個節點生成多個虛擬節點
hash :=int(m.hash([]byte(node+strconv.Itoa(i))))
m.keys=append(m.keys, hash)
m.nodes[hash] =node
}
}
// 對所有節點進行排序,保證哈希環的有序性
sort.Ints(m.keys)
}3.3 獲取節點
// 獲取節點
func (m*ConsistentHash) GetNode(keystring) string {
iflen(m.keys) ==0 {
return""
}
hash :=int(m.hash([]byte(key)))
// 順時針找到第一個大于哈希值的節點
idx :=sort.Search(len(m.keys), func(iint) bool {
returnm.keys[i] >=hash
})
ifidx==len(m.keys) {
idx=0// 環狀回到第一個節點
}
returnm.nodes[m.keys[idx]]
}3.4 移除節點
// 移除節點
func (m*ConsistentHash) RemoveNode(nodestring) {
fori :=0; i<m.replicas; i++ {
hash :=int(m.hash([]byte(node+strconv.Itoa(i))))
delete(m.nodes, hash)
fori, v :=rangem.keys {
ifv==hash {
m.keys=append(m.keys[:i], m.keys[i+1:]...)
break
}
}
}
}3.5 測試示例
packagemain
import (
"fmt"
"consistenthash"
)
funcmain() {
ch :=consistenthash.NewConsistentHash(3, nil)
ch.AddNode("NodeA", "NodeB", "NodeC")
fmt.Println("Key-1 is mapped to:", ch.GetNode("Key-1"))
fmt.Println("Key-2 is mapped to:", ch.GetNode("Key-2"))
ch.AddNode("NodeD") // 添加新節點
fmt.Println("After adding NodeD:")
fmt.Println("Key-1 is mapped to:", ch.GetNode("Key-1"))
fmt.Println("Key-2 is mapped to:", ch.GetNode("Key-2"))
}四、一致哈希的優缺點
4.1 優點
- 擴展性強:節點加入/退出只影響少部分數據。
- 負載均衡:結合虛擬節點,負載更均勻。
- 容錯性強:節點故障時,影響范圍較小。
4.2 缺點
- 虛擬節點配置:虛擬節點的配置需要平衡性能和分布。
- 數據傾斜:即使使用虛擬節點,仍然可能存在輕微的不均勻。
五、總結
一致哈希算法 是解決分布式KV存儲中數據遷移問題的重要手段。通過邏輯哈希環和虛擬節點技術,可以有效避免傳統哈希算法的遷移瓶頸,并實現較好的負載均衡。
責任編輯:武曉燕
來源:
架構師秋天