CTO 問我,為什么不按照教材上的 3NF 來設(shè)計數(shù)據(jù)庫?
有水友問我說,學校學數(shù)據(jù)庫,都講究“范式設(shè)計”,為什么很多互聯(lián)網(wǎng)公司數(shù)據(jù)庫都搞“反范式”設(shè)計呢?

什么是數(shù)據(jù)庫范式設(shè)計?
- 1NF:字段原子性;
- 2NF:所有字段必須依賴主鍵;
- 3NF:所有字段必須直接依賴主鍵;
為什么要搞數(shù)據(jù)庫范式設(shè)計?
減少數(shù)據(jù)冗余,減少數(shù)據(jù)依賴,確保數(shù)據(jù)一致性與完整性。
為什么很多互聯(lián)網(wǎng)公司數(shù)據(jù)庫都搞“反范式”設(shè)計?
任何脫離業(yè)務的數(shù)據(jù)庫設(shè)計都是耍流氓。
很多互聯(lián)網(wǎng)業(yè)務場景,數(shù)據(jù)的一致性與完整性并不是主要矛盾,大數(shù)據(jù)量與高并發(fā)量才是瓶頸,針對這兩個要素的設(shè)計才是核心,常見的典型“反范式”設(shè)計有:
- 字段拆分,提升性能;
- 放棄外鍵,減少JOIN,提升性能;
畫外音:數(shù)據(jù)庫范式設(shè)計,大量依賴JOIN。
- 最終一致性,提升性能;
- 放棄事務,犧牲一致性與完整性,提升性能;
- 異步更新,犧牲一致性,提升性能;
- 數(shù)據(jù)冗余,犧牲一致性,提升性能;
- ...
特別是數(shù)據(jù)冗余,在大數(shù)據(jù)量與高并發(fā)量的數(shù)據(jù)庫設(shè)計中使用極其廣泛,今天重點講講冗余表的設(shè)計。
為什么會需要冗余表?
數(shù)據(jù)量很大的時候,數(shù)據(jù)庫往往要進行水平切分,水平切分會有一個patition key,通過patition key的查詢能夠直接定位到庫,但是非patition key上的查詢可能就需要掃描多個庫了。
例如訂單表,業(yè)務上對用戶和商家都有訂單查詢需求:
- Order(oid, info_detail)
- T(buyer_id, seller_id, oid)
如果用buyer_id來分庫,seller_id的查詢就需要掃描多庫;如果用seller_id來分庫,buyer_id的查詢就需要掃描多庫。
這類業(yè)務“高吞吐量低延時”的查詢需求,往往是通過“數(shù)據(jù)冗余”的方式來滿足的,就是所謂的“冗余表”:
- T1(buyer_id, seller_id, oid)
- T2(seller_id, buyer_id, oid)
同一個數(shù)據(jù),冗余兩份,一份以buyer_id來分庫,滿足買家的查詢需求;一份以seller_id來分庫,滿足賣家的查詢需求。
冗余表如何實現(xiàn)?
常見的方案有三種。
方案一:服務同步寫法。

顧名思義,由服務層同步寫冗余數(shù)據(jù):
- 業(yè)務方調(diào)用服務,新增數(shù)據(jù);
- 服務先插入T1數(shù)據(jù);
- 服務再插入T2數(shù)據(jù);
- 服務返回業(yè)務方新增數(shù)據(jù)成功;
優(yōu)點:
- 不復雜,服務層由單次寫,變兩次寫;
- 雙寫成功才返回,數(shù)據(jù)一致性相對較高;
缺點:
- 要插入兩次,請求的處理時間增加;
- 數(shù)據(jù)仍可能不一致,寫入T1完成后服務重啟,則數(shù)據(jù)不會寫入T2;
如果系統(tǒng)對處理時間比較敏感,引出常用的第二種方案。
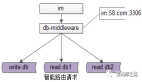
方案二:服務異步寫法。

數(shù)據(jù)的雙寫并不再由服務來完成,服務層異步發(fā)出一個消息,通過MQ發(fā)送給一個專門的數(shù)據(jù)復制服務來寫入冗余數(shù)據(jù),如上圖1-6流程:
1....
2.服務先插入T1數(shù)據(jù);
3.服務向MQ發(fā)送一個異步消息;
...
6. 異步插入T2數(shù)據(jù);
優(yōu)點:服務只插入1次,請求處理時間短。
缺點:
- 系統(tǒng)的復雜性增加了,多引入了兩個新組件,MQ與異步服務;
- 業(yè)務線返回成功時,數(shù)據(jù)還不一定異步插入到T2中,因此數(shù)據(jù)有一個不一致時間窗口,這個窗口很短,最終是一致的;
- 在消息總線丟失消息時,冗余表數(shù)據(jù)仍可能不一致;
如果想解除“數(shù)據(jù)冗余”對系統(tǒng)的耦合,引出常用的第三種方案。
方案三:線下異步寫法。

數(shù)據(jù)的雙寫不再由服務層來完成,而是由線下的一個服務或者任務來完成,最常見的,就是利用DTS這類異步數(shù)據(jù)同步服務,完成數(shù)據(jù)的冗余。
優(yōu)點:
- 數(shù)據(jù)雙寫與業(yè)務完全解耦;
- 服務只插入1次,請求處理時間短;
缺點:
- 業(yè)務線返回成功時,數(shù)據(jù)還不一定異步插入到T2中,因此數(shù)據(jù)有一個不一致時間窗口,這個窗口很短,最終是一致的;
- 數(shù)據(jù)的一致性依賴于線下服務或者任務的可靠性;
可以看到,由于冗余表的插入不具備事務性,不管哪一種方案,都有可能出現(xiàn)T1插入成功,T2插入失敗的情況,從而喪失“最終一致性”特性,那怎么辦呢?
如何保證冗余表數(shù)據(jù)的最終一致性?
常見的有四種方案。
方案一:線下定期掃描正反冗余表全部數(shù)據(jù)。

如上圖所示,線下啟動一個離線的掃描工具,不停地比對正表T1和反表T2,如果發(fā)現(xiàn)數(shù)據(jù)不一致,就進行補償修復。
優(yōu)點:
- 比較簡單,開發(fā)代價小;
- 線上服務無需修改,修復工具與線上服務解耦;
缺點:
- 掃描效率低,會掃描大量的“已經(jīng)能夠保證一致”的數(shù)據(jù);
- 由于掃描的數(shù)據(jù)量大,掃描一輪的時間比較長,即數(shù)據(jù)如果不一致,不一致的時間窗口比較長;
優(yōu)化思路:定期掃描全量數(shù)據(jù)太低效,有沒有一種只掃描“可能存在不一致可能性”的增量數(shù)據(jù),以提高效率的優(yōu)化方法呢?
方法二:線下掃描增量數(shù)據(jù)。

每次只掃描增量的日志數(shù)據(jù),就能夠極大提高效率,縮短數(shù)據(jù)不一致的時間窗口,如上圖1-4流程所示:
1. 寫入正表T1;
2. 寫入日志log1;
3. 寫入反表T2;
4. 寫入日志log2;
然后通過一個離線的掃描工具,不停的比對日志log1和日志log2,如果發(fā)現(xiàn)數(shù)據(jù)不一致,就進行補償修復。
優(yōu)點:
- 比較簡單,開發(fā)代價小;
- 數(shù)據(jù)掃描效率高,只掃描增量數(shù)據(jù);
缺點:
- 線上服務略有修改,但代價不高,多寫了2條日志;
- 雖然比方法一更實時,但時效性還是不高,不一致窗口取決于掃描的周期;
優(yōu)化思路:有沒有實時檢測一致性并進行修復的方法呢?
方法三:實時線上“消息對”檢測。

這次不是寫日志了,而是向消息總線發(fā)送消息,如上圖1-4流程所示:
1. 寫入正表T1;
2. 發(fā)送消息msg1;
3. 寫入反表T2;
4. 發(fā)送消息msg2;
正常情況下,msg1和msg2的接收時間應該在N秒以內(nèi),如不然,則進行補償修復。
優(yōu)點:效率高,實時性高。
缺點:相對復雜。
方案四:人工修復法。
項目上線時間太緊,沒時間搞一致性設(shè)計哇!
雖然插入不是原子的,奈何出現(xiàn)的概率低啊!
即使出現(xiàn)了,用戶也不一定能發(fā)現(xiàn)呀!
用戶發(fā)現(xiàn)了,找客服也不是找我呀!
找我,一個DBA工單就修復啦!
于是,大量的公司,不考慮正表和反表的數(shù)據(jù)一致性,事后發(fā)現(xiàn),事后人工修復。
總結(jié)
(1) 數(shù)據(jù)庫范式設(shè)計,是為減少數(shù)據(jù)冗余,減少數(shù)據(jù)依賴,確保數(shù)據(jù)一致性與完整性而提出的;
(2) 很多互聯(lián)網(wǎng)業(yè)務場景,大數(shù)據(jù)量與高并發(fā)量才是瓶頸,故經(jīng)常采用“數(shù)據(jù)冗余”這類反范式設(shè)計;
(3) 數(shù)據(jù)冗余的常見方式有三種:
- 服務同步寫
- 服務異步寫
- 線下異步寫
(4) 修復冗余數(shù)據(jù)一致性的常見方案有四種:
- 線下定期掃全量
- 線下定期掃增量
- 線上實時“消息對”檢測
- 躺平,人工修復
知其然,知其所以然。
思路比結(jié)論更重要。