ICML 2025 | 給AI裝上「智能升級插件」!阿里安全-清華大學D-MoLE讓模型在持續學習中動態進化
本文第一作者為清華大學計算機系的碩士二年級研究生葛晨笛,研究方向為多模態大語言模型、自動機器學習和圖機器學習。主要合作者為來自阿里巴巴集團安全部的樊珈珮、黃龍濤和薛暉。通訊作者為清華大學的朱文武教授、王鑫副研究員。
近日,阿里巴巴集團安全部-交互內容安全團隊與清華大學針對持續多模態指令微調的聯合研究成果被機器學習頂級會議 ICML 2025 收錄。本屆 ICML 共收到 12,107 篇投稿,錄用率為 26.9%。

- 論文標題:Dynamic Mixture of Curriculum LoRA Experts for Continual Multimodal Instruction Tuning
- 論文地址:https://arxiv.org/abs/2506.11672
- 代碼鏈接:https://github.com/gcd19/D-MoLE
一、研究背景
多模態大語言模型(Multimodal Large Language Models, MLLMs) 通過結合視覺、語音等模態編碼器與文本生成模型,展現出處理多模態數據的強大能力。然而,在實際應用中,預訓練的 MLLM 會隨著用戶需求和任務類型的變化,不斷面臨新的適配要求。如果直接針對新任務進行微調,模型往往會出現災難性遺忘(Catastrophic Forgetting),即丟失之前掌握的能力。
因此,如何讓 MLLM 持續地適應新任務,同時保留過去的知識,成為一個核心挑戰,這一問題被稱為「持續多模態指令微調」(Continual Multimodal Instruction Tuning, CMIT)。
目前有關CMIT 的研究剛剛起步。常用的持續學習策略包括基于經驗回放(replay) 和參數正則化的方法,但這些方法最初設計是針對較小規模、單模態模型的。在多模態大模型的場景下,這些固定架構的策略面臨著兩個新出現的挑戰:
- 任務架構沖突:不同任務對模型不同層次有不同的依賴程度,統一固定的結構難以實現理想的適配效果。
為此,我們在 preliminary study 中具體量化了這一現象,發現在多模態任務的持續學習中,不同任務在模型的 Transformer 層具有明顯不同的敏感程度。以視覺任務為例,部分任務對視覺編碼器的較淺層依賴更多,而另一些任務則明顯依賴語言模型的更深層。這表明簡單的統一架構適配策略很難同時滿足所有任務的需求,易導致部分層的參數冗余而另一部分層的參數更新不足。

- 模態不均衡:不同任務對圖像、文本等不同模態的依賴程度差別較大,容易導致訓練過程中各模態更新程度的不平衡。
同樣在 preliminary study 中,我們跟蹤分析了模型在訓練不同任務時,視覺和文本模態的參數更新幅度變化,結果清晰顯示,有些任務以文本模態更新為主,而另一些則明顯偏重視覺模態更新。這種模態依賴的不均衡性導致部分模態模塊的優化不足,整體性能受到影響。

為了應對這些挑戰,本研究團隊提出了一種新的持續多模態指令微調框架D-MoLE,打破了傳統模型結構固定的思路,允許模型在參數預算受控的條件下,根據任務需求動態地調整模型架構。具體而言,D-MoLE 能夠按需在關鍵層引入額外的參數模塊(LoRA 專家),精準地緩解任務架構沖突;同時,通過引入基于梯度的持續學習課程策略,自動平衡不同模態模塊的更新比例,使得各模態能夠獲得更加均衡的優化。
二、論文摘要
持續的多模態指令微調(Continual Multimodal Instruction Tuning, CMIT) 對于多模態大語言模型(MLLM) 適應不斷變化的任務需求至關重要。然而,目前主流方法大多依賴固定的模型架構,難以靈活應對新任務,因為它們的模型容量在設計之初就被限定住了。
我們提出一種在參數預算受限條件下進行架構動態調整的方法,用于提升模型在持續學習過程中的適應能力。這個方向此前幾乎沒有被探索,但它同時帶來了兩個關鍵挑戰:其一,不同任務對模型的層級結構有不同的依賴,容易引發「架構沖突」;其二,不同任務對視覺和文本等模態的依賴強度不一,可能導致訓練過程中的「模態不均衡」。
為此,我們提出了D-MoLE(Dynamic Mixture of Curriculum LoRA Experts) 方法,在有限參數預算下實現模型架構的按需演化,從而持續適配新任務,同時保留已有知識。
具體來說,D-MoLE 包含兩個核心模塊:一個是動態按層專家分配器,用于識別當前任務最需要適配的關鍵層并分配 LoRA 專家;另一個是基于梯度的跨模態課程機制,根據當前任務對不同模態的學習難度,動態調整語言模型與模態編碼器的更新比例,從而緩解模態不均衡問題。
實驗結果表明,D-MoLE 在多個任務的持續學習評估中表現優異,在平均指標(AVG) 上相較當前最強基線提升約 15%。據我們了解,這是首個從模型架構演化的角度系統研究 MLLM 持續學習問題的工作。
三、方法解讀
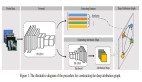
D-MoLE 框架的核心思想在于通過動態調整模型結構和學習策略,以應對持續學習中的任務架構沖突和模態不平衡問題。整體框架如論文圖 3(下圖) 所示,主要包含動態分層專家分配器和基于梯度的跨模態持續課程兩大核心組件。

動態分層專家分配器(Dynamic Layer-Wise Expert Allocator) 與常規 MoLE 的區別
常規的LoRA 專家混合(Mixture of LoRA Experts, MoLE) 方法通常是將多個 LoRA 模塊(視為「專家」) 集成到模型中,并使用一個路由機制來為不同的輸入選擇性地激活部分專家。D-MoLE 在此基礎上,針對持續學習的特性進行了關鍵創新。我們可以從其核心運作公式(即論文中的公式 2)來理解其獨特性:

該公式描述了在學習第 t 個新任務時,模型第 1 層的輸出是如何構成的。它主要包含三部分:
- 基礎知識(
 ):這是模型第
):這是模型第 層原始預訓練權重
層原始預訓練權重  對輸入
對輸入 的處理結果。它代表模型的通用能力,在持續學習中保持不變。
的處理結果。它代表模型的通用能力,在持續學習中保持不變。 - 歷史經驗的動態調用(
 ):這代表模型從過去已學習的任務(任務 1 到 t?1) 中提取的相關知識。
):這代表模型從過去已學習的任務(任務 1 到 t?1) 中提取的相關知識。
 是過去第
是過去第 個任務的 LoRA 專家(一種小型的、可訓練的適配器模塊) 在第
個任務的 LoRA 專家(一種小型的、可訓練的適配器模塊) 在第 層的輸出。
層的輸出。
 標記了過去任務
標記了過去任務 時第
時第 層是否真的分配了這樣一個 LoRA 專家。
層是否真的分配了這樣一個 LoRA 專家。
 是一個門控函數,它會判斷當前輸入
是一個門控函數,它會判斷當前輸入 與歷史任務
與歷史任務 的相關性,從而決定該歷史專家的激活程度。這意味著模型能智能地、有選擇地重用最相關的歷史經驗。
的相關性,從而決定該歷史專家的激活程度。這意味著模型能智能地、有選擇地重用最相關的歷史經驗。
- 新知識的學習
 :這部分是專門為當前新任務
:這部分是專門為當前新任務 學習的內容。
學習的內容。
 是為當前任務
是為當前任務 在第
在第 層新分配并訓練的 LoRA 專家的輸出。
層新分配并訓練的 LoRA 專家的輸出。
 標記了當前新任務
標記了當前新任務 是否在第
是否在第 層分配了新的 LoRA 專家。這個決策是動態的,基于對新任務的分析,而非預設。
層分配了新的 LoRA 專家。這個決策是動態的,基于對新任務的分析,而非預設。
核心思想:這種設計的核心在于動態和選擇性。模型不是簡單地累積所有知識,也不是為每個新任務都重新調整所有層。而是:
- 保留通用基礎:凍結大部分預訓練參數。
- 按需適配新任務:通過「零成本代理評估」(快速分析任務對各層的影響),D-MoLE 僅在對新任務最關鍵的層 (即
 的層) 動態引入新的、輕量化的 LoRA 專家進行針對性學習。
的層) 動態引入新的、輕量化的 LoRA 專家進行針對性學習。 - 情境化利用舊經驗:通過門控機制,模型可以根據當前輸入數據的特性,智能地激活那些最相關的歷史 LoRA 專家,實現有效知識遷移,同時避免不相關歷史經驗的干擾。
這種策略使得模型能夠在參數預算受控的情況下,高效地適應新任務,同時最大限度地保留和利用過往的知識。
基于梯度的跨模態持續課程(Gradient-Based Inter-Modal Continual Curriculum)
該模塊用于解決「模態不平衡」問題。在多模態學習中,不同任務對圖像、文本等不同模態的依賴程度各異。
- 核心思想:D-MoLE 不再對所有模態一視同仁。它首先通過「零成本代理評估」分別判斷整個視覺編碼器和整個語言模型對當前新任務的整體「敏感度」或「學習難度」。
- 預算動態分配:基于評估出的各模態「學習難度」,此模塊會動態地調整分配給視覺和語言部分的參數預算(即允許放置多少新的 LoRA 專家)。「學習難度」更大(即對任務更敏感、更需要調整) 的模態會獲得更多的參數預算。
- 協同工作:這個分配好的、針對不同模態的預算,會進一步指導「動態分層專家分配器」具體在哪些層、為哪個模態放置 LoRA 專家。
整體流程(簡化版)
當一個新任務到來時,D-MoLE 的工作流程大致如下:
- 快速評估:首先,模型用少量新任務的數據樣本進行一次「演練」(即零成本代理評估),快速了解這個新任務對模型哪些層、哪些模態(視覺/語言) 的挑戰比較大。
- 動態預算:基于上述評估結果,「跨模態持續課程」模塊會決定在這個新任務上,應該給視覺部分多一點「學習資源」(參數預算),還是給語言部分多一點。挑戰大的模態會分到更多預算。
- 精準部署新專家:「動態分層專家分配器」拿著各個模態分到的預算,在各自模態內部,把新的 LoRA 專家模塊(可訓練的小型網絡結構) 安裝到那些在步驟 1 中被識別為對新任務「最敏感」或「最關鍵」的層上。
- 舊知識導航:訓練一個輕量級的「導航員」(自編碼器路由),它能判斷當前新任務的輸入數據和以前哪個老任務最像。
- 針對性訓練:開始正式學習新任務。此時,模型的絕大部分原始參數和為老任務安裝的 LoRA 專家都保持「凍結」狀態,只有剛剛為新任務精準部署上的那些新 LoRA 專家才參與訓練。在訓練時,步驟 4 的「導航員」會喚醒與當前輸入最匹配的那些「舊專家」,讓它們也貢獻一部分智慧,幫助新專家學得更好更快。
- 推理應用:學習完畢后,當模型處理新的多模態輸入時,「導航員」會再次判斷輸入數據和哪個(或哪些) 任務最相關,然后激活相應的 LoRA 專家(可能是新任務的,也可能是相關的舊任務的) 來共同完成任務。
通過這一系列動態和自適應的策略,D-MoLE 旨在讓多模態大模型在持續學習新知識時,既能學得好、學得快,又能有效減少對舊知識的遺忘。
四、實驗結果
研究團隊構建了一個包含視覺問答(VQA)、圖像描述(Image Captioning) 和視覺定位(Visual Grounding) 三大類共 9 個數據集的持續多模態指令微調(CMIT) 基準。實驗采用的預訓練 MLLM 是 InternVL2-2B。評估指標主要包括:
- AVG:模型在所有任務上,在整個持續學習過程中的平均性能。
- Last:模型在學完所有任務后,在各個任務上的最終性能。
- BWT(Backward Transfer):向后遷移,衡量學習新任務后,舊任務性能的下降程度(越接近 0 越好,負值越大表示遺忘越嚴重)。

主要結果對比
如上表所示,D-MoLE 在 AVG、Last 和 BWT 三個關鍵指標上均顯著優于所有對比的基線方法。與表現次優的 O-LORA 方法相比,D-MoLE 在 AVG 指標上平均提升了約 15.08%,在 Last 指標上提升了約 20.14%,在 BWT 指標上更是將平均遺忘從 -21.31% 大幅改善至 -1.49%。這充分證明了 D-MoLE 在持續學習過程中的任務適應能力和抗遺忘能力。傳統的持續學習方法如 LwF-LORA 和 EWC-LORA,即使結合了參數高效微調技術 LoRA,在 CMIT 場景下表現不佳,遺忘嚴重。而一些基于 LoRA 專家混合(MoLE-based) 的方法(如 Dense MoLE, Sparse MoLE, MoLA) 雖有改進,但效果仍不如 D-MoLE,這凸顯了 D-MoLE 動態架構調整和課程學習策略的優越性。
通用能力評估
為了檢驗模型在持續學習后是否保持了通用多模態能力,研究團隊在三個通用的MLLM 評測基準 MME、MMMU 和 POPE 上對學完所有 9 個任務后的模型進行了評估。

結果如上表所示,與直接對每個任務進行順序微調(Seq-FT) 和 O-LORA 相比,D-MoLE 在這些通用能力測試中表現更好,更接近原始預訓練模型(Zero-Shot) 的水平。這表明 D-MoLE 在適應新任務的同時,能更好地保持模型原有的基礎能力。
消融實驗

為了驗證D-MoLE 中各個組件的有效性,研究團隊進行了一系列消融實驗:
- v1(僅微調 LLM) 和 v2(僅微調視覺編碼器):結果顯示,單單更新一個模態效果很差,說明多模態協同適應的重要性。
- v3(移除跨模態課程):性能有所下降,表明基于梯度的模態難度評估和預算動態分配是有效的。
- v4(移除動態分層專家分配器,均勻分配 LoRA):性能大幅下降,證明了根據任務敏感度動態分配 LoRA 專家到關鍵層對于緩解架構沖突和提升性能至關重要。
這些結果清晰地表明 D-MoLE 的每個精心設計的組件都對其優越性能做出了貢獻。
訓練效率

盡管D-MoLE 引入了零成本代理評估和動態分配機制,但其總訓練時間(12.40 小時) 與 vanilla LoRA 微調(Seq-FT, 13.15 小時) 相當,甚至略優,并快于其他一些復雜的持續學習方法(如 MOLA, 23.03 小時)。這是因為 D-MoLE 通過選擇性地在關鍵層插入 LoRA 模塊,而不是在所有層都插入,從而減少了實際參與訓練的參數量和反向傳播的計算量。零成本代理評估本身計算開銷很小(約占總訓練時間的 1.45%)。
五、業務應用
D-MoLE 可以用于提升阿里安全多模態審核大模型在交互內容安全場景下的持續適應能力。具體而言,模型需要同時支持多個平臺的圖文審核,而不同平臺的審核規則存在差異,且會隨著時間不斷變化。
借助 D-MoLE,模型能夠在不影響原有能力的前提下,快速適配新的平臺或規則,只需引入少量參數即可完成擴展,無需重復訓練整個模型。這有助于降低運維成本,提升模型在多任務、多平臺環境中的靈活性與長期可用性。