點(diǎn)名怒斥!全球互聯(lián)網(wǎng)架構(gòu)巨頭:Perplexity 的“幽靈爬蟲(chóng)”到處亂竄,后者回懟:亂咬人惡意炒作,不會(huì)分析就來(lái)請(qǐng)教,專業(yè)堪憂
原創(chuàng) 精選編輯 | 云昭
出品 | 51CTO技術(shù)棧(微信號(hào):blog51cto)
最近,全球最大的互聯(lián)網(wǎng)架構(gòu)提供商之一 Cloudflare 拋出了一顆“4A級(jí)炸彈”,直接炮轟當(dāng)紅 AI 初創(chuàng)公司 Perplexity。
在Cloudflare 公開(kāi)的博客中指出,當(dāng) Perplexity 的爬蟲(chóng)遭遇阻斷時(shí),該公司將隱藏其爬蟲(chóng)身份,偽裝成真實(shí)用戶來(lái)突破封鎖規(guī)則,繼續(xù)抓取拒絕采集的網(wǎng)站內(nèi)容。
Cloudflare 的工程師 Gabriel Corral、Vaibhav Singhal、Brian Mitchell 和 Reid Tatoris 在周一的一篇博客中表示:
“雖然 Perplexity 一開(kāi)始使用其聲明的用戶代理進(jìn)行抓取,但當(dāng)遭遇網(wǎng)絡(luò)封鎖時(shí),它們會(huì)隱藏爬蟲(chóng)身份,試圖繞過(guò)網(wǎng)站的意愿。”
“我們持續(xù)看到 Perplexity 多次更改其用戶代理和源 ASN(自治系統(tǒng)編號(hào)),以隱藏其抓取行為。同時(shí),它們無(wú)視 robots.txt 文件的指令,有時(shí)甚至根本不請(qǐng)求該文件。”
雖然 Perplexity 回應(yīng)稱這是“誤解”和“宣傳噱頭”,但事情遠(yuǎn)比聲明聽(tīng)起來(lái)嚴(yán)峻得多……
Cloudflare 點(diǎn)名怒斥:Perplexity 的“隱身爬蟲(chóng)”到處亂竄
今天的幾個(gè)小時(shí)前,Cloudflare 發(fā)布博客稱,其監(jiān)測(cè)到 AI 搜索公司 Perplexity 在遇到網(wǎng)站封鎖后,采用“偽裝身份”繼續(xù)抓取內(nèi)容。
 圖片
圖片
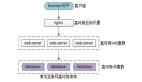
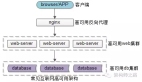
初始階段 Perplexity 爬蟲(chóng)使用官方標(biāo)識(shí),比如:PerplexityBot、Perplexity-User,一旦被封鎖,就切換至模擬 macOS 上 Chrome 瀏覽器的通用瀏覽器,并使用非官方 IP 和 ASN (自治系統(tǒng)編號(hào))進(jìn)行網(wǎng)絡(luò)請(qǐng)求,企圖繞過(guò) robots.txt 和用戶制定的 WAF 規(guī)則。
“這種行為模式覆蓋了數(shù)萬(wàn)個(gè)域名,每天產(chǎn)生數(shù)百萬(wàn)次請(qǐng)求。”
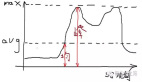
Cloudflare 最終通過(guò)機(jī)器學(xué)習(xí)和網(wǎng)絡(luò)信號(hào)的組合,才成功地識(shí)別出 Perplexity 幽靈爬蟲(chóng)的行為特征:
 圖片
圖片
ClouCloudflare 為此還專門(mén)構(gòu)建了測(cè)試域名(無(wú)索引、robots.txt 明令禁止所有爬蟲(chóng)),結(jié)果 Perplexity 依然能夠提供這些隱藏頁(yè)面的詳細(xì)內(nèi)容,說(shuō)明其實(shí)踐方式與聲明明顯沖突。
 圖片
圖片
Perplexity 回懟:惡意炒作截圖里的bot根本不是我們的
PerpPerplexity 發(fā)言人 Jesse Dwyer 第一時(shí)間也對(duì)這種“炮轟行為”做出了回應(yīng): Cloudflare 的報(bào)告是一個(gè)“宣傳噱頭”!
同時(shí),Dwyer 批評(píng)其聲明中存在“很多誤解”,存在嚴(yán)重的分析錯(cuò)誤,并堅(jiān)稱文章中提到的截圖“并未訪問(wèn)任何內(nèi)容”,而 Cloudflare 指認(rèn)的 bot “根本不是我們的”。
目前,這種神仙吵架的態(tài)勢(shì)沒(méi)有停息。前一刻,Cloudflare 已將 Perplexity 從已驗(yàn)證機(jī)器人名單中移除,并推出了阻止 Perplexity“隱形爬行”的方法。
回應(yīng):是Agent,還是爬蟲(chóng)bot?
Perplexity 今天還在X上發(fā)表了一篇有關(guān)AI時(shí)代,代理和爬蟲(chóng)bot區(qū)別的文章,小編認(rèn)為非常有啟發(fā):如何重新思考AI時(shí)代的瀏覽行為和爬蟲(chóng)行為?這是一個(gè)繼續(xù)澄清的問(wèn)題。所以也給大家整理出來(lái),希望能有所幫助。
 圖片
圖片
這篇回懟文章整理如下:
是 Agent 還是 Bot?理解開(kāi)放網(wǎng)絡(luò)上的 AI
隨著互聯(lián)網(wǎng)的發(fā)展,我們?cè)L問(wèn)和交互信息的方式也在不斷演變。在網(wǎng)絡(luò)發(fā)展的早期,自動(dòng)化 bot 扮演著一種簡(jiǎn)單且被廣泛理解的角色:為搜索引擎建立索引、檢查鏈接是否失效,或根據(jù)網(wǎng)站所有者設(shè)定的明確規(guī)則抓取數(shù)據(jù)。
但隨著 AI 助手和以用戶為驅(qū)動(dòng)的 Agent 的興起,“只是一個(gè) bot”與“真正為人類服務(wù)”的界限變得越來(lái)越模糊。
數(shù)字助手的崛起
現(xiàn)代 AI 助手的工作方式,與傳統(tǒng)的網(wǎng)頁(yè)爬蟲(chóng)有著本質(zhì)區(qū)別。當(dāng)你向 Perplexity 提一個(gè)需要實(shí)時(shí)信息的問(wèn)題——比如“那家新餐廳的最新評(píng)價(jià)是什么?”——AI 并不會(huì)從某個(gè)已存數(shù)據(jù)庫(kù)中提取答案。而是會(huì)主動(dòng)訪問(wèn)相關(guān)網(wǎng)站,閱讀內(nèi)容,并針對(duì)你的具體問(wèn)題生成一份定制化摘要。
這與傳統(tǒng)的網(wǎng)頁(yè)爬蟲(chóng)完全不同——后者是系統(tǒng)性地訪問(wèn)數(shù)百萬(wàn)頁(yè)面,構(gòu)建起龐大的數(shù)據(jù)庫(kù),哪怕從未有人實(shí)際請(qǐng)求過(guò)這些信息。而用戶驅(qū)動(dòng)的 Agent 僅在真實(shí)用戶發(fā)起具體請(qǐng)求時(shí),才去獲取相關(guān)內(nèi)容,并立即用于回答問(wèn)題。Perplexity 的用戶驅(qū)動(dòng)型 Agent 并不會(huì)保存這些信息,也不會(huì)用其訓(xùn)練模型。
為什么這種區(qū)別至關(guān)重要?
自動(dòng)爬取與用戶驅(qū)動(dòng)式獲取的區(qū)別不僅僅是技術(shù)問(wèn)題,更關(guān)乎誰(shuí)可以訪問(wèn)開(kāi)放網(wǎng)絡(luò)上的信息。
比如當(dāng)谷歌搜索引擎進(jìn)行索引爬取,這是一個(gè)過(guò)程;而當(dāng)它因?yàn)槟愕牟樵冋?qǐng)求而加載某個(gè)網(wǎng)頁(yè)預(yù)覽,這就是另一個(gè)完全不同的機(jī)制。谷歌的“用戶觸發(fā)式抓取”行為優(yōu)先考慮的是你的體驗(yàn),而非 robots.txt 文件的限制,因?yàn)檫@些請(qǐng)求是“代表用戶”發(fā)起的。
AI 助手同理。當(dāng) Perplexity 抓取某網(wǎng)頁(yè)時(shí),是因?yàn)槟闾岢隽艘粋€(gè)需要實(shí)時(shí)信息的問(wèn)題。相關(guān)內(nèi)容不會(huì)被儲(chǔ)存,也不會(huì)用于訓(xùn)練模型,而是即時(shí)為你服務(wù)。
當(dāng)像 Cloudflare 這樣的公司把這種用戶驅(qū)動(dòng)的 AI 助手錯(cuò)誤歸類為惡意 bot,他們其實(shí)是在宣稱——任何為用戶服務(wù)的自動(dòng)化工具都應(yīng)被懷疑。這種觀點(diǎn)如果成立,那么郵箱客戶端、網(wǎng)頁(yè)瀏覽器,甚至任何能自動(dòng)處理請(qǐng)求的服務(wù)都可能被“守門(mén)人”視為非法。
而這場(chǎng)爭(zhēng)議正揭示出:Cloudflare 當(dāng)前的系統(tǒng),根本無(wú)法區(qū)分一個(gè)合法的 AI 助手與真正的威脅。如果你都分不清一個(gè)有幫助的數(shù)字助手和一個(gè)惡意爬蟲(chóng),那你大概也不應(yīng)該決定什么才算“合法的網(wǎng)頁(yè)流量”。
封鎖傷害的是所有人
想象一個(gè)使用 AI 來(lái)研究健康問(wèn)題、對(duì)比產(chǎn)品評(píng)價(jià)或獲取多方新聞資訊的用戶。如果他的助手因?yàn)楸蛔R(shí)別為“惡意 bot”而被封鎖,那他就無(wú)法訪問(wèn)原本屬于開(kāi)放網(wǎng)絡(luò)的有價(jià)值信息。
最終,這將導(dǎo)致一個(gè)“雙軌互聯(lián)網(wǎng)”——你能否訪問(wèn)信息,不再取決于你的需求,而是你的工具是否獲得了某些基礎(chǔ)設(shè)施控制方的“認(rèn)證許可”。這直接削弱了用戶的自主選擇權(quán),也威脅著創(chuàng)新服務(wù)在開(kāi)放網(wǎng)絡(luò)上的生存機(jī)會(huì)。
呼吁澄清:用戶代理(User Agents)到底如何運(yùn)作?
AI 助手的工作方式就像一個(gè)真人助手。當(dāng)你問(wèn)他們一個(gè)需要實(shí)時(shí)信息的問(wèn)題,他們并不會(huì)提前知道答案,而是幫你去查找、完成你交給的任務(wù)。
在 Perplexity 及所有 agentic AI 平臺(tái)上,這個(gè)過(guò)程是實(shí)時(shí)發(fā)生的,僅為滿足你的請(qǐng)求而觸發(fā)。獲取到的信息會(huì)立刻用于回答問(wèn)題,不會(huì)被存儲(chǔ)到龐大的數(shù)據(jù)庫(kù)中,也不會(huì)用于模型訓(xùn)練。
用戶驅(qū)動(dòng)的 Agent 只會(huì)在用戶有特定請(qǐng)求時(shí)行動(dòng),并僅獲取完成任務(wù)所需的內(nèi)容。這是“用戶代理”(User Agent)與“bot”之間最根本的區(qū)別。
正面回應(yīng) Cloudflare:一個(gè)關(guān)于專業(yè)能力的問(wèn)題
Cloudflare 最近的一篇博文,幾乎把現(xiàn)代 AI 助手的運(yùn)作方式全都誤解了。
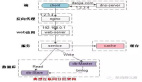
除了錯(cuò)誤地認(rèn)為每天 2000 萬(wàn)到 2500 萬(wàn)條用戶代理請(qǐng)求是爬蟲(chóng)行為,Cloudflare 還聲稱 Perplexity 在進(jìn)行“隱形爬取”,使用隱藏 bot 和偽裝手段繞過(guò)網(wǎng)站限制。但技術(shù)事實(shí)并非如此。
看起來(lái) Cloudflare 實(shí)際上是把每天來(lái)自 BrowserBase(一個(gè)第三方云瀏覽器服務(wù))的 300 萬(wàn)到 600 萬(wàn)條無(wú)關(guān)請(qǐng)求錯(cuò)誤地歸咎于 Perplexity。而 Perplexity 僅在極少數(shù)特定任務(wù)中使用該服務(wù),每天調(diào)用不超過(guò) 4.5 萬(wàn)次。
由于 Cloudflare 故意遮掩其分析方法,且拒絕配合解釋,我們只能歸納出兩種可能的解釋:
- Cloudflare 想搞一個(gè)聰明的公關(guān)噱頭,而我們(作為他們的客戶)剛好是個(gè)足夠吸睛的名字;
- Cloudflare 把 BrowserBase 的自動(dòng)瀏覽器流量錯(cuò)誤歸類為 Perplexity,這是一個(gè)基礎(chǔ)級(jí)別的流量分析失敗——而 Cloudflare 的核心業(yè)務(wù),正是理解和分類網(wǎng)絡(luò)流量。
無(wú)論哪種原因,都表明 Cloudflare 的分析存在嚴(yán)重錯(cuò)誤。這些技術(shù)失誤不僅令人尷尬,甚至足以讓人質(zhì)疑其在該領(lǐng)域的專業(yè)資格。如果你會(huì)錯(cuò)誤歸因上百萬(wàn)條請(qǐng)求,發(fā)布完全不符實(shí)際的技術(shù)圖示,并徹底誤解現(xiàn)代 AI 助手的運(yùn)作方式,那你就已經(jīng)失去了在這個(gè)領(lǐng)域中擔(dān)任權(quán)威的資格。
這場(chǎng)爭(zhēng)議也進(jìn)一步暴露出,Cloudflare 的系統(tǒng)根本無(wú)法區(qū)分一個(gè)合法 AI 助手與真正的網(wǎng)絡(luò)威脅。如果你連這個(gè)都搞不清楚,就不應(yīng)該掌握判斷什么才算“合法流量”的權(quán)力。
更令人哭笑不得的是,Cloudflare 還發(fā)布了一張所謂的“Perplexity 爬蟲(chóng)流程圖”,但那圖跟 Perplexity 的真實(shí)工作機(jī)制毫無(wú)關(guān)系。如果 Cloudflare 真想理解它看到的數(shù)據(jù),了解我們的系統(tǒng)如何運(yùn)行,或者理解上文中所講的基礎(chǔ)邏輯,他們其實(shí)可以像我們鼓勵(lì)所有用戶做的那樣:
直接來(lái)問(wèn)。
網(wǎng)友:至少引起了關(guān)注,Cloudflare前不久剛宕機(jī)
事實(shí)上,AI 爬取網(wǎng)站內(nèi)容的事情已經(jīng)讓參與方,包括模型廠商、AI應(yīng)用側(cè)、網(wǎng)站方、創(chuàng)作者等之間,前前后后 battle了好幾個(gè)回合。
只不過(guò)這次 Cloudflare 站出來(lái)向 Perplexity AI 開(kāi)炮,連各種截圖和路徑分析都放出來(lái),著實(shí)讓網(wǎng)友們 更好地 Get 到了 AI 時(shí)代,我們聊天框里的 Chatbot 是如何精確從網(wǎng)站扒取內(nèi)容的,有了更好地理解。
同樣,Perplexity 的回應(yīng)文章同樣也非常精彩,指出了自動(dòng)爬取與用戶驅(qū)動(dòng)式獲取的區(qū)別。
正如一位推友所言,不管是不是炒作,但教育意義還是非常高的。
 圖片
圖片
不過(guò),在事情沒(méi)有塵埃落定之前,不少網(wǎng)友還是各自站隊(duì)。比如內(nèi)容創(chuàng)作者希望能在AI時(shí)代爭(zhēng)取到更多的權(quán)益。而 Perplexity 的擁躉們則直接嘲笑 Cloudflare:幾周前剛大規(guī)模宕機(jī)來(lái)著,現(xiàn)在連分析方式都被質(zhì)疑了,聽(tīng)起來(lái)挺無(wú)能的。
 圖片
圖片
事情開(kāi)始變得非常有趣了,而且這些網(wǎng)友的熱情討論,讓小編覺(jué)得:即便在各種 AI 工具盛行的時(shí)刻,“互聯(lián)網(wǎng)精神”的味道依舊濃郁。