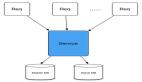
當大模型“思考”時,它在做什么?—解構 LLM 架構體系
Hello folks,我是 Luga,今天我們來聊一下人工智能應用場景 - 構建大模型應用架構技術底座:LLM 架構體系。
在人工智能技術快速演進的時代背景下,大語言模型(Large Language Models, LLMs)作為自然語言處理領域的核心架構,正逐步重塑人機交互的技術范式。從智能對話系統(tǒng)到內(nèi)容生成平臺,從復雜決策支持到跨語言信息處理,LLM 已成為現(xiàn)代人工智能基礎設施中不可或缺的組成部分。

然而,盡管其應用廣泛,LLM 背后復雜的架構設計與技術術語體系仍對許多從業(yè)者構成理解門檻。本文基于關鍵架構圖譜,從系統(tǒng)設計的角度剖析大語言模型的核心工作機制與實現(xiàn)路徑。
1. 基礎模型:架構設計的基石
基礎模型(Foundation Model)構成了大語言模型體系的結構基礎,依托海量語料進行預訓練,形成能夠理解和生成自然語言的通用架構底座。其核心架構優(yōu)勢在于極強的泛化能力——無需針對下游任務進行結構重構,即可通過微調(diào)或提示機制適應多種應用場景。
從架構演進視角來看,基礎模型實現(xiàn)了從“專用模型”到“統(tǒng)一底座”的設計范式轉(zhuǎn)型。早期自然語言處理系統(tǒng)通常為不同任務獨立設計模型結構,例如針對情感分析、實體識別或機器翻譯分別構建網(wǎng)絡。
而現(xiàn)代基礎模型,如 GPT、LLaMA 和 PaLM 等,采用統(tǒng)一的 Transformer 結構作為核心架構,通過規(guī)模擴展和訓練優(yōu)化,展現(xiàn)出卓越的任務泛化性能。這一轉(zhuǎn)變的背后,是模型架構設計、分布式訓練技術和計算硬件協(xié)同發(fā)展的共同結果。
2. Transformer:架構創(chuàng)新的里程碑
Transformer 架構被視為近年來自然語言處理領域最重要的模型設計突破。其由 Google 研究團隊于 2017 年提出,核心創(chuàng)新在于引入自注意力機制(Self-Attention Mechanism)和并行化序列處理能力,有效解決了循環(huán)神經(jīng)網(wǎng)絡(RNN)在長序列建模中的計算效率瓶頸。
自注意力機制賦予模型能夠?qū)斎胄蛄兄腥我鈨蓚€詞元之間的關系進行直接建模,顯著提升了對長程語義依賴的捕獲能力。與 RNN 的串行計算方式不同,Transformer 借助矩陣運算實現(xiàn)并行化處理,大幅提升訓練和推理效率。此外,多頭注意力(Multi-Head Attention)模塊的設計使模型能夠同時聚焦于序列的不同語義層面,如語法特征、語義角色和語用語境。
在實際架構實現(xiàn)中,Transformer 可靈活配置為編碼器-解碼器結構(如 T5、BART)或僅解碼器結構(如 GPT 系列)。后者已成為生成式語言模型的主流選擇,通過自回歸方式逐詞元地生成輸出,在保證生成質(zhì)量的同時維持了結構簡潔性。
3. Prompting 設計:架構接口的人機交互維度
提示(Prompting)構成用戶與 LLM 架構之間的核心交互接口。合理的提示設計能夠有效引導模型生成符合預期的輸出,反之則可能導致結果偏差或性能下降。提示工程因而成為 LLM 應用架構中的關鍵設計環(huán)節(jié)。
零樣本學習(Zero-Shot Learning)代表最基本的提示模式,僅通過任務描述激活模型能力,無需提供示例。例如,“將以下句子翻譯為中文:‘The architecture of LLMs is evolving rapidly.’” 這種方式完全依賴模型在預訓練階段獲得的知識先驗,適用于結構清晰、定義明確的任務。
少樣本學習(Few-Shot Learning)通過在輸入中嵌入少量示例,顯式地示意任務格式與語義要求。例如在文本分類任務中提供多條標注樣本后再提出新查詢。該方式通過示例激活模型的上下文學習能力,特別適用于定義模糊或結構復雜的任務場景。
從架構設計角度看,有效的提示構建需綜合考慮指令清晰度、示例代表性、偏差控制和輸出結構約束。近年來,更高級的提示技術如思維鏈(Chain-of-Thought)提示已顯示出在復雜推理任務上的顯著優(yōu)勢,其通過要求模型顯式生成推理步驟,提升了解題準確性與可解釋性。
4. Context-Length:架構中的記憶管理機制
上下文長度(Context-Length)定義了模型在一次前向計算中所能處理的最大詞元數(shù)量,是架構設計中的關鍵約束參數(shù)。它直接影響模型處理長文檔、維持對話一致性和執(zhí)行復雜推理的能力上限。
有限的上下文長度可能導致信息截斷,尤其在長文本摘要、代碼生成或多輪對話等場景中,模型可能無法訪問全部相關上下文,進而影響輸出質(zhì)量與一致性。另一方面,更大的上下文窗口通常意味著更高的計算復雜度和內(nèi)存占用,因自注意力機制的計算開銷隨序列長度呈平方級增長。
近年來,模型架構在長上下文支持方面取得顯著進展,例如通過稀疏注意力、層次化注意力或外推技術,在可控的計算開銷內(nèi)將上下文長度擴展至數(shù)萬甚至數(shù)十萬詞元(如 Claude 2.1 和 GPT-4 Turbo)。這些創(chuàng)新極大拓展了模型在長文檔處理、知識密集任務中的應用潛力。
5. RAG 與知識庫:架構中的外部知識集成
檢索增強生成(Retrieval-Augmented Generation, RAG)是一種將參數(shù)化模型與非參數(shù)化知識庫相結合的混合架構。該設計旨在緩解 LLM 固有的知識滯后性和幻覺傾向,通過引入外部知識提升生成內(nèi)容的準確性與可靠性。
RAG 架構通常分為兩個核心組件:檢索子系統(tǒng)與生成子系統(tǒng)。檢索組件根據(jù)用戶查詢從知識庫(Knowledge Base)中查找相關信息片段,生成組件則將這些信息作為附加上下文與查詢一并處理,產(chǎn)生最終輸出。該機制不僅增強了模型的事實準確性,還支持對訓練時未見過的領域知識或?qū)崟r信息的利用。
知識庫通常由領域文檔集構成,經(jīng)由文本嵌入模型轉(zhuǎn)換為向量表示后存儲于向量數(shù)據(jù)庫(Vector Database)中。該類數(shù)據(jù)庫采用近似最近鄰(ANN)搜索算法(如 HNSW、IVF-PQ),實現(xiàn)高效相似性檢索。向量檢索與語義生成的結合,構建起更加可靠、可追溯的生成式系統(tǒng)——用戶既可獲取答案,也可查驗其來源依據(jù)。
6. 微調(diào)與指令調(diào)優(yōu):架構的領域適配策略
盡管基礎模型具備強大的通用能力,但其在實際部署中常需根據(jù)具體任務或領域需求進行專項優(yōu)化。微調(diào)(Fine-Tuning)正是架構適配的核心技術,通過在領域數(shù)據(jù)上繼續(xù)訓練,使模型參數(shù)適應特定場景。
微調(diào)過程中,可采用全參數(shù)更新或參數(shù)高效性微調(diào)(PEFT)方法(如 LoRA、Adapter),在保持原有知識的基礎上注入領域特征。例如,醫(yī)療領域 LLM 往往需在醫(yī)學文獻和電子病歷數(shù)據(jù)上進行微調(diào),以掌握專業(yè)術語與臨床邏輯。
指令調(diào)優(yōu)(Instruction Tuning)是一種面向交互優(yōu)化的微調(diào)策略,通過訓練模型響應各式任務指令,提升其遵循用戶意圖的能力。該方法使用大量(指令,響應)配對數(shù)據(jù),強化模型對任務語義和輸出格式的理解。指令調(diào)優(yōu)顯著增強了模型的零樣本和少樣本泛化性能。
人類反饋強化學習(RLHF)進一步將人類偏好引入優(yōu)化目標,通過獎勵模型對輸出質(zhì)量進行評判,驅(qū)動模型生成更符合人類價值觀的回應。ChatGPT 等對話系統(tǒng)的成功,很大程度上得益于 RLHF 在對齊技術中的廣泛應用。
7. 幻覺問題:架構中的可靠性黑洞
幻覺(Hallucination)指模型生成內(nèi)容與輸入上下文或事實知識不一致的現(xiàn)象,是生成式架構面臨的核心可靠性問題。其表現(xiàn)形式包括事實錯誤、邏輯矛盾或完全虛構的內(nèi)容,嚴重制約了模型在高風險場景中的應用。
幻覺的產(chǎn)生源于多個架構因素:訓練數(shù)據(jù)噪聲、模型對表面統(tǒng)計模式的過度依賴、解碼策略的隨機性以及知識更新滯后等。尤其在開放域生成任務中,模型可能合成看似合理但實則錯誤的信息,對用戶形成誤導。
緩解幻覺需采取系統(tǒng)級的架構對策:包括提升訓練數(shù)據(jù)質(zhì)量、引入知識檢索機制(如 RAG)、設計約束解碼算法(如基于知識的采樣控制),以及構建輸出驗證子系統(tǒng)。此外,可解釋性技術如溯源標注和置信度顯示,也有助于用戶批判性評估模型輸出。
綜上所述,LLM 架構正處于快速演進階段,新技術與方法不斷推動系統(tǒng)性能邊界。理解其核心架構術語與設計理念,已成為從業(yè)者有效運用和貢獻這一領域的基本要求。
從基礎模型的結構統(tǒng)一化,到 Transformer 的并行化設計,從提示工程的人機交互優(yōu)化,到 RAG 系統(tǒng)的知識集成,每一環(huán)節(jié)均體現(xiàn)出現(xiàn)代 LLM 架構的多層次、模塊化設計思想。未來發(fā)展方向可能包括更高效的長序列處理機制、更靈活的知識集成接口、更可靠的生成控制策略,以及面向多模態(tài)能力的架構擴展。
隨著模型架構與工程實踐的持續(xù)融合,LLM 將不僅作為文本處理工具,更將成為支持復雜認知任務的基礎設施。無論從技術實現(xiàn)還是應用創(chuàng)新角度,對 LLM 架構的深入理解都將為我們在智能時代構建可靠、高效、人性化的人工智能系統(tǒng)提供關鍵支撐。
Happy Coding ~
Reference :
- https://arxiv.org/abs/2108.07258/
- https://huggingface.co/
Adiós !