超越ZIP的無損壓縮來了!華盛頓大學讓大模型成為無損文本壓縮器
當大語言模型生成海量數據時,數據存儲的難題也隨之而來。
對此,華盛頓大學(UW)SyFI實驗室的研究者們提出了一個創新的解決方案:LLMc,即利用大型語言模型自身進行無損文本壓縮的引擎。
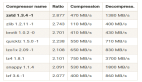
基準測試結果表明,無論是在維基百科、小說文本還是科學摘要等多種數據集上,LLMc的壓縮率都優于傳統的壓縮工具(如ZIP和LZMA)。同時,與其他以LLM為基礎的閉源壓縮系統相比,LLMc也表現出同等甚至更優的性能。

值得一提的是,該項目已經開源,主要作者是來自上海交通大學ACM班的本科生Yi Pan,目前正在華盛頓大學實習。
LLMc的壓縮機制
LLMc的靈感來源于實驗室一年前的一次內部討論。當時,研究者們面臨一個核心挑戰:LLM推理中涉及的內核操作具有高度的非確定性,這使得精確、可復現的壓縮和解壓變得困難。
但隨著業界在確定性LLM推理方面取得突破,這一問題迎刃而解,也為新引擎的誕生鋪平了道路。研究團隊順勢快速構建了LLMc的原型,并成功證明用LLM進行高效壓縮的可行性。
LLM與數據壓縮之間的聯系根植于信息論的基本原理。
香農的信源編碼定理(source coding theorem)指出,一個符號的最優編碼長度與其負對數似然(negative log-likelihood)成正比。簡而言之,一個事件的概率越高,編碼它所需的信息量就越少。
由于LLM的核心任務是預測下一個詞元(token),一個優秀的LLM能夠為真實序列中的下一個詞元賦予極高的概率。
這意味著,LLM本質上就是一個強大的概率預測引擎,而這正是實現高效壓縮的關鍵。LLMc正是利用了這一原理,將自然語言的高維分布轉換為結構化的概率信息,從而實現前所未有的壓縮效果。

LLMc的核心思想是一種名為“基于排序的編碼”(rank-based encoding)的巧妙方法。
在壓縮過程中,LLM會根據當前上下文預測下一個可能出現的詞元,并生成一個完整的概率分布列表。在大多數情況下,真實出現的那個詞元總是在這個預測列表的前幾位。
LLMc并不直接存儲詞元本身(例如其ID),而是存儲該詞元在概率排序列表中的“排名”(rank)。這些排名通常是非常小的整數,因此占用的存儲空間極小。
在解壓時,系統使用完全相同的LLM和上下文來重現當時的概率分布。然后,它只需讀取之前存儲的“排名”,就能準確地從列表中選擇對應的詞元,從而無損地恢復原始文本。
在這個過程中,LLM本身就像一個壓縮器和解壓器之間共享的、容量巨大的“密碼本”或參考系統。
挑戰與局限性
盡管LLMc取得了突破性的成果,但研究團隊也指出了當前版本存在的一些挑戰和局限性。
效率問題:LLM推理的計算復雜度與序列長度成二次方關系,且長序列推理受到內存帶寬的限制。為了緩解這一問題,LLMc采用了分塊處理文本的策略,以提高GPU利用率并降低計算開銷。
吞吐量:由于嚴重依賴大規模模型推理,LLMc目前的處理速度遠低于傳統壓縮算法。
數值穩定性:為了保證解壓過程的確定性,系統需要使用特殊的內核(batch_invariant_ops),并對詞元排名進行整數編碼,而非直接使用對數概率。
應用范圍:當前實現主要針對自然語言。如何將其擴展到圖像、視頻或二進制數據等其他模態,是未來值得探索的方向。