搞不定異地多活?一文看懂數據同步核心方案,從青銅到王者!
在構建分布式的異地多活時候,數據同步無疑是最難的問題之一。傳統的數據同步方案,如簡單的數據庫主從復制,在異地多活場景下顯得力不從心,延遲、數據沖突、網絡分區等問題層出不窮。
今天,我們就來深入剖析異地多活架構下的數據同步方案,讓你徹底告別數據同步焦慮!
數據同步方案的核心挑戰
在異地多活架構中,數據同步的核心目標是在保證數據最終一致性的前提下,盡可能降低延遲,并能優雅地處理網絡分區和數據沖突。這不僅僅是技術選型,更是一場關于性能、成本和一致性的極致權衡。
數據同步方案的設計,本質上是在回答三個問題:同步什么數據?何時同步?如何同步? 不同的業務場景,對這三個問題的回答截然不同,也因此催生了多種多樣的同步方案。
1. 基于數據庫的同步方案
這是最經典、最直接的方案,利用數據庫自身或第三方工具提供的能力進行數據復制。讓數據在不同機房之間保持一致。
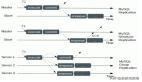
a. 主從復制 (Master-Slave Replication)
這是最基礎的模式,一個主庫(Master)負責所有寫操作,并將數據變更日志(如MySQL的Binlog)異步或半同步地傳輸給多個從庫(Slave)。
?流程圖:

- 優點:架構簡單,部署方便,成熟穩定。
- 缺點:寫操作存在單點瓶頸,主庫宕機將導致整個集群無法寫入。在異地場景下,跨地域的復制延遲會非常明顯,容易讀到舊數據。
注意:在異地多活架構中,單純的主從復制幾乎不可用。 因為它無法實現多點寫入,一旦主庫所在的數據中心發生故障,業務將直接中斷,這與多活的目標背道而馳。
b. 多主復制 (Multi-Master Replication)
為了解決單點寫入問題,多主復制應運而生。它允許多個數據中心都部署可寫入的主庫,每個主庫都能處理寫請求,并通過某種機制在多個主庫之間同步數據。
?流程圖:

?優點:實現了多點寫入,單個數據中心故障不影響其他中心的寫入能力。
?缺點:最大的噩夢是“沖突”。如果兩個數據中心的用戶同時修改了同一條記錄,聽誰的?解決沖突的邏輯非常復雜,常見的策略有“時間戳優先”、“按數據中心權重”等,但沒有一種是完美的。
注意:多主復制對數據庫中間件或數據庫本身的能力要求極高。 比如MySQL的Galera Cluster可以實現多主同步,但通常建議在局域網內使用,跨地域的廣域網延遲會急劇放大它的“腦裂”風險和性能問題。
2. 基于消息隊列 (MQ) 的同步方案
如果說數據庫同步是“硬碰硬”的剛性同步,那么基于MQ的方案則是一種柔性、解耦的異步同步。它將數據變更作為“消息”,通過MQ這個中間件系統投遞到其他數據中心。
?流程:

- 捕獲變更:業務系統在完成本地數據庫寫入后,或者通過Canal等工具監聽數據庫的Binlog,將數據變更(如訂單創建、狀態更新)封裝成消息。
- 投遞消息:將消息發送到MQ集群。
- 跨地域復制:MQ集群自身具備跨地域復制能力(如Kafka的MirrorMaker,RocketMQ的Dledger多副本),將消息同步到異地的數據中心。
- 消費數據:異地數據中心的消費者服務從MQ中拉取消息,并將其寫入本地數據庫。
流程圖:

優點:
?業務解耦:數據同步的邏輯從核心業務中剝離,降低了系統復雜度。
?削峰填谷:MQ能夠緩沖瞬時的高并發寫入,保護下游系統。
?天然異步:非常適合對延遲不那么敏感,但要求最終一致性的場景。
缺點:
?延遲較高:整個鏈路(生產->MQ復制->消費->寫入)比數據庫同步要長。
?一致性保證:需要處理消息的可靠投遞、冪等消費等問題,否則容易出現數據丟失或重復。
注意:MQ方案的核心在于保證消息的順序性和可靠性。 對于像訂單狀態流轉這類嚴格依賴順序的業務,必須保證消息按主鍵(如訂單ID)有序。Kafka的分區(Partition)和RocketMQ的消息組(Message Group)就是為此設計的。
3. 基于分布式數據存儲的同步方案
這類方案直接采用天生為分布式而生的存儲系統,如TiDB、CockroachDB等NewSQL數據庫,或者使用CRDT(無沖突復制數據類型)理論。它們在設計之初就考慮了跨地域部署和數據同步問題。
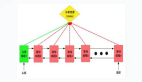
a. NewSQL數據庫
以TiDB為例,它采用Raft一致性協議。Raft協議通過選舉一個Leader節點來處理寫請求,并將日志復制到多個Follower節點,只有當大多數節點確認后,寫操作才算成功。
Raft工作簡圖:

在異地多活部署時,可以將Raft Group的成員分散在不同數據中心。
?優點:將數據同步的復雜性下沉到存儲層,對業務層透明。提供了金融級的強一致性保證,且具備水平擴展能力。
?缺點:部署和運維復雜度較高,對技術團隊要求高。相比傳統單機數據庫,在同城網絡下性能可能有一定損耗。
注意:使用NewSQL時,必須仔細規劃數據中心和副本的布局。 為了在保證高可用的同時優化性能,通常會將Leader和兩個Follower部署在同城或網絡延遲極低的主備中心,另外兩個Follower部署在異地中心,作為災備和異地讀節點。這是一種典型的“三地五中心”部署模式。
b. CRDT (Conflict-free Replicated Data Type)
CRDT是一種數學上能保證合并操作滿足交換律、結合律和冪等律的數據結構。簡單來說,無論你以何種順序、多少次合并來自不同副本的更新,最終結果都是一致的,從而天然地避免了沖突。
?例子:一個基于CRDT的計數器(Counter)。
傳統計數器:A中心+1,B中心+1。如果初始值是0,A、B各自的本地值都變成1。同步時,A把1發給B,B把1發給A,最后結果是1,錯誤!
CRDT計數器:每個副本只能增加自己的計數值。A中心的計數器是{A:1, B:0},B中心是{A:0, B:1}。同步時合并兩者,最終結果是{A:1, B:1},總和為2,正確!
?優點:真正實現了多點任意寫入且無沖突,非常適合協作編輯、社交網絡點贊計數等場景。
?缺點:模型相對抽象,并非所有數據類型都能輕易地用CRDT表示。目前成熟的、通用的CRDT數據庫產品還不多。
升華一下:如何選擇合適的方案?
沒有銀彈。至于選擇哪種方案,完全取決于你的業務場景、一致性要求和成本預算。
- 讀多寫少,對延遲容忍度低的核心交易:優先考慮基于NewSQL的方案。雖然成本高,但它為業務提供了最強的保障和最簡單的開發模型。
- 寫操作頻繁,但對實時一致性要求不高:基于MQ的異步方案是最佳選擇。它性價比高,擴展性好,是互聯網應用處理海量非核心數據的首選。
- 需要多點寫入,但能通過業務規則規避沖突:可以謹慎嘗試數據庫多主復制,但必須有強大的DBA團隊和完善的沖突解決預案。
- 特定領域的協作應用:CRDT是未來的一個方向,值得關注和在小范圍嘗試。
最終,一個成熟的異地多活架構,往往是多種方案的組合體。 比如,核心交易數據(如賬戶余額)走NewSQL,普通業務數據(如用戶日志)走MQ,基礎配置數據(很少變更)走數據庫主從復制。這種分而治之、因地制宜的混合架構,才是高階架構師真正的智慧所在。