Feed-Forward 3D綜述:三維視覺如何「一步到位」
在 3D 視覺領域,如何從二維圖像快速、精準地恢復三維世界,一直是計算機視覺與計算機圖形學最核心的問題之一。從早期的 Structure-from-Motion (SfM) 到 Neural Radiance Fields (NeRF),再到 3D Gaussian Splatting (3DGS),技術的演進讓我們離實時、通用的 3D 理解越來越近。
然而,以往的方法往往依賴于每個場景的反復優化(per-scene optimization),既慢又缺乏泛化能力。在 AI 驅動的新時代,一個全新的范式正在崛起 —— Feed-Forward 3D。
這篇由 NTU、Caltech、Westlake、UCSD、Oxford、Harvard、MIT 等 12 所機構聯合撰寫的綜述論文,主要總結了過去五年(2021–2025)間涌現的數百項創新工作,首次建立了完整的 Feed-Forward 3D 方法譜系與時間線。

- 論文標題:Advances in Feed-Forward 3D Reconstruction and View Synthesis: A Survey
- 論文地址:https://arxiv.org/abs/2507.14501
- 論文主頁:https://fnzhan.com/projects/Feed-Forward-3D/


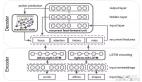
五大代表性技術分支
綜述將所有 Feed-Forward 3D 方法劃分為五類主流架構,每一類都推動了該領域的關鍵進展:
NeRF-based ModelsNeural Radiance Fields (NeRF) 提出了體積渲染的可微分框架,但其「每個場景都要優化」的缺點導致效率低下。自 PixelNeRF [CVPR ’21] 起,研究者們開始探索「條件式 NeRF」,讓網絡直接預測輻射場。這一方向發展出多個分支:
- 1D 特征方法(如 CodeNeRF、ShaRF)
- 2D 特征方法(如 GRF、IBRNet、GNT、MatchNeRF)
- 3D 特征方法(如 MVSNeRF、GeoNeRF、NeuRay)

PointMap Models
這一分支由 DUSt3R (CVPR ’24) 引領,直接在 Transformer 中預測像素對齊的 3D 點云(pointmap),無需相機姿態輸入。后續工作 MASt3R、Fast3R、CUT3R、SLAM3R、VGGT 等相繼提出更高效的多視整合、長序列記憶機制,以及大場景處理能力等。

3D Gaussian Splatting (3DGS)
3DGS 是近年來最具突破性的表示之一,將三維場景表示為高斯點云,兼顧了體積渲染的質量與光柵化的速度。然而原始 3DGS 仍需優化。Feed-Forward 研究者通過引入神經預測器,實現了「直接輸出高斯參數」的能力,主要方法包括:
- Image-based Gaussian Map:如 PixelSplat、GS-LRM、LGM、FreeSplatter,實現從單張圖像到高斯場的預測;
- Volume-based Gaussian Representation:如 LaRa、GaussianCube、QuickSplat、SCube,將場景嵌入可學習體素或三平面結構中。

Mesh / Occupancy / SDF Models
這一類方法延續了傳統幾何建模思路,并與 Transformer 與 Diffusion 模型結合:
- MeshFormer、InstantMesh、MeshGPT、MeshXL 引入可自回歸或大模型結構;
- SDF 方法(如 SparseNeuS、C2F2NeuS、UFORecon)結合體積感知與 Transformer 特征聚合,實現了高精度表面建模。
3D-Free Models
這類方法不再依賴顯式三維表示,而是直接學習從多視圖到新視角的映射。
- Regression-based:如 SRT、OSRT、RePAST、LVSM,利用深度神經網絡直接端到端擬合目標結果;
- Generative Diffusion-based:以 Zero-1-to-3、SyncDreamer、MVDream、CAT3D、CAT4D 為代表,將圖像或視頻擴散模型遷移到三維生成領域。 這些模型讓「一張圖生成整個場景」成為可能。


多樣化任務與應用場景
論文系統總結了 Feed-Forward 模型在多個方向的應用:
- Pose-Free Reconstruction & View Synthesis(PF3Plat、NoPoSplat)
- Dynamic 4D Reconstruction & Video Diffusion(MonST3R、4D-LRM、Aether)
- SLAM 與視覺定位(SLAM3R、VGGT-SLAM、Reloc3R)
- 3D-Aware 圖像與視頻生成(DiffSplat、Bolt3D)
- 數字人建模(Avat3R、GaussianHeads、GIGA)
- 機器人操作與世界模型(ManiGaussian、ManiGaussian++)
Benchmark 與評測指標
論文收錄了超過 30 個常用 3D 數據集(見第 13 頁表 1),涵蓋對象級、室內、室外、靜態與動態場景,標注模態包括 RGB、深度、LiDAR、語義與光流等。
同時總結了 PSNR / SSIM / LPIPS(圖像質量),Chamfer Distance(幾何精度),AUC / RTE / RRA(相機姿態)等標準指標體系,為未來的模型比較提供統一基線。

評測結果:
Feed-Forward 3D 的量化進展
根據 Table 2–5 的結果,本綜述對多項任務進行了系統對比:
- 相機姿態估計(Camera Pose Estimation)

- 點圖重建(Point Map Estimation)

- 視頻深度估計(Video Depth Estimation)

- 單圖新視角合成(Single-Image NVS)

未來挑戰與趨勢
論文在第 5 章提出四大開放問題:
- 多模態數據不足:RGB-only 仍占主流,缺乏統一的深度/LiDAR/語義對齊數據;
- 重建精度待提升:尚未全面超越 MVS 在細節層面的表現;
- 自由視角渲染難度高:遮擋與光照建模仍受限;
- 長上下文推理瓶頸:處理 100+ 幀序列需 40 GB 以上顯存。
未來方向包括:Diffusion Transformers 與長程注意力結構;可擴展的 4D 記憶機制;多模態大規模數據集構建(RGB + Depth + LiDAR + 語義);同時具有生成和重建能力的 Feed-Forward 模型。