每秒 30W 次的點贊業務,架構怎么優化?
作者:58沈劍
30WQPS的點贊計數業務,在數據量大,并發量大的時候,要考慮的哪些技術點呢?

繼續答星球水友提問,30WQPS的點贊計數業務,如何設計?
可以看到,這個業務的特點是:
- 吞吐量超高;
- 能夠接受一定數據不一致;
畫外音:計數有微小不準確,不是大問題。
先用最樸素的思想,只考慮點贊計數,可以怎么做?
有幾點是最容易想到的:
- 肯定不能用數據庫扛實時讀寫流量;
- redis天然支持固化,可以用高可用redis集群來做固化存儲;
- 也可以用MySQL來做固化存儲,redis做緩存,讀寫操作都落緩存,異步線程定期刷DB;
- 架一層計數服務,將計數與業務邏輯解耦;
此時MySQL核心數據結構是:
t_count(msg_id, praise_count)此時redis的KV設計也不難:
- key:msg_id
- value:praise_count

似乎很容易就搞定了:
- 服務可以水平擴展;
- 數據量增加時,數據庫可以水平擴展;
- 讀寫量增加時,緩存也可以水平擴展;
計數系統的難點,還在于業務擴展性問題,以及效率問題。
以微博為例:

- 用戶微博首頁,有多條消息list<msg_id>,這是一種擴展;
- 同一條消息msg_id,不止有點贊計數,還有閱讀計數,轉發計數,評論計數,這也是一種擴展;
假如用最樸素的方式實現,多條消息多個計數的獲取偽代碼如下:
// (1)獲取首頁所有消息msg_id
list<msg_id> = getHomePageMsg(uid);
// (2)對于首頁的所有消息要拉取多個計數
for( msg_id in list<msg_id>){
//(3.1)獲取閱讀計數
getReadCount(msg_id);
//(3.2)獲取轉發計數
getForwordCount(msg_id);
//(3.3)獲取評論計數
getCommentCount(msg_id);
//(3.4)獲取贊計數
getPraiseCount(msg_id);
}由于同一個msg_id多了幾種業務計數,redis的key需要帶上業務flag,升級為:
msg_id:read
msg_id:forword
msg_id:comment
msg_id:praise用來區分共一個msg_id的四種不同業務計數,redis不能支持key的模糊操作,必須訪問四次reids。
假設首頁有100條消息,這個方案總結為:
- for循環每一條消息,100條消息100次;
- 每條消息4次RPC獲取計數接口調用;
- 每次調用服務要訪問reids,拼裝key獲取count;
畫外音:這種方案的擴展性和效率是非常低的。
那如何進行優化呢?
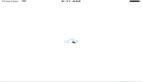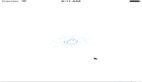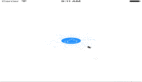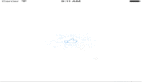
首先看下數據庫層面元數據擴展,常見的擴展方式是,增加列,記錄更多的業務計數。

如上圖所示,由一列點贊計數,擴充為四列閱讀、轉發、評論、點贊計數。
增加列這種業務計數擴展方式的缺點是:每次要擴充業務計數時,總是需要修改表結構,增加列,很煩。
有沒有不需要變更表結構的擴展方式呢?
行擴展是一種擴展性更好的方式。

表結構固化為:
t_count(msg_id, count_key, count_value)當要擴充業務計數時,增加一行就行,不需要修改表結構。
畫外音:很多配置業務,會使用這種方案,方便增加配置。
增加行這種業務計數擴展方式的缺點是:表數據行數會增加,但這不是主要矛盾,數據庫水平擴展能很輕松解決數據量大的問題。
接下來看下redis批量獲取計數的優化方案。

原始方案,通過拼裝key來區分同一個msg_id的不同業務計數。
可以升級為,同一個value來存儲多個計數。

如上圖所示,同一個msg_id的四個計數,存儲在一個value里,從而避免多次redis訪問。
畫外音:通過value來擴展,是不是很巧妙?
總結
計數業務,在數據量大,并發量大的時候,要考慮的一些技術點:
- 用緩存扛讀寫;
- 服務化,計數系統與業務系統解耦;
- 水平切分擴展吞吐量、數據量、讀寫量;
- 要考慮擴展性,數據庫層面常見的優化有:列擴展,行擴展兩種方式;
- 要考慮批量操作,緩存層面常見的優化有:一個value存儲多個業務計數;
計數系統架構優化,你學廢了嗎?
知其然,知其所以然。
思路比結論更重要。
責任編輯:趙寧寧
來源:
架構師之路