首個完整開源的生成式推薦框架MiniOneRec,輕量復(fù)現(xiàn)工業(yè)級OneRec!
中科大 LDS 實驗室何向南、王翔團(tuán)隊與 Alpha Lab 張岸團(tuán)隊聯(lián)合開源 MiniOneRec,推出生成式推薦首個完整的端到端開源框架,不僅在開源場景驗證了生成式推薦 Scaling Law,還可輕量復(fù)現(xiàn)「OneRec」,為社區(qū)提供一站式的生成式推薦訓(xùn)練與研究平臺。
近年來,在推薦系統(tǒng)領(lǐng)域,傳統(tǒng) “召回 + 排序” 級聯(lián)式架構(gòu)的收益正逐漸觸頂,而 ChatGPT 等大語言模型則展現(xiàn)了強大的涌現(xiàn)能力和符合 Scaling Law 的巨大潛力 —— 這股變革性的力量使 “生成式推薦” 成為當(dāng)下最熱門的話題之一。不同于判別式模型孤立地計算用戶喜歡某件物品的概率,“生成式推薦” 能夠利用層次化語義 ID 表示用戶歷史行為序列,并基于生成式模型結(jié)構(gòu)直接生成用戶下一批可能交互的物品列表。這種推薦模式顯著提升了模型的智能上限,并為推薦場景引入 Scaling Law 的可能性。
快手 OneRec 的成功落地,更是徹底引爆了推薦圈子。憑借端到端的推薦大模型,重構(gòu)現(xiàn)今的推薦系統(tǒng)不再是空談,它已證明是一場資源可控、能帶來真實線上收益的推薦革命。
然而,對于這一可能革新整個推薦系統(tǒng)的新范式,各大廠卻諱莫如深,核心技術(shù)細(xì)節(jié)與公開表現(xiàn)鮮有披露。開源社區(qū)與一線大廠的探索似乎正在脫鉤,技術(shù)鴻溝日漸明顯。
如何破局?
近日,中國科學(xué)技術(shù)大學(xué) LDS 實驗室何向南、王翔團(tuán)隊聯(lián)合 Alpha Lab 張岸團(tuán)隊正式發(fā)布 MiniOneRec。這一框架作為生成式推薦領(lǐng)域首個完整開源方案,為社區(qū)提供了全鏈路、一站式、端到端的訓(xùn)練與研究平臺。

- 論文標(biāo)題:MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation
- 論文鏈接:https://arxiv.org/abs/2510.24431
- 代碼鏈接:https://github.com/AkaliKong/MiniOneRec
- Huggingface 鏈接: https://huggingface.co/kkknight/MiniOneRec
核心貢獻(xiàn):
- 端到端流程支持:從 SID 生成、 模型監(jiān)督微調(diào)、 推薦驅(qū)動的強化學(xué)習(xí),全鏈路打通。
- 開源場景 Scaling Law 驗證:首次在開源數(shù)據(jù)與模型上,驗證了生成式推薦的 Scaling Law。
- 優(yōu)化后訓(xùn)練框架:提供一套輕量、完整的后訓(xùn)練框架,并引入多項針對推薦任務(wù)的改進(jìn)。
自 10 月 28 日發(fā)布以來,MiniOneRec 就廣受推薦社區(qū)關(guān)注。其代碼、數(shù)據(jù)集、模型權(quán)重已全部開源,僅需 4-8 卡 A100 同級算力即可輕松復(fù)現(xiàn)。
1. 首次公開數(shù)據(jù)集驗證生成式推薦 Scaling Law
研究人員首次在公共數(shù)據(jù)集上,驗證了生成式推薦模型的 Scaling Law。

圖 1. 模型參數(shù)從 0.5B 到 7B 的訓(xùn)練 Loss 變化。
團(tuán)隊在 Amazon Review 公開數(shù)據(jù)上,以統(tǒng)一的設(shè)置訓(xùn)練了從 0.5B 到 7B 的 MiniOneRec 版本。結(jié)果驚艷:隨著模型規(guī)模(訓(xùn)練 FLOPs)的增大,最終訓(xùn)練損失和評估損失持續(xù)下降,充分展示了生成式推薦范式在參數(shù)利用效率上的優(yōu)勢。
2. MiniOneRec 核心技術(shù)框架
該框架提供一站式的生成式推薦輕量實現(xiàn)與改進(jìn),具體包括:
(1)豐富的 SID Construction 工具箱
MiniOneRec 為開源社區(qū)提供了豐富的的 SID Construction 工具選擇,已集成 RQ-VAE, RQ-Kmeans, RQ-VAE-v2 (Google 最新工作 PLUM), 并將更新 RQ-OPQ 在內(nèi)的先進(jìn)量化算法實現(xiàn)。

下一步,團(tuán)隊正積極更新接口,以對齊業(yè)界的多模態(tài)需求。
(2)引入世界知識:全流程 SID 對齊策略
研究人員驗證了一個關(guān)鍵發(fā)現(xiàn):引入大模型世界知識,能顯著提升生成式推薦的性能。團(tuán)隊分別評測了 MiniOneRec 與其變體在不同訓(xùn)練階段的性能表現(xiàn),具體包括:
- MiniOneRec-Scratch: 基于隨機初始化的 LLM 權(quán)重訓(xùn)練,不做任何 SID - 文本對齊任務(wù)。
- MiniOneRec- W/O ALIGN: 基于預(yù)訓(xùn)練 LLM 進(jìn)行后訓(xùn)練,不做任務(wù) SID - 文本對齊。
- MiniOneRec: 基于預(yù)訓(xùn)練 LLM 進(jìn)行后訓(xùn)練,并進(jìn)行全流程的 SID 對齊。

圖 3. 世界知識對于生成式推薦性能的影響。
結(jié)果顯示,基于預(yù)訓(xùn)練 LLM 初始化并進(jìn)行語義對齊的 MiniOneRec(紅線)始終優(yōu)于未充分對齊的對應(yīng)變體(黃 / 藍(lán)線)。這表明預(yù)訓(xùn)練 LLM 已具備的通用序列處理能力和世界知識,為推薦任務(wù)帶來了顯著的額外收益。
基于此發(fā)現(xiàn),MiniOneRec 將 SID token 添加至 LLM 詞表,并在 SFT 和 RL 階段共同優(yōu)化推薦與對齊兩大任務(wù),將 LLM 語言空間與 SID 信號緊密對齊。
(3)獨家優(yōu)化:面向推薦的強化學(xué)習(xí)策略

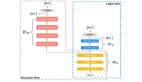
圖 4. MiniOneRec 框架。
MiniOneRec 基于 GRPO, 進(jìn)一步實現(xiàn)了面向推薦的強化學(xué)習(xí)算法,具體包括:
- 面向推薦的采樣策略
由于采取 Constrained-Decoding 策略規(guī)范模型生成合法 SID,模型的輸出被限制在遠(yuǎn)比自然語言狹窄的有限空間。隨著強化學(xué)習(xí)訓(xùn)練的深入,傳統(tǒng)采樣策略的熵迅速降低,使得模型在多次采樣時容易反復(fù)生成相同的冗余物品,導(dǎo)致優(yōu)化效率低下。基于這個發(fā)現(xiàn),MiniOneRec 替換常規(guī)采樣策略為 Constrained Beam-Search,高效生成多樣化的候選物品,兼顧采樣效率和對負(fù)樣本的曝光率。
- 面向推薦的獎勵塑造
推薦場景用戶交互稀疏,常規(guī)的二元獎勵使得負(fù)樣本 “坍縮” 為同一獎勵值,使得強化學(xué)習(xí)監(jiān)督信號粒度粗糙。MiniOneRec 在準(zhǔn)確性獎勵之外,創(chuàng)新性引入排名獎勵,對于高置信度 “困難負(fù)樣本” 施加額外懲罰,從而強化排序信號的區(qū)分度。
- 開源基準(zhǔn)測試全面領(lǐng)先
在同一 Amazon 基準(zhǔn)上,研究人員將 MiniOneRec 同當(dāng)前 SOTA 的傳統(tǒng)推薦范式、生成式推薦范式、基于大模型的推薦范式進(jìn)行了全面對比。

圖 5. MiniOneRec 同傳統(tǒng)推薦、生成式推薦、LLM 推薦性能對比。
結(jié)果顯示,MiniOneRec 展現(xiàn)出全面的領(lǐng)先優(yōu)勢:
在 HitRate@K 和 NDCG@K 兩項推薦指標(biāo)上,MiniOneRec 始終顯著優(yōu)于以往的傳統(tǒng)推薦范式與生成式推薦范式,領(lǐng)先 TIGER 約 30 個百分點。而對于基于大模型的推薦范式,MiniOnRec 呈現(xiàn)總體的領(lǐng)先的同時擁有顯著的上下文 token 優(yōu)勢。
這表明,生成式推薦作為可能的下一代推薦范式擁有顯著潛力。
3. 生成式推薦的展望與思考
生成式推薦會成為下一代推薦系統(tǒng)的新范式嗎?這個問題似乎還難以有一個定論。
一方面,以美團(tuán) MTGR、淘天 URM 等為代表的推薦系統(tǒng) “改革派”,利用生成式架構(gòu)的長序列建模等能力賦能判別式,在現(xiàn)有的體系內(nèi)基于 “生成式召回” 方案進(jìn)行增量改進(jìn)。
另一方面,以快手 OneRec 為代表的更為激進(jìn)的 “革命派”,則想要直接顛覆傳統(tǒng)多階段級聯(lián)的判別式方案、實現(xiàn)真正端到端自回歸地生成用戶興趣列表。
雖然兩條路線取舍不同,但都在規(guī)模化實踐中驗證了生成式范式的實際價值。對部分大廠而言,生成式范式已經(jīng)走出 “可行性驗證” 階段,開始在業(yè)務(wù)上創(chuàng)造真實收益。相較于業(yè)界的快速推進(jìn),學(xué)術(shù)界與開源社區(qū)在這一方向仍顯薄弱。面對這場可能重塑推薦技術(shù)版圖的機遇,我們期待更多研究者與工程實踐者大膽嘗試,擁抱這或許是推薦領(lǐng)域的 “GPT 時刻”。